AI 拨测:传统方法已无法满足需求,三层主动拨测才是关键
传统的拨测逻辑非常直接:发送一个请求,检查是否通畅,确认状态码是否正确。只要通了且状态码对,就默认系统正常。
然而,这套方法用在 AI 场景中基本形同虚设。原因很简单——无论你测试的是模型厂商还是中间的中转服务,从外部看它只是一个接口。接口返回 200,不代表它能真正正常工作。
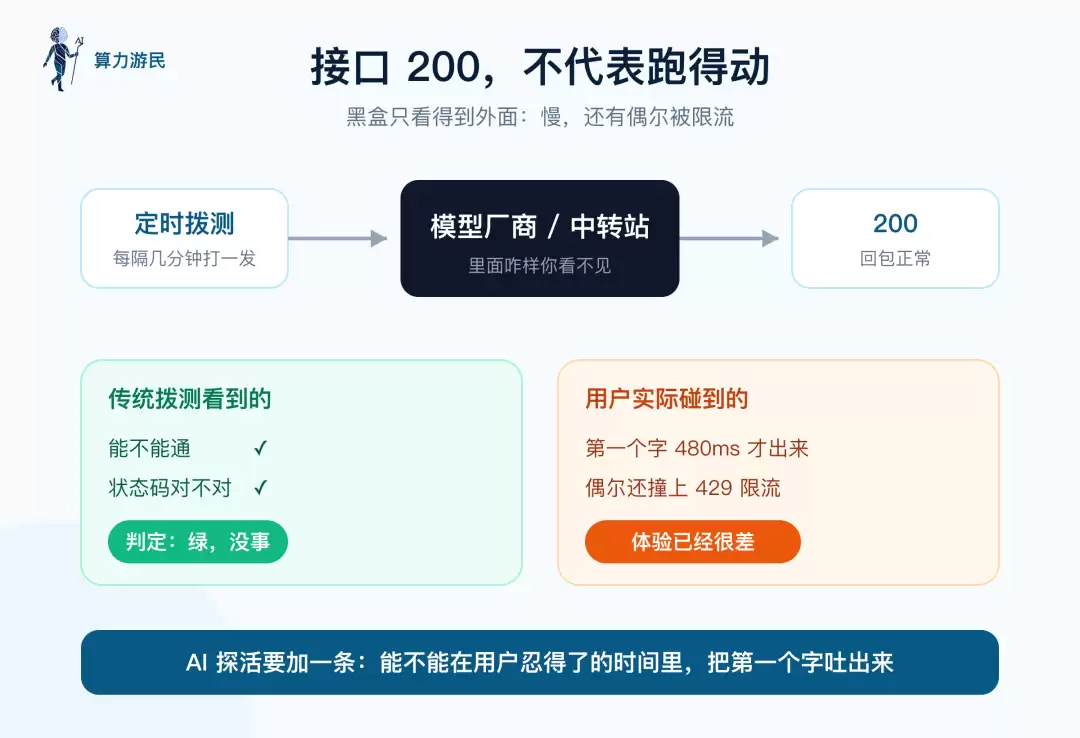 接口返回 200,但首个字响应慢、有时被限流,传统拨测显示全绿,用户体验却已很差
接口返回 200,但首个字响应慢、有时被限流,传统拨测显示全绿,用户体验却已很差
接口确实存活,但第一个字迟迟无法输出,偶尔还会被限流拦截。用户早已等得不耐烦。因此,AI 拨测必须加入一条硬性标准:能否在用户可接受的时间内,输出第一个字。
这仅仅是第一层。往上还有两层,传统方法越往上越难发现问题。
分层剖析:从连通到质量
连接正常、首个字及时输出后,第二层问题随之而来:模型的生成过程是否规范?能否按要求完整生成内容?
