将AlphaFold从“预测少数几个复合物”提升至“高通量筛查数千种蛋白质”的全配体互作场景时,计算开销往往是最大的瓶颈。斯德哥尔摩大学与林雪平大学的研究团队近日在Bioinformatics上发布的AF_Cache工具,正是为破解这一难题而设计。它并未提出全新的预测模型,而是精准聚焦于一个核心目标:消除重复计算。该流程的基本原理可归结为一个简单的算术事实——在全互配筛查中,绝大多数多序列比对(MSA)与模型编译都是冗余操作。AF_Cache通过“去冗余”、“GPU加速比对”与“分桶编译”三项策略,将原本需要数周的计算任务压缩至几天甚至数小时。

文献信息
项目 | 内容 |
|---|---|
标题 | AF_Cache: Efficient Pipeline for Running AlphaFold for High-Throughput Protein-Protein Interaction Prediction |
作者 | Sarah Narrowe,Arne Elofsson(斯德哥尔摩大学 生物化学与生物物理系 / SciLifeLab);Claudio Mirabello(林雪平大学 / NBIS,通讯作者) |
来源 | Bioinformatics(2026,Application Note);预印本 arXiv:2606.04566v1 [q-bio.BM] |
代码 | https://github.com/clami66/AF_cache |
数据/复现 | https://zenodo.org/records/20478892 |
类型 | 工具/流程类(Application Note),非新模型,非新算法 |
一、问题背景
蛋白质-蛋白质相互作用(PPI)是几乎所有细胞过程的基础,AlphaFold2(AF2)与AlphaFold3(AF3)已能够从结构层面以接近实验的精度预测这些互作。然而,当目标从“几个复合物”转向“对成百上千种蛋白质进行全互配筛查”时,官方默认流程的计算开销会迅速膨胀至难以承受的程度。
作者将AlphaFold的耗时分解为两大来源,这一框架在AF2与AF3中均成立:
(1)多序列比对(MSA)生成。官方流程依赖CPU上的JackHMMer与HHblits进行同源序列搜索,这一过程本身较慢。更关键的是,每次预测前都会为当前复合物的每条链重新生成MSA,完全不复用之前计算过的结果。在全互配场景下,同一个单体的比对会被反复计算无数次,这正是最根本的资源浪费。
(2)JAX模型编译(仅AF2)。AF2的神经网络基于JAX,当输入序列长度变化时需重新编译计算图。对于长蛋白质,这一开销可以忽略;但对于一批短蛋白质,编译反而成为单次预测中最耗时的环节。AF2提供了将序列补齐至等长以复用编译的选项,但该选项仅对单体有效,且不支持按多个尺寸分桶,对短序列的效率较差。
事实上,更快的MSA方法早已存在:ColabFold使用MMseqs2替代CPU比对;Perry等人的AlphaFast进一步采用GPU版MMseqs2,并以批处理方式加速AF3的MSA生成。AF_Cache与这些工作一脉相承,但其定位更为全面——将“去冗余”、“GPU加速”与“减少编译”三项任务协同解决,并且同时支持AF2与AF3。
二、方法学详解
AF_Cache的核心由三项相互独立且可叠加的优化策略组成。理解各自解决的问题,是评估该流程价值的关键。
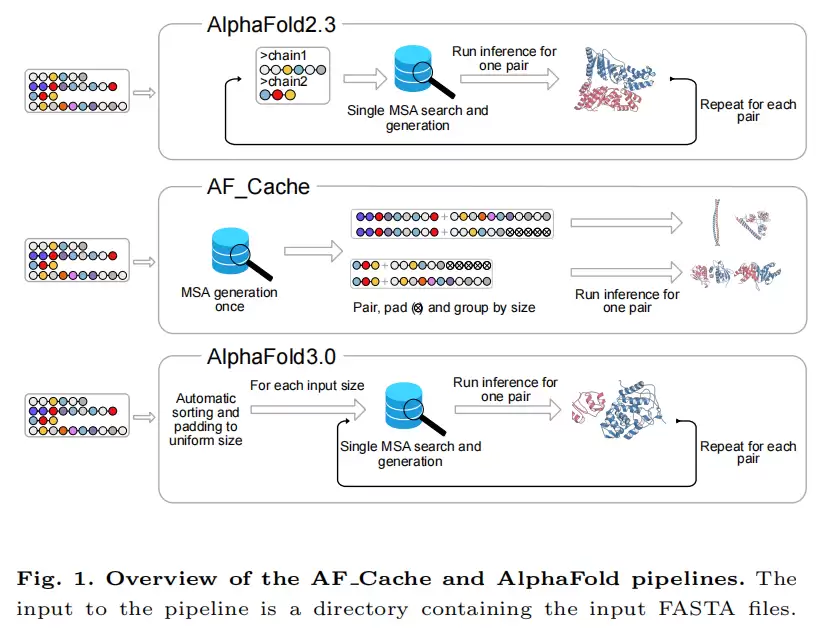
