宇宙学标准模型 ΛCDM(Lambda-Cold Dark Matter,即宇宙常数-冷暗物质模型)已经稳定运行了几十年。然而近年来,随着对大质量中微子、修正引力以及暗能量演化等前沿课题的深入研究,物理学家们开始质疑:ΛCDM 或许不是宇宙的最终答案。棘手的是,每检验一种新的物理假说,就必须从头构建一套高精度的宇宙模拟,其背后的计算成本高得惊人。
普林斯顿大学和弗拉特艾恩研究所的物理学家最近找到了一种巧妙的解决方案——借鉴大型语言模型中“预训练-微调”的策略。具体而言,他们首先利用成本较低的标准宇宙学模型训练人工智能,随后再使用少量且昂贵的新物理模拟数据进行微调。结果显示,这一方法确实能将计算成本大幅降低。不过,研究人员同时观测到一个有趣的现象,称为“负迁移”:如果新物理的信号与旧理论的某一参数高度相似,人工智能反而学习得更加缓慢,表现也更差。
这不禁引发思考:在探索新物理的过程中,AI 所习得的旧知识,难道反而成了前行的阻碍?
新物理模拟虽具优势,但算力消耗极为高昂
ΛCDM 模型能够解释从宇宙膨胀到星系分布的大量宏观现象,堪称宇宙学界的“万金油”。但粒子物理实验已证实中微子具有质量,而它到底有多重至今仍是未解之谜。此外,引力在大尺度上是否严格遵循广义相对论、暗能量是否会随时间动态演化——这些悬而未决的前沿问题,正推动物理学家们一步步迈向标准模型之外的“新物理”领域。
未来几年,第四阶段(Stage-IV)的巡天项目,例如暗能量光谱仪(DESI)、欧几里得空间望远镜(Euclid)以及薇拉·鲁宾天文台(Vera C. Rubin Observatory),将生成前所未有规模的高精度数据。这些数据或许能回答上述未解之谜。
然而,要从观测数据中提取“新物理”的信号,物理学家需要将真实数据与大量宇宙学模拟进行比对,这便是所谓的基于模拟的推断(SBI)。但包含新物理的模拟通常比标准的 ΛCDM 模拟昂贵得多,算力需求会成倍增长。

图 | 不同宇宙学模型模拟出的同一宇宙区域(来源:EurekAlert)
先训练,再微调
为了压缩成本且不影响科学发现,研究者们从生成式 AI 中借鉴了一种方法——“预训练-微调”。想象一下:模型先在海量通用文本上学习,再针对特定任务进行微调。将这一思路迁移到宇宙学中,就是构建一个能跨物理模型复用知识的“基础模型”。
研究团队使用的是由多国科学家联合开发的堂吉诃德宇宙学模拟数据集(Quijote simulations),其中包含 44,100 次 N 体宇宙学模拟,专为机器学习训练而设计。他们首先利用三万余个标准宇宙学模型(ΛCDM)对神经网络进行高强度预训练,让网络建立起关于宇宙大尺度结构演化的经典物理常识。
随后,这一预训练模型被迁移到包含新物理特征的高精度模拟中,继续进行微调。这三种“超越标准模型”的场景分别是:大质量中微子(M_ν)、Hu–Sawicki 形式的修正引力 f(R)、以及原初非高斯性(包括 local 和 equilateral 两种类型)。
团队成员阿德里安·拜尔(Adrian E. Bayer)打了个比方:这就像人类由浅入深的学习过程,先读一本入门教材建立整体框架,然后只需研读几篇前沿论文,便能快速适应新的物理定律。反之,如果一开始就让 AI 直接处理最贵、最复杂的新物理模拟,效率反而大打折扣。
十倍效率提升,架构选择至关重要
结果相当亮眼。在三种新物理场景下,迁移学习策略均表现出色。尤其在大质量中微子的案例中,采用迁移学习的网络仅需原方法不到十分之一的新物理模拟训练量,就能达到相同的推断精度。修正引力 f(R) 的情况也类似。而在原初非高斯性的实验中,迁移学习几乎全面提升了网络对各个宇宙学参数的推断敏感度。
