数据库运维工作看似简单,实则蕴含着不少复杂性。很多问题的答案确实可以在产品文档中找到,但更为关键的部分——往往沉淀在团队自身的实战经验中。
举个典型的场景:生产环境遇到锁等待时,究竟谁有权限执行 kill 操作?慢 SQL 出现后,是应该优先止损还是先考虑优化方案?一个大事务卡在那里,能否直接终止?业务高峰期,哪些变更操作是允许执行的?不同 MySQL 实例的巡检重点,是否应该有所区别?

关键在于能否结合团队经验作答,而非单纯会答
很多人对 AI 问答的认知,仍然停留在“问一个 MySQL 知识点”的层面:锁等待是什么、慢查询为什么出现、事务隔离级别如何理解、索引为什么会失效。这些基础知识固然重要,但在企业实际场景中,真正的挑战在于:通用知识大家都能掌握,而具体到团队自身,哪些操作可行、哪些不可行,往往才是做出正确判断的分水岭。
NineData 的解决方案是支持构建企业私有知识库,ChatDBA 在回答问题时可以引用知识库中的内容。团队可以将 MySQL 运维规范、SQL 发布规范、故障复盘记录、巡检模板、慢 SQL 处理流程、应急联系人信息以及变更窗口要求等内部资料存入知识库。启用后,ChatDBA 的回答会结合这些内部上下文,而不是仅仅提供一套通用说法。
答案可追溯,团队才更放心使用
运维知识问答最令人困扰的通常是两个问题:一是答案看起来很有道理,但无法确定依据来源;二是答案方向正确,但过于笼统,难以直接落地到团队的具体流程中。对于数据库生产环境而言,这两个问题都会直接影响团队的信任度。
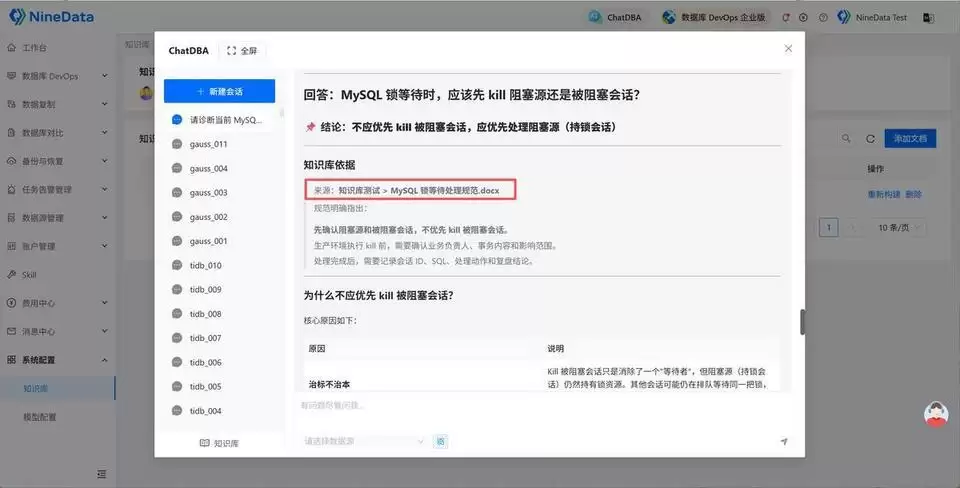
ChatDBA 在引用知识库时,会一并展示知识来源。你可以清晰地看到本次回答参考了哪些文档,从而自行判断是否符合团队规范。数据库应急处理不能仅凭一句自然语言建议就贸然行动,必须确确实实地了解建议背后的依据是什么。
举个例子,当问到“MySQL 出现锁等待时,应该先 kill 被阻塞会话还是阻塞源?”时,通用回答会先解释两者的区别。而结合知识库后,ChatDBA 还能进一步补充团队的 SOP:比如谁有权执行、执行前需要确认哪些业务信息、是否需要截图留痕,以及处理完成后如何复盘。
同一问题可以连续追问,无需每次重复背景
ChatDBA 支持多轮会话和历史上下文,这在 MySQL 排障场景中非常实用。你可以先询问当前实例是否存在锁等待,再追问阻塞源是否可以 kill,接着继续了解如果不 kill 有哪些低风险的替代方案,最后再要求生成一份复盘记录。整个排查和决策过程可以在同一个会话中逐步推进,无需每次都重新解释背景信息。