2.1 GPU加速的MSA生成(MMseqs2-GPU + CPU/GPU并行)
整个数据集的MSA在工作流开始时一次性生成,采用GPU加速版的MMseqs2。搜索与profile均在GPU上执行,单卡已比纯CPU更快,使用多卡时加速比还可进一步提升(本文基准在单卡上进行)。
在比对协议上,AF_Cache沿用ColabFold的流程,并引入一项巧妙的工程改进:在对UniRef与环境数据库分别比对时,让CPU步骤与GPU步骤跨两个数据库并行执行,从而减少GPU等待UniRef比对完成时的空闲时间。这是对ColabFold的一项增量优化。
2.2 输入特征缓存:将组合爆炸压缩回线性
这才是全文最具价值的设计。其依据是一个简单的组合数学事实:
设有 N 个蛋白质进行全互配(含同源二聚体),需预测的二聚体数量为 N(N+1)/2 对。每对包含2条链,按默认逻辑,链级比对总数为:
默认链级 MSA 次数 = N × (N + 1)但这些链中,互不相同的单体实际上只有 N 个。原因在于默认流程将每个单体的比对重复计算了约 (N+1) 次。AF_Cache的做法是:对一组去重后的单体,所有比对与模板特征只生成一次并缓存,需要时直接复用。 缓存以pickle文件形式存于AF2版本,以JSON输入文件形式存于AF3版本。
为量化收益,作者定义了三条对照基线:
- vanilla(原版):官方默认行为,每对、每条链都重新生成MSA。
- opti(手工优化):将100个单体的MSA只生成一次,再用符号链接(AF2)或写入输入JSON(AF3)的方式复用。这是有经验用户可以手动设置的合理基线。
- AF_Cache:在opti的去冗余之上,叠加GPU比对与(AF2的)分桶编译。
2.3 模型编译优化:尺寸分桶 + 张量补齐(仅AF2)
针对AF2的JAX重编译问题,AF_Cache将总长度(两条链长度之和)相近的复合物归入同一个“桶”,桶内将所有特征张量补齐至相同长度。这样,JAX模型在每个桶内只对第一个复合物编译一次,后续所有复合物直接复用已编译图。每省去一次编译,可节省约1–2分钟的GPU时间。
值得一提的是,AF3自身已内置类似机制(对单体与多聚体均自动按桶补齐),因此作者仅为AF2实现该功能,AF3部分直接复用官方推理代码。
2.4 工程实现与可用性
AF_Cache以单条Nextflow流程交付。工程完成度是其重要卖点:
- 输入仅需一个装有FASTA文件的目录;默认执行全互配,也可通过输入文件指定特定配对。对称对默认去重,可用
--both_directions开关包含双向。 - 流程自动下载并安装依赖,包括序列数据库与AF2的网络权重。这意味着它也是在本地或HPC上部署AF2/AF3的一种省心方式。
- AF3官方需要用户手动编写JSON输入,AF_Cache可全自动生成。
- 支持跨多节点的HPC并行,也支持在本地单机运行单个任务。模板生成可用
--skip_templates关闭。
三、基准测试设计
对于这类“加速”类工作,清晰的基准设计是评估可信度的前提。
数据集。作者于2026年1月从人类蛋白质图谱(HPA)中,按 subcell_location:Mitochondria AND hpa_evidence:Evidence at protein level 筛选出821个线粒体蛋白,再随机抽取其中长度在40–1000残基之间的100个蛋白。对这100个蛋白进行全互配预测,共5,050对:4,950个异源二聚体 + 100个同源二聚体。
