具身智能若想真正走出实验室、迈向复杂多变的真实环境,仅仅依靠VLA模型“看图理解、输出动作”是远远不够的。一个更根本的挑战摆在面前:当机器人准备执行操作之前,它的目光究竟聚焦在哪里?
如果模型能够精准锁定目标物体,准确理解当前的操作阶段,并清晰掌握空间几何关系,那么其动作执行自然会更稳定可靠。然而现实情况是,在大量端到端训练的VLA模型中,动作解码器仍然像一个难以捉摸的黑箱。它可能正在关注杯子,也可能在关注背景纹理、相机伪影、光照变化,甚至只是记住了训练场景中的某个摆放习惯——一旦环境发生改变,模型就容易“找错重点”。
针对这一关键问题,复旦大学可信具身智能研究院、上海交通大学、香港大学OpenDriveLab等机构联合提出了GuidedVLA。其核心思路非常直接:不要再让动作解码器独自在黑箱中“揣摩”该看什么,而是显式地为不同的注意力头分配职责,让它们分别负责物体定位、空间几何分析和任务阶段识别。
简而言之,GuidedVLA为VLA的动作解码器制定了一张清晰的“注意力分工表”。
这样一来,机器人的动作生成不仅更加稳健,也变得更加可控和可解释——哪个注意力头负责观察物体,哪个头负责理解深度,哪个头负责判断任务进展到哪一步,都一目了然。
目前,该研究成果已被RSS 2026接收,相关代码、模型和数据集均已对外开源。

论文标题:GuidedVLA: Specifying Task-Relevant Factors via Plug-and-Play Action Attention Specialization
论文链接:https://arxiv.org/abs/2605.12369
项目主页:https://guidedvla.github.io/project_page/

GuidedVLA真机与仿真演示:研究团队将可控、可解释的注意力头专门化机制接入π0基座,在多类操作任务中验证了其卓越的泛化能力。
01 机器人失败时,它究竟看错了什么?
当前VLA模型的主流路线,是将动作作为一种特殊模态集成到视觉语言模型中。模型接收图像观测和语言指令后,直接输出机器人动作。这条技术路线效果强大且足够简洁——但它隐含了一个前提假设:动作解码器能够自主学习哪些视觉与语言特征与当前任务真正相关。
然而,现实情况往往并非如此。
论文观察到,在缺乏显式引导的情况下,VLA的动作解码器很容易过拟合伪相关特征。例如,背景纹理、偶然出现的相机伪影、环境光照噪声等,都可能会被模型当作决策的关键线索。某些交叉注意力头偶尔会看向正确区域,但这种行为具有高度随机性,会随着场景和注意力头的不同而变化。这就像一个学生偶尔能抓住题目关键词,但并未形成稳定的解题方法论。
研究团队在LIBERO-Plus布局扰动设定下,对这一现象进行了量化分析。π0基线的物体注意力正确率仅为26.5%;在技能识别方面,线性探测准确率也仅有48.4%。这组数据清晰地表明,VLA模型内部并不缺乏视觉语言知识,真正不稳定的核心环节是动作解码这一最后的优化目标。
GuidedVLA的研究问题也因此应运而生:如果动作解码器总是在隐式学习,我们能否直接告诉它应该关注什么?
