每个数据团队应该都经历过这样的幻想:业务用户随口问一句——"上季度亚太区月活用户数是多少?"或者"为什么华东仓的履约时效在过去两周一直在掉?"——系统就秒回一个准确、可追溯、还能直接指导行动的答案。这种场景,就是 Agentic Analytics 正在努力兑现的下一代分析体验。
跟传统 BI 相比,Agentic Analytics 的变化可不止是把输入框从报表换成了对话框。它的核心逻辑是让 AI Agent 自己拆解问题、去数据里摸索、验证假设,甚至在必要的时候触发后续操作。正因如此,越来越多的数据平台和 BI 厂商,都把它列为接下来的重点方向。
不过,很多 POC 项目很快就撞上了现实这堵墙:AI 助手根本不理解你们公司的"活跃客户"指的到底是什么;回答看着挺顺畅,但经不起多追问两句;关键数据散落在不同数据库、数据湖、对象存储和历史数仓里,Agent 根本拿不到完整的上下文;一旦查询稍微复杂点,几十秒甚至几分钟的等待,对话体验直接就断了。
这种时候,最容易得出的结论就是:"模型还不够强。"
模型当然重要,但它不是唯一的变量。一个再厉害的 LLM,如果面对的是性能低下、数据碎片化、缺乏业务语义的底层系统,也很难稳定地完成分析任务。Agentic Analytics 能不能真正落地,很大程度上取决于底层的数据库基座,是否具备三个关键能力:交互式分析性能、跨源数据统一访问、以及能被 Agent 理解的业务语义。
Agentic Analytics 对数据基座的三项硬性要求

交互式极速分析: Agent 在推理过程中,会反复经历 Schema 检查、数据采样、SQL 生成、执行和修正。只有做到亚秒到数秒级的响应,整个分析对话才能保持连贯。
跨源数据统一访问: 企业里的数据,分布在 RDBMS、数据湖、数仓和对象存储里。Agent 需要直接访问完整的数据视图,而不是等着漫长的 ETL 改造完成。
内置语义上下文: LLM 并不知道你们公司"活跃客户"或"流失率"的定义。语义层的作用,就是让 Agent 能按照统一的业务口径去理解数据和查询。
这三项能力不是什么锦上添花,而是 Agentic Analytics 能不能跑起来的基础条件。而 SelectDB,作为基于 Apache Doris 构建的云原生实时数仓,正好在这些维度上给出了完整的支撑。
支柱一:实时极速分析,让 Agent 保持思考节奏
Agentic Analytics 和传统 BI 的一个关键区别在于:查询负载变得更加探索性,也更难预测。仪表盘通常是围绕固定的指标和查询设计的;但 AI Agent 会根据问题不断地调整聚合维度、筛选条件和时间窗口,产生大量相似但不完全相同的查询。一旦底层引擎响应慢了,Agent 的分析链路马上就会断掉。