这一层专注于生成过程本身是否顺畅。例如:是否遇到max_token限制导致截断?该按stop停止的位置是否正确执行?长文本输入输出是否匹配?是否返回空内容?中转站的缓存是否命中?这些问题,接口依然会返回 200。
再往上是第三层,也是最容易被忽视的一层。内容虽然完整返回,但它是否正确?质量如何?退款政策说反、合同摘要遗漏关键条款、本该正常回答却回复“这个我不能答”——所有问题接口都返回 200,传统拨测完全察觉不到。
这三层叠加,越靠上的问题越难发现。
 AI 拨测分为三层,自下而上为 L1 连通层、L2 有效层、L3 质量层,越往上信号越弱越难察觉,每层对应一种断言
AI 拨测分为三层,自下而上为 L1 连通层、L2 有效层、L3 质量层,越往上信号越弱越难察觉,每层对应一种断言
最隐蔽的退化,恰恰都发生在最上面这一层。而这一层,恰恰最难发现。
主动拨测:无流量场景下也能发现隐患
在深入讨论具体方案前,需要先厘清一个容易混淆的概念。
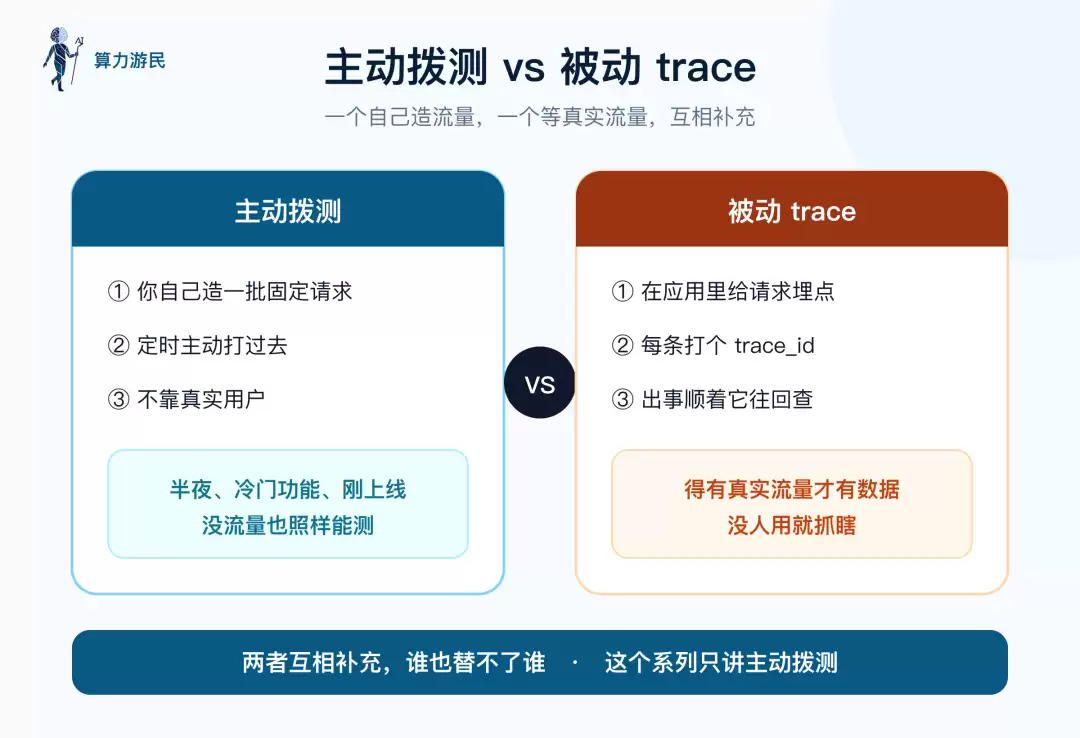 主动拨测自行构造固定请求,即使没有真实流量也能持续测试;被动追踪依赖真实流量埋点,两者互为补充
主动拨测自行构造固定请求,即使没有真实流量也能持续测试;被动追踪依赖真实流量埋点,两者互为补充
被动追踪需要真实流量流过才能获取数据。而主动拨测则主动构造一批固定请求,定时执行。深夜、冷门功能、刚上线尚未吸引用户时,主动拨测依然能正常运作。本系列只讲解主动拨测这一部分。