02 为动作解码器绘制一张“注意力分工表”
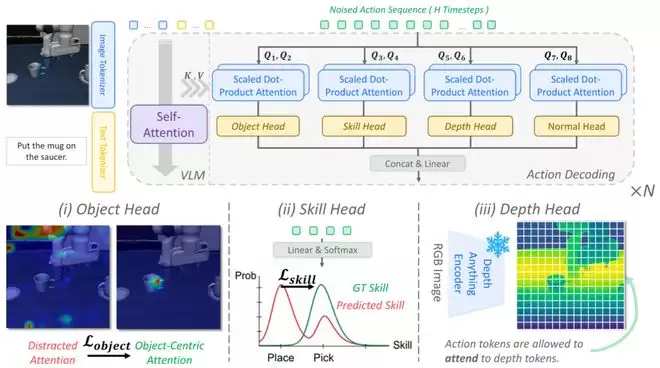
GuidedVLA的核心洞察在于,将动作解码器从一个“单体黑箱”拆解为一组功能明确的专家模块。Transformer的多头注意力机制天然包含多个注意力头。过去,这些注意力头的功能大多由端到端训练自发形成,研究者难以控制它们具体学习什么。GuidedVLA则反其道而行之:人为指定部分注意力头的任务,使用不同的辅助信号监督它们捕捉不同的任务相关因子。
这套分工体系主要包含三类注意力专家。
Object Head:负责准确锁定目标物体。它通过监督注意力图集中到任务相关的物体区域,例如要抓取的物体或要放置的位置,同时抑制干扰物和背景区域。对于杂乱桌面、小目标或透明物体这类场景,这一步尤为关键——很多时候机器人并非不会抓取,而是从一开始就没有稳定地看准目标。
Skill Head:负责感知当前所处的任务阶段。许多机器人任务并非单步操作,而是包含长程序列。例如先抓取、再移动、再放置;或者先清扫垃圾、再倒入托盘。如果模型不清楚当前处于哪个阶段,就可能出现提前跳步或在最后一步突然失败的情况。Skill Head通过技能阶段监督,让动作解码器显式感知任务进度。
Depth Head:负责理解3D几何结构。某些失败并非语义错误,而是几何估计不准。例如按铃、插入、套叠、高度对齐等操作,都需要更可靠的空间信息。Depth Head不依赖额外的损失函数监督,而是通过结构性接入一个冻结的深度编码器特征,让特定的注意力头只注意深度键/值对,从而弥补标准2D视觉编码器所缺乏的几何感知能力。
这三类注意力头分别对应机器人操作中的三个基础问题:目标是谁?当前该做什么?空间位置是否准确?这正是GuidedVLA可解释性的核心来源——它将动作决策分解为可以指定、可以观察、可以验证的注意力分工。
03 为何它能实现即插即用?
直接改造一个已经预训练好的VLA模型,很容易引发另一个问题:新的监督信号还没学好,原有的能力反而被破坏了。GuidedVLA借鉴了ControlNet式的残差适配器机制来避免这一风险。它保留原始主干注意力分支,同时新增一个因子特定的控制分支。这个控制分支通过零初始化的投影与主分支融合。由于ZeroConv在训练开始时初始化为0,控制分支在初期不会干扰原模型的行为;随着训练的推进,它再逐步将物体、技能、深度等任务相关偏置注入动作解码器。换句话说,该方法并非推倒重来,而是在π0这类基座模型上添加一个可插拔的控制层——先保证原有能力不受影响,再将需要关注的重点信息嵌入其中。
为了让这套机制具备良好的可扩展性,研究团队还设计了一套自动因子标注流水线。物体掩码由Qwen3-VL提供前景点提示,再通过SAM2在视频片段中传播掩码,最后进行人工核验;技能标签由Qwen3-VL依据预定义的技能表生成阶段标签,并转换为软目标;深度头则直接使用冻结的深度编码器特征,无需人工深度标注。效率提升非常显著:92%的操作片段无需人工修正。标注50个片段时,自动流水线大约只需4分钟,而纯人工标注则需约43.5分钟。这意味着,GuidedVLA并非以高昂的人工成本换取可解释性,而是将“显式引导”打造成一套可以规模化应用的训练接口。