这正是 Apache Doris 擅长的场景。作为 MPP 实时分析数据库,Doris 天生就是为高并发、低延迟的 OLAP 查询而设计的,能够为 Agent 的多轮探索提供稳定的交互式性能。
- 大规模低延迟查询: Doris 支持在超大规模数据集上实现亚秒到秒级的 OLAP 查询,确保 Agent 的探索式分析能及时返回结果。
- 实时写入与即席查询并存: 借助 Flink CDC、Kafka 等实时数据摄入能力,Agent 不仅能分析历史数据,也能实时观察正在发生的业务变化。
- 物化视图与查询缓存: Agent 经常会产生大量相近的查询。Doris 的物化视图和查询缓存,可以有效减少重复计算,降低延迟和资源消耗。
支柱二:湖仓一体,让 Agent 看见完整数据
真实的业务环境中,数据很少只存在于一个系统里。核心交易数据可能在 MySQL 或 PostgreSQL,分析数据在 Iceberg、Hudi 或 Hive 表里,日志和归档数据则分布在 S3、OSS、HDFS 等对象存储上。
如果为了让 Agent 工作,先得发起一场大规模的数据迁移,那成本和周期都会非常高。更重要的是,在迁移完成之前,Agent 始终看不到完整的数据,业务价值也被大大延后了。
SelectDB / Doris 采用了一种更务实的方式:通过湖仓一体与联邦查询,把已有的数据源都纳入一个统一的分析入口。Doris 的 Multi-Catalog 架构,支持透明地访问多种类型的数据源:
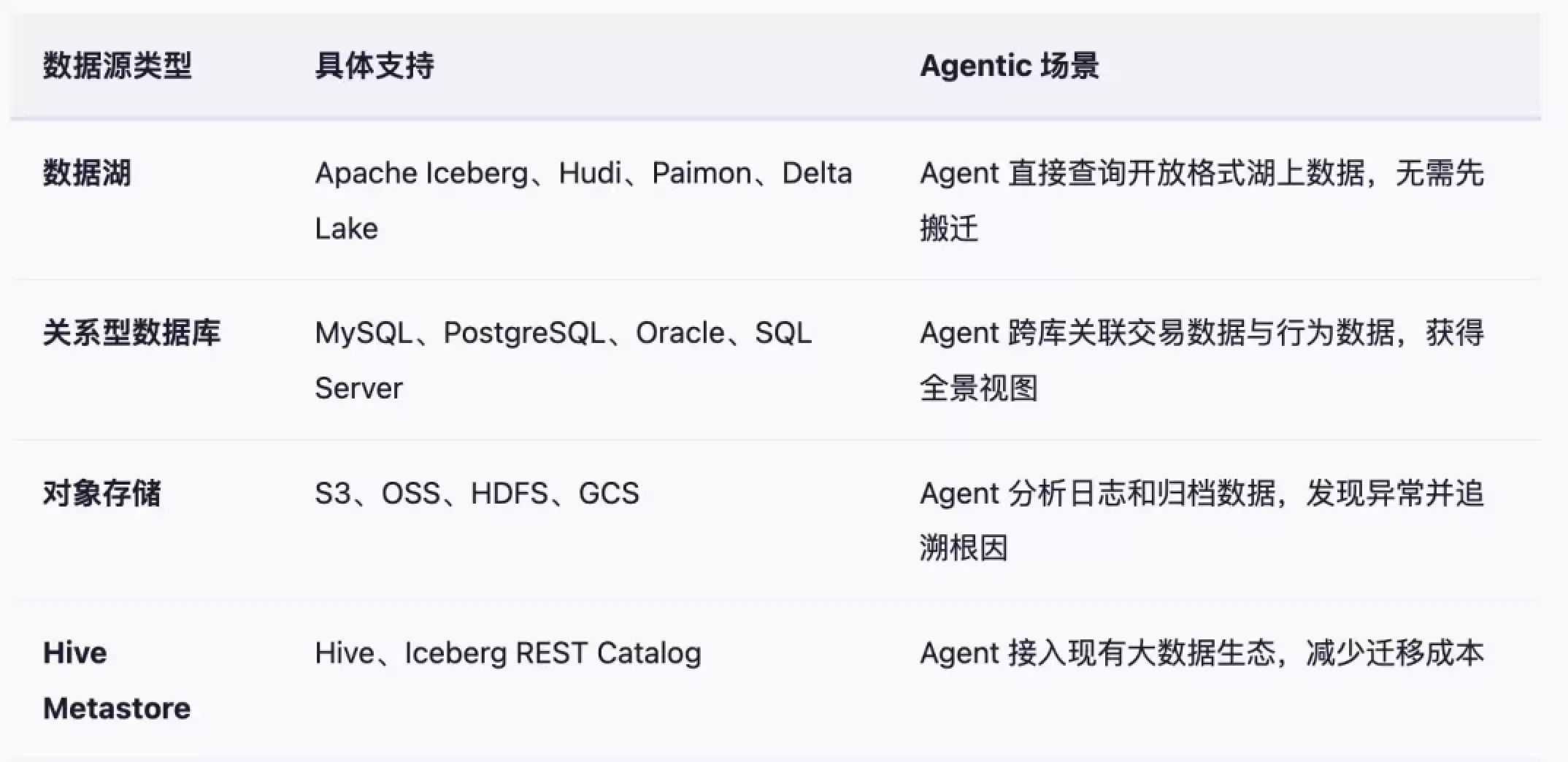
这意味着 Agentic Analytics 可以更早地进入到真实的业务场景中。Agent 不需要等所有数据都搬完,而是通过 Doris 的联邦查询能力,用统一的 SQL 直接访问跨源数据。当业务价值被验证之后,企业仍然可以逐步把高频数据迁移或优化到更合适的架构中。
支柱三:语义层与 MCP 接口,让 Agent 理解业务
LLM 本身并不了解你们公司内部的业务口径。它不知道"活跃客户"是指 30 天内有交易,还是 7 天内打开过 App;也不知道"流失率"是应该按账户算、按用户算还是按设备算。面对 tbl_usr_trx_v5 这样的表名,它更难判断背后到底是什么业务含义。
这也就是 语义层 的价值所在:把表、字段、指标和业务定义,转化成 Agent 能够理解并且稳定调用的上下文。SelectDB / Doris 从几个层面提供了支撑:
- 语义建模能力: SelectDB 和 Doris 已经支持 MetricFlow 等语义模型。Agent 访问的是经过治理的指标口径,而不是直接面对一张裸表去猜含义。
- 统一 SQL 接口: 不管数据来自实时写入、联邦查询还是湖上表,Agent 面对的始终是同一个 SQL 入口。这让"月收入""活跃客户"这些指标,在跨源数据上也能保持定义一致。