每一层最大的挑战:如何编写断言
实际实施时你会发现,虽然定时发送请求的步骤与传统方式相同,但真正的难点在于如何编写断言。
AI 模型具有不确定性:同一个问题问十次,可能得到十种不同表述。如果断言“必须包含某个词”,模型使用近义词就会误报;如果放松到“只要不为空”,那些包含错误政策的回答同样能蒙混过关。
真正有效的断言分为三种,刚好每层对应一种:
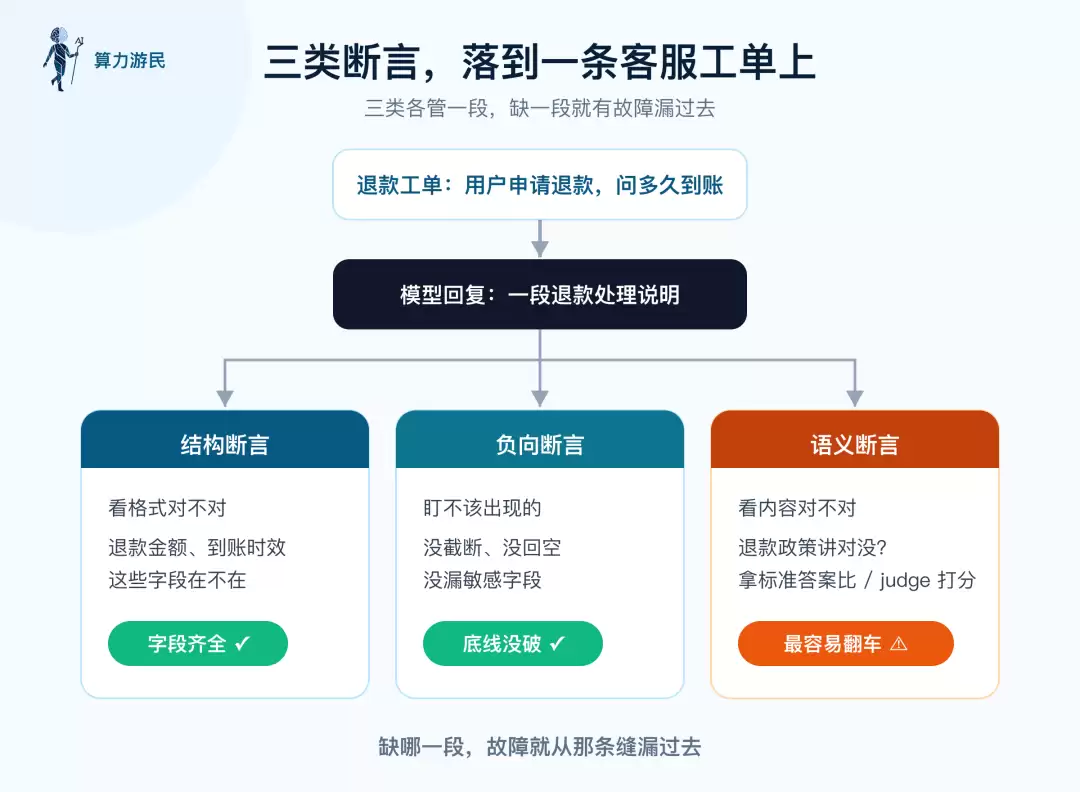 以一条退款工单为例,结构断言检查字段完整性,负向断言守住错误底线,语义断言判断内容正确性
以一条退款工单为例,结构断言检查字段完整性,负向断言守住错误底线,语义断言判断内容正确性
图中三类断言,越往上越依赖语义断言,也越难编写。质量层的有效性,完全依靠语义断言支撑。
后续拆解规划
接下来三篇文章,将从下到上逐层深入讲解:
- L1 连通层:如何探活、首个字超时阈值设定、悄悄切换到备用模型(fallback)的检测方法。
- L2 有效层:如何监控
finish_reason、检测生成是否被截断、缓存命中率、长文本输入输出一致性,确保本次生成符合规范。 - L3 质量层:固定测试集(golden 集)如何构建、判断内容正确性的断言如何落地、测试频率与成本控制策略。
所谓“测到位”,就是同时盯住这三层——连接通畅、按规范产出、内容正确。本文先梳理整体框架,后续将一层一层深入剖析。