为了验证效率提升确实源于知识的结构化复用,研究人员设计了一组对照实验。他们将 ΛCDM 模拟与新物理模拟混合,在相同数据总量下联合训练一个更大的神经网络。结果,其表现远不及两阶段的迁移学习方法。
在对比的三种网络方案中,表现最佳的是一种引入了“哑节点”(Dummy Nodes)的瓶颈结构网络。简单来说,在预训练阶段,这种架构的输出层就已经预先设计好若干空白输出通道,专门为未来可能出现的新物理参数预留空间。这些通道在第一阶段不参与损失函数的计算,但到了微调阶段,便可以用来承载和吸收新引入的物理参数。
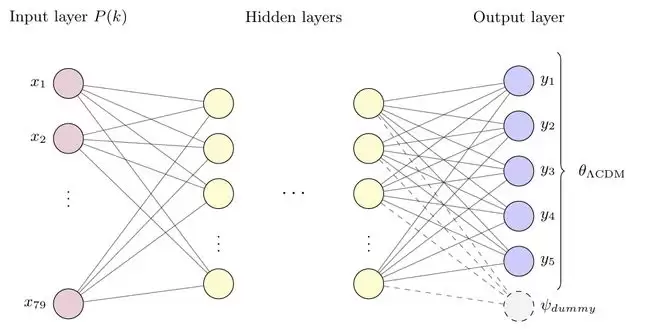
(来源:DOI 10.1088/1475-7516/2026/06/026)
相反,那种直接冻结预训练权重、仅在末端拼接一个可训练推断头的保守方案,表现最差。原因在于,这种硬性的架构限制将网络内部表征牢牢锁定在标准模型框架内,缺乏理解新物理所必需的灵活性。
负迁移现象:AI 温故却难知新
这种训练策略也存在短板。实验中,研究人员发现了一种“负迁移”现象。他们使用了对于中微子质量更敏感的统计量——标记功率谱(marked power spectrum)进行实验,结果发现,随着第一阶段预训练的不断深入,网络在第二阶段微调后的实际表现反而变差,关键参数的推断精度出现了明显恶化。
进一步分析发现,问题出在参数简并性上。σ₈ 是描述宇宙中物质聚集程度的关键参数,它会在小尺度上显著影响功率谱的形状。而大质量中微子由于自由流效应,也会抑制小尺度结构的形成。两者在观测数据中的痕迹极为相似。可以说,σ₈–M_ν 的这种简并性,一直是宇宙学家精确测量中微子质量时的核心障碍之一。
研究团队借助 SHAP 方法对网络内部决策进行了可视化分析,真相逐渐浮现:在预训练阶段,网络学会了将小尺度上的功率谱变化归因于 σ₈;而微调引入中微子质量后,这些小尺度特征突然有了第二种解释。于是,网络不得不推翻此前的映射,将一部分原本归因于 σ₈ 的信号重新分配给 M_ν,再从更大尺度的信息中“重新学习”σ₈,最终导致性能下降。
为了证实负迁移确实由物理简并性驱动,研究者干脆从小尺度数据中剔除训练,仅保留大尺度信息。而在大尺度上,σ₈ 与 M_ν 的物理印记完全可区分。结果非常明显:一旦切断小尺度上的简并可能,负迁移现象基本消失,网络顺利地将中微子质量视为一个全新独立的成分进行学习。
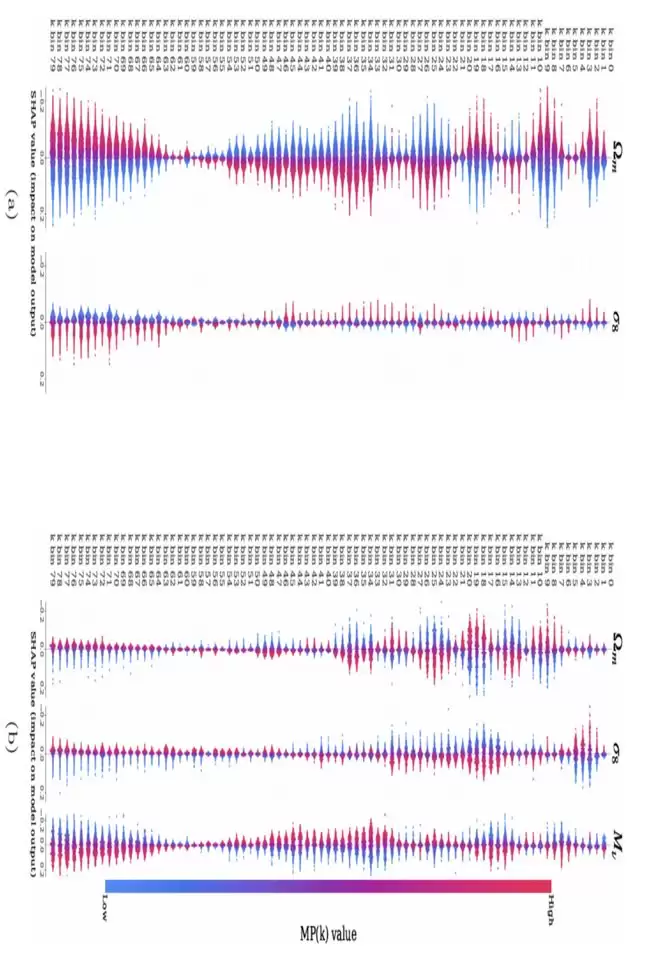
(来源:DOI 10.1088/1475-7516/2026/06/026)
摆脱路径依赖,才能发现未知
在自然语言处理或计算机视觉的任务中,不同任务之间通常共享大量底层结构,因此预训练几乎总是有效。但在物理学中,不同的物理机制可能在观测数据中表现出完全相同的特征。因此,利用 AI 探索新物理时,如果一味追求构建一个庞大、全能的物理基础模型,反而可能遗漏真正重要的信号。
针对“负迁移”问题,研究人员指出了几个值得探索的解决方向:特征空间分解(将不同尺度的物理效应解耦)、梯度校正机制(防止新物理的梯度信号被预训练表征覆盖),以及渐进式域适应等。
随着第四阶段巡天的临近,面对海量数据,这项研究提供了一种高效的应对方案:廉价的 ΛCDM 模拟可以作为基础模型被大规模复用,从而显著降低新物理模拟的算力需求。
AI 已开始深度参与科学发现过程,但这项研究也提醒我们:AI 同样存在路径依赖。要想真正发现“未知”,除了积累大量的已知规律,有时还需要学会“遗忘”。
参考内容:
https://iopscience.iop.org/article/10.1088/1475-7516/2026/06/026