- MCP 接口(Model Context Protocol): SelectDB 可以通过 MCP Server,让 Claude、ChatGPT、Cursor,以及基于 LangChain / LlamaIndex 构建的自定义 Agent,以标准化的方式去发现数据集、查询 Schema、检索语义上下文,并执行经过治理的 SQL。
有了 MCP,Agent 不需要为每个数据系统单独适配接口。一次接入之后,主流的 AI 客户端和自定义 Agent 就能通过统一入口,获得数据发现、语义理解和 SQL 执行的能力。
不止于引擎:SelectDB Cloud 如何降低落地成本
Agentic Analytics 还有一个容易被低估的问题:查询负载变得更加不可预测。传统 BI 往往有固定的刷新节奏和报表周期;但 Agent 可能因为一次业务追问、一次异常检测或者一次自动化任务,在短时间内发起大量的临时查询。
这种负载模式天然就适合弹性架构。SelectDB Cloud 通过存算分离和 Serverless 能力,让企业更容易控制 Agentic Analytics 的基础设施成本:
- 存算分离、弹性扩缩容: 计算和存储资源独立伸缩。查询高峰来了就扩容,高峰结束就缩回去,避免为了峰值长期保留闲置资源。
- Serverless 免运维: 数据团队可以把更多精力投入到语义层建设、权限治理和 Agent 场景设计上,而不是天天管理集群、盯着容量水平。
- 适合 Ad-Hoc 查询: Agent 会产生大量探索式、一次性的查询。弹性架构可以按实际使用量计费,大大降低了试错和探索的成本。
另外,阿里云 SelectDB 已经推出了 Serverless 版本。根据阿里云官方信息,该产品已于 2026 年 3 月正式商业化,可以提供秒级弹性能力,为面向 Agent 的分析场景进一步降低了基础设施的门槛。
SelectDB / Doris:Agentic Analytics 的最佳数据基座
回到 Agentic Analytics 对数据基础设施的核心要求上,SelectDB / Apache Doris 的价值可以简单概括为:

换句话说,SelectDB 把实时分析引擎、湖仓联邦查询、语义建模、MCP 标准接口和弹性计算能力,都整合到了同一个平台里。无论是 Claude、ChatGPT、Cursor,还是企业自建的 Agentic 应用,都可以通过这个统一入口,在治理过的语义视图之上,对跨源数据进行探索式分析。
Agentic Analytics 正在重新定义数据分析的方式——让系统不仅回答问题,还能主动探索数据、发现业务洞见。但真正落地,需要的远不止一个模型,而是一套能够支撑实时分析、跨源访问、语义理解和弹性计算的完整数据基座。