04 GuidedVLA在泛化测试中能否真正看准重点、提升稳定性?
GuidedVLA真正要证明的是:这种可控、可解释的分工机制,能否在分布偏移和真实机器人场景中带来稳定的性能提升。
首先是LIBERO-Plus基准测试。该基准专门评估机器人策略在分布偏移下的鲁棒性,包含相机视角、机器人初始状态、语言变化、光照、背景、噪声和布局共7类扰动。在总分方面,π0的得分为68.2,加入Object Head后提升至73.4,加入Skill Head后为72.5,加入Depth Head后为71.7。当三类注意力头全部加入后,GuidedVLA达到了75.4分,显著超越了DreamVLA的69.9分、OpenVLA-OFT的69.6分、RIPT-VLA的68.4分等对比方法。
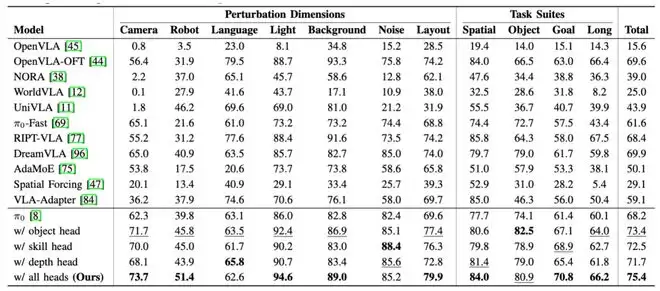
LIBERO-Plus结果表:GuidedVLA在7类扰动维度和4类任务上整体表现更为突出,三类注意力专家叠加后的平均成功率达到75.4%。
更值得关注的是,不同注意力头的优势与其职责高度吻合:Object Head在Object套件上单头效果最强,Skill Head在Goal套件上单头效果最强,Depth Head在Spatial套件上单头效果最强。这充分证明了三类注意力专家确实在各自擅长的领域发挥了关键作用。
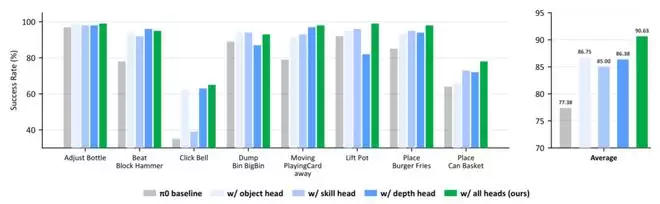
RoboTwin 2.0结果:GuidedVLA在8个随机化、未见过的操作任务中,将π0的平均成功率从77.38%提升到了90.63%。
在RoboTwin 2.0上,这种分工效果同样非常直观。Click Bell任务需要精确控制Z轴,Depth Head将成功率从35%提升到了63%;Beat Hammer Block任务需要高度对齐,成功率从78%提升至96%;Lift Pot任务涉及严格的抓取、稳定、抬起序列,Skill Head取得了单头最佳结果。一个负责看准目标,一个负责规划步骤,一个负责补充几何信息——这正是“注意力专家”体系的价值所在。
05 在真实机器人上,能否有效应对干扰物和光照变化?
真实机器人实验覆盖了两个双臂平台:ALOHA AgileX和PSI-Bot RealMan。前者包括水果蔬菜分拣、叠碗放架、清洁桌面等家庭任务;后者包括烧杯放入加热套、套叠烧杯、将烧杯放上加热装置等实验室操作任务。每个任务和模型各进行20次试验。研究团队设置了三类泛化条件:物体位置变化的域内设定、加入干扰物和杂乱场景的场景设定、以及光强/色温变化的光照设定。
实验结果显示,GuidedVLA在三类设定下均稳定优于基础策略:域内设定从55.8%提升至75.8%;场景设定从44.2%提升至67.5%;光照设定从57.5%提升至79.2%。

真机任务示例:叠碗放架。在长程操作中,Skill Head帮助模型维持清晰的阶段感,有效避免中途跳步。
真机任务示例:烧杯放入加热套。透明刚性物体和严格的几何约束,更考验目标定位与空间几何的精准度。
