图1 update语句执行流程
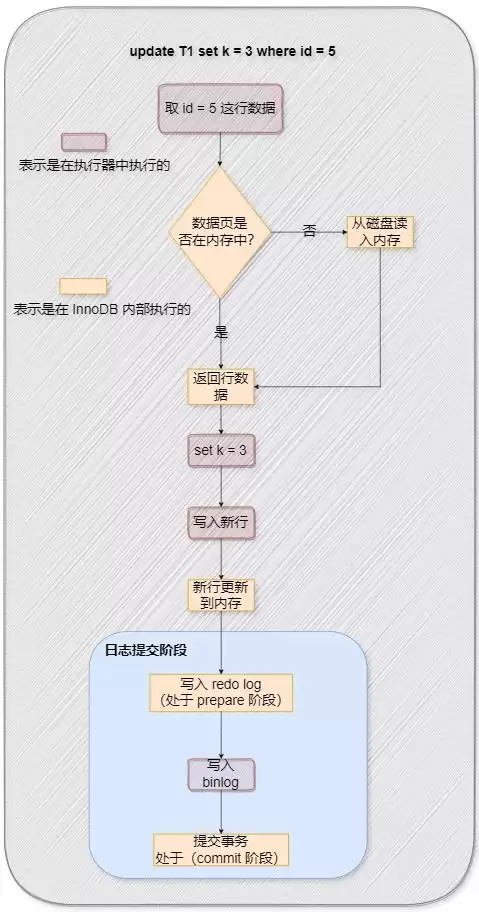
首先检查Buffer Pool中是否存在该条记录,如果不存在,则需要从磁盘加载到缓冲池,随后为该行记录添加独占锁。
接下来,将更新前的旧数据写入undo log,该日志主要用于事务回滚时的数据恢复。
然后直接在Buffer Pool内执行数据更新操作,此时该数据块会变为脏页。
执行器顺手将修改记录写入redo log,需要注意的是,此时数据仍位于内存中的redo log buffer中。
在准备提交事务的阶段(即prepare阶段),根据配置策略将redo log从内存刷盘到磁盘上的redo log文件。
接着,执行器生成该次更新对应的binlog,并同样按照策略将binlog刷写到磁盘上的binlog文件。
执行器调用存储引擎的提交事务接口,完成最终的事务提交。这一步会将当前binlog文件名以及本次更新在binlog文件中的位置一并写入redo log文件,同时在redo log中添加一个commit标记。
如果后续触发了脏页刷新操作,则会将内存中更新后的脏数据刷回至磁盘。
图2 update语句执行流程框架图
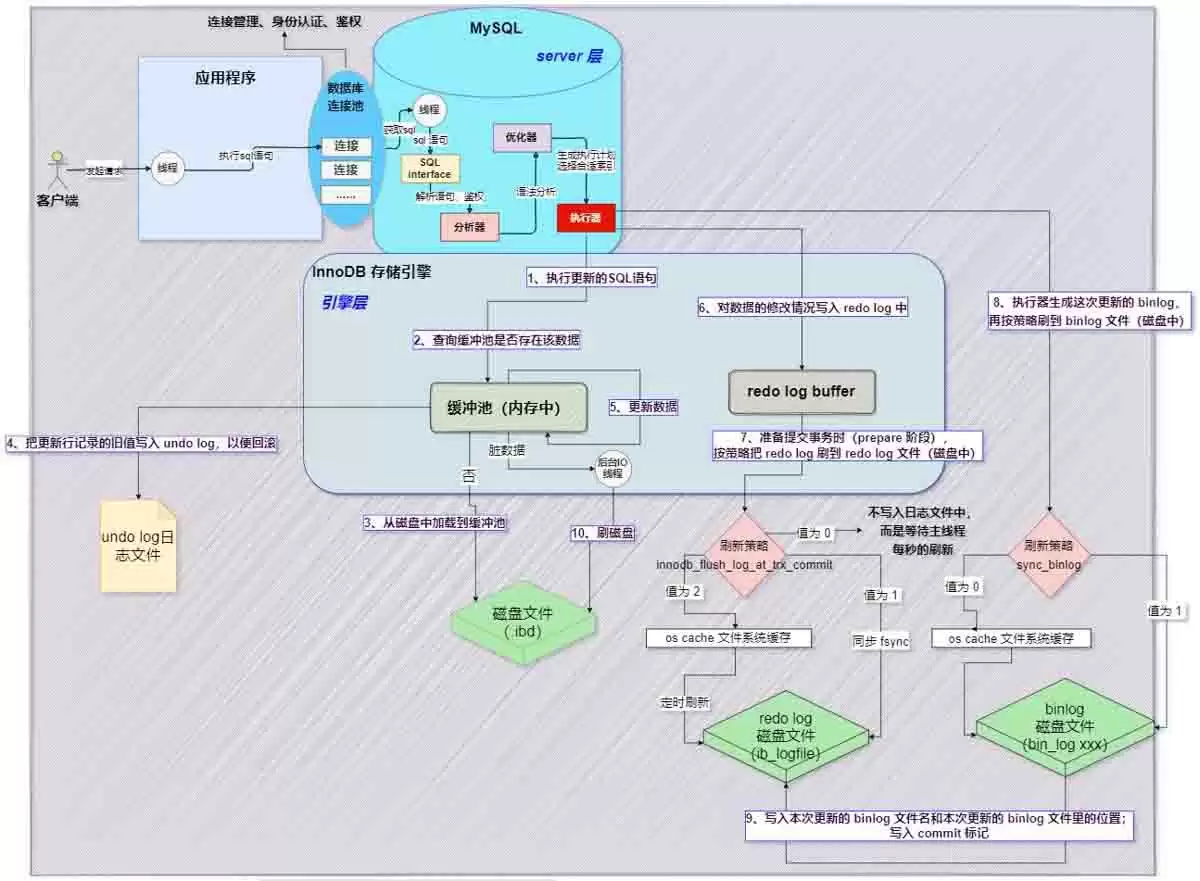
首先通过网络传输:客户端通过TCP/IP协议将SQL语句发送到Server层的SQL接口。
SQL接口接收请求后,先进行解析,同时验证用户权限是否匹配。
权限验证通过后,分析器介入,检查语句是否存在语法错误等问题。
随后优化器登场,生成相应的执行计划,并从中选择最优方案。
接着执行器按照执行计划真正执行该语句。
- 过程中需要打开表(open table),如果表上存在MDL锁,则需等待。
- 如果没有锁,则在表上添加一个短暂的MDL(S)锁。
- 如果opend_table数值过大,说明open_table_cache设置偏小,会导致频繁打开frm文件。
进入引擎层后,首先从innodb_buffer_pool的data dictionary(元数据信息)中获取表结构信息。
根据元数据信息,到lock info中检查是否存在相关锁,同时将该update语句所需的锁信息写入lock info(锁机制本身还包含许多细节)。
接着,涉及变更的老数据通过快照方式存储到innodb_buffer_pool的undo page中,并记录undo log修改对应的redo日志。如果data page中已经有数据,则直接载入undo page;否则需要从磁盘读取相应page的数据再载入。