并非所有内容都适合沉淀,重点通常集中在这几类
知识库更适合承载哪些类型的内容?实践中,第一类是应急处理规范,比如锁等待、长事务、慢 SQL、连接数暴涨、主从延迟等场景的处理流程;第二类偏向开发规范,例如索引设计原则、SQL 审核规则、禁止在事务中进行长时间外部调用、批量变更的拆批要求等。
往下看,环境差异也值得沉淀:不同业务库的负责人是谁、变更窗口是什么时候、只读账号的权限范围、重要表说明以及监控指标阈值。还有历史故障的原因、当时采取的处理动作、后续的优化项,以及哪些做法后来被证明是有效的——这些经验一旦沉淀进知识库,就不再只存在于少数人的脑海中。
实际操作时,可以这样将知识库接入 ChatDBA
先说第一步:在 NineData 的知识库中上传你们的 MySQL 运维规范、SQL 发布规范以及历史故障复盘文档,并启用给 ChatDBA 使用。这一步的目标很简单,就是将团队自己的资料接入问答的上下文中。
测试时,可以先放入一批典型内容。比如 MySQL 锁等待处理规范,可以要求先确认阻塞源和被阻塞会话、生产环境执行 kill 前必须确认业务负责人和事务影响、处理完成后要记录会话 ID、SQL 和复盘结论。又比如 MySQL 长事务处理规范,则更强调先确认事务持续时间、写入量以及是否持锁,另外大事务不建议直接 kill,需要先评估回滚风险。
然后,登录 NineData 控制台,在页面上方找到并单击 ChatDBA,进入知识问答的入口。
进入 ChatDBA 后,新建一个会话。如果希望它更充分地结合上下文来回答,可以同时勾选“深度研究”选项。
接着直接在对话框里输入你的知识问答需求。比如:问 MySQL 出现锁等待时,应该先 kill 被阻塞会话还是阻塞源,以及为什么。
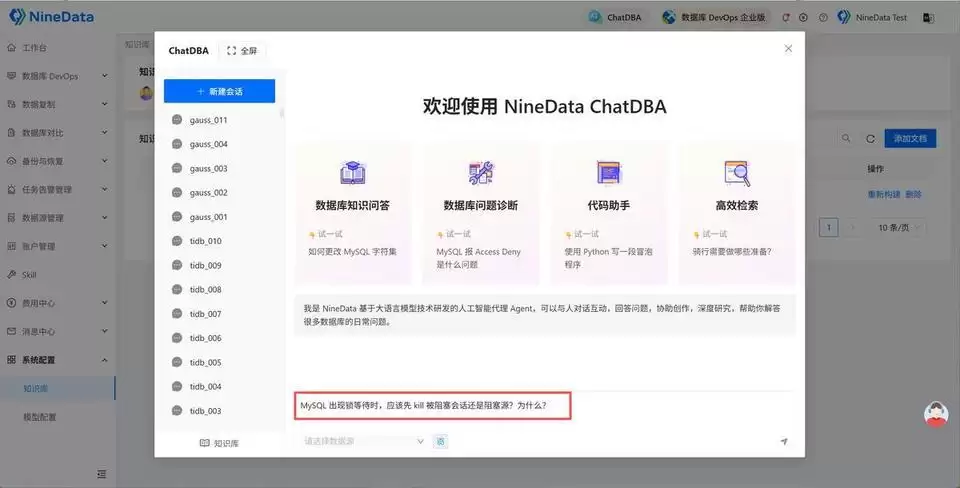
返回结果后,重点先看处理建议、注意事项和知识来源,然后判断这条回答是否已经能够满足团队当前的处理要求。
最后总结
MySQL 运维真正的难点,往往不在于有没有知识,而在于团队能否稳定地复用经验。ChatDBA 的知识问答能力,将数据库通用知识、企业私有知识库、历史上下文以及当前问题整合在一起,让经验不再只是少数人脑中的一本书,而是变成团队可以随时查阅和执行的行动指南。