06 可解释性验证:因子质量越高,成功率越高
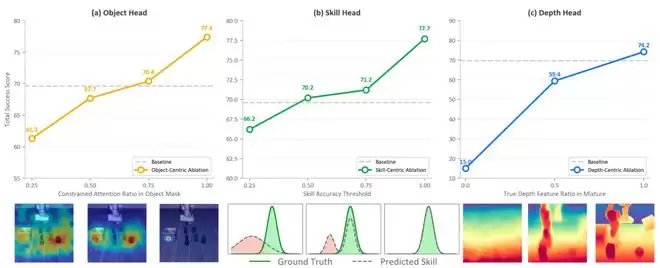
因子质量与任务成功率的关系:Object、Skill、Depth三类因子的质量越高,整体成功率也越高。
GuidedVLA进一步回答了一个更有趣的问题:这些因子的质量是否真的与任务成功率直接相关?研究团队没有仅仅进行“有无注意力头”的二元对比,而是连续调节三类因子的质量,观察成功率的相应变化。
在Object Head方面,随着落在物体区域内的注意力比例从0.25增加到1.0,成功率从61.3%提升到了77.4%。这表明动作token是否真正聚焦目标物体,会直接影响操作表现。在Skill Head方面,随着技能识别准确率的提高,成功率从66.2%提升到了77.7%。模型对当前任务阶段的理解越清晰,就越不容易在长程任务中发生跳步或乱序。在Depth Head方面,当真实深度特征比例从0增加到1.0时,成功率从15.0%大幅提升至74.2%。对于精细操作而言,明确的3D几何线索是任务能否成功的关键条件之一。
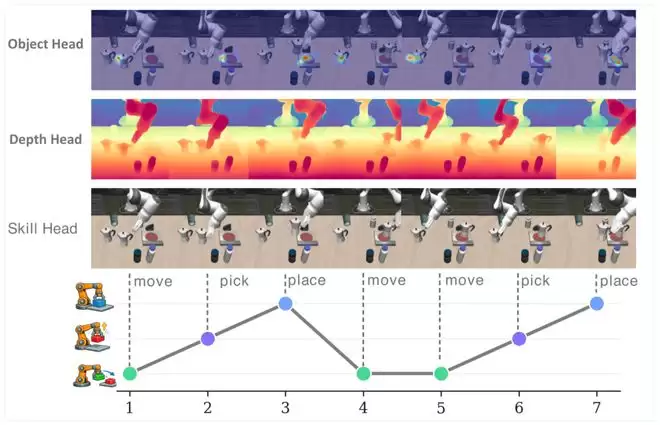
三类注意力专家的可视化结果:Object Head聚焦目标区域,Depth Head编码3D结构,Skill Head跟踪任务阶段变化。
更进一步,论文还验证了“分工”本身的重要性。一个很自然的问题是:既然物体、技能、深度信息都有用,那么能否让所有注意力头一起学习所有因子?答案是否定的。专门化的分工模式明显优于“一锅烩”式的混合训练。在空间、目标、长程任务以及总体分数上,GuidedVLA都显著领先于混合方案。当所有注意力头混合学习所有目标时,不同因子的特征会相互纠缠,导致性能反而下降。t-SNE可视化显示,在GuidedVLA中,专门化的物体、深度、技能注意力头形成了更清晰的特征分簇;而混合方案中,不同注意力头的表征则存在明显的重叠。
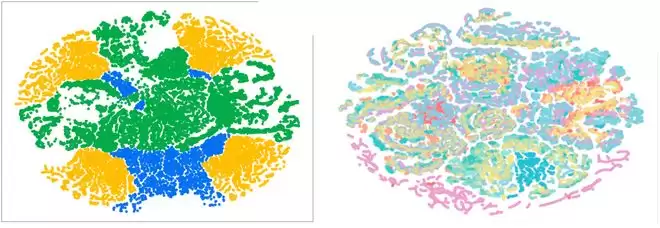
左图:GuidedVLA的专门化注意力头形成了更清晰的特征分簇;右图:混合方案中,不同注意力头的表示明显重叠,因子之间更容易相互干扰。
这说明GuidedVLA的关键不仅在于“增加了监督信号”,更在于“让不同的监督信号进入不同的专家模块”。可控性源于可指定性,可解释性源于可分工性。
总结
GuidedVLA最值得关注之处,在于它将动作解码器中最黑箱的部分,转化为一种可以被人为指定、观察和验证的结构。
过去,VLA输出一个动作后,研究者很难判断它究竟是看对了目标物体、理解了任务阶段,还是仅仅依赖于某个视觉捷径。而GuidedVLA则将这个决策过程拆解为物体、技能、深度三类注意力专家,使得动作决策呈现出更清晰的内部分工。
当然,这项工作目前仍然依赖预定义的因子。如何自动发现与任务相关的因子,尤其是在连续任务中自动识别技能结构,仍是未来需要进一步探索的方向。但它已经指明了一条非常务实的路径——让VLA模型不仅变得更强大,也要变得更可控、更可解释。让每一次操控,都有迹可循。