然后在innodb_buffer_pool的data page上执行update操作。物理数据页的修改记录会被写入redo log buffer中。由于一次update事务可能涉及多个页面的修改,因此redo log buffer中会存在多条页面修改信息。同时基于group commit机制,本次事务所产生的redo log buffer可能与其他事务一起被flush并sync到磁盘。
同时,修改信息会按照event格式记录到binlog_cache中。需要注意的是,binlog_cache_size是事务级别的参数,而非会话级别。一旦提交,dump线程就会主动将binlog_cache中的event发送给从库的I/O线程。
之后,这条SQL需要在二级索引上做的修改,会被写入change buffer page,等到下次有其他SQL需要读取该二级索引时,再与二级索引进行merge操作。
(从设计角度看,这种机制将随机I/O转换为顺序I/O,不过当前主流磁盘已普遍采用SSD,因此随机I/O与顺序I/O在寻址方面的差距并不显著。)
此时update语句已经完成,需要决定是提交还是回滚。这里仅讨论提交的情况。
- 提交操作:由于存储引擎层与Server层之间采用内部XA协议(用于保证两个事务的一致性,主要是为了确保redo log和binlog的原子性),因此提交过程分为prepare阶段和commit阶段。
- prepare阶段:将事务的xid写入,并对binlog_cache执行flush和sync操作(对于大事务而言,这一步极为耗时)。
- commit阶段:由于之前该事务产生的redo log已经sync到磁盘,因此这一步只需在redo log中标记commit。
当binlog和redo log都成功落盘后,如果触发了脏页刷新操作,会先将脏页复制到doublewrite buffer中,再将doublewrite buffer的内容刷新到共享表空间,最后由page cleaner线程将脏页写入磁盘。
实际上在具体实现中,第5步调用了第6步的过程,因此本质上是同一回事。MySQL Server层和InnoDB层都各自保存了表结构,部分书籍在描述时会分开讲解。
总结
从整体来看,无论是Buffer Pool、undo log、redo log还是binlog,每一个环节紧密配合,再加上XA两阶段提交的可靠性保障,最终形成了一条完整且可靠的update执行链路。深入理解这一流程,很多MySQL故障排查和性能调优问题便有了清晰的入手方向。