结构证据标注。为识别“有结构支持”的蛋白对,作者使用MMseqs2以fident=0.7的阈值将每个蛋白比对到PDB。当两个或更多蛋白映射到同一PDB条目时,其所有可能配对均被标记为“共享PDB条目”。作者也明确指出,共享PDB条目并不等于这些蛋白一定直接相互作用。
预测设置。
- AF2:仅用
model_1_multimer_v3做单次预测,最大循环数=3;模板生成关闭。 - AF3:单一随机种子,单个扩散样本。
- 默认流程的MSA在独立的CPU集群上生成,使用与官方一致的工具与数据库。
硬件。默认流程的MSA部分使用8/16/32个Intel Xeon Gold 6130 CPU核;GPU任务在单块NVIDIA A100(40 GB)上运行。
作者也坦陈了一项值得注意的可比性限制:受HPC集群限制,默认流程的CPU与GPU部分只能分开运行,这与“真正一体化运行”的官方流程可能存在时间差异。为部分弥补这一点,他们将对比统一折算到128个CPU核(假设完美并行),但承认无法保证完全补偿。这是判断加速比是否被高估或低估的关键背景。
四、核心结果
4.1 预处理(MSA + 缓存)加速:把“13×”和“1343×”讲清楚
原文给出几个不同口径的加速比,初看容易混淆。作者从补充表S1的MSA列做了因子分解,发现这些数字实际上由两个正交因子相乘而成:
加速因子 | AF2(默认 full BFD) | AF3(默认 small BFD) | 物理含义 |
|---|---|---|---|
去冗余(opti / vanilla) | ~101× | ~101× | 链级比对 10,100 → 100 次,由组合关系决定 |
GPU 比对(cache / opti) | ~13× | ~5× | MMseqs2-GPU 相对 CPU 版 JackHMMer/HHblits |
合计(cache / vanilla) | ~1343× | ~542× | 两因子相乘 |
这个分解澄清了几个容易混淆的点:
- 原文摘要中的“MSA最高提速13×”,指的是单位比对吞吐上GPU相对CPU的提升(公平折算到128核后)。
- “相对vanilla提速1343×/542×”,则是将GPU加速与去冗余叠加后的总效果。两个数字并不矛盾。
- 至于更醒目的“1702×/688×”,是按“原始GPU核时 vs CPU核时”硬比得到的。作者本人也指出这不现实——因为GPU与CPU的成本及可得性不可同日而语,所以才有折算到128核后的13×/5×。
4.2 推理加速:AF2约2×,AF3不变
推理阶段的对比仅在AF2上有意义,因为AF_Cache3.0直接复用AF3官方推理代码,与默认AF3没有差异。(一个有趣的工程细节:AF3的3.0.1版本明显快于3.0.0,流程已自动采用3.0.1。)
对AF2,缓存+等长补齐将预测与编译的总时间从253 GPU·小时降至125 GPU·小时,降幅超过50%。按每对计,耗时从180.5秒降至89.2秒,恰好为2.02×,每对节省约91秒。这91秒正对应被分桶机制省去的JAX编译开销。换句话说,AF2的“2×推理加速”本质上就是把逐对重复编译变成了逐桶编译一次。
4.3 完整运行时分解
补充表S1和S2给出了非常详细的分解。以下是从中派生出的整体加速比一览:
对比 | AF2 | AF3 |
|---|---|---|
端到端 vs vanilla(最坏基线) | ~16.4× | ~8.6× |
端到端 vs opti(合理人工基线) | ~3.0× | ~1.06× |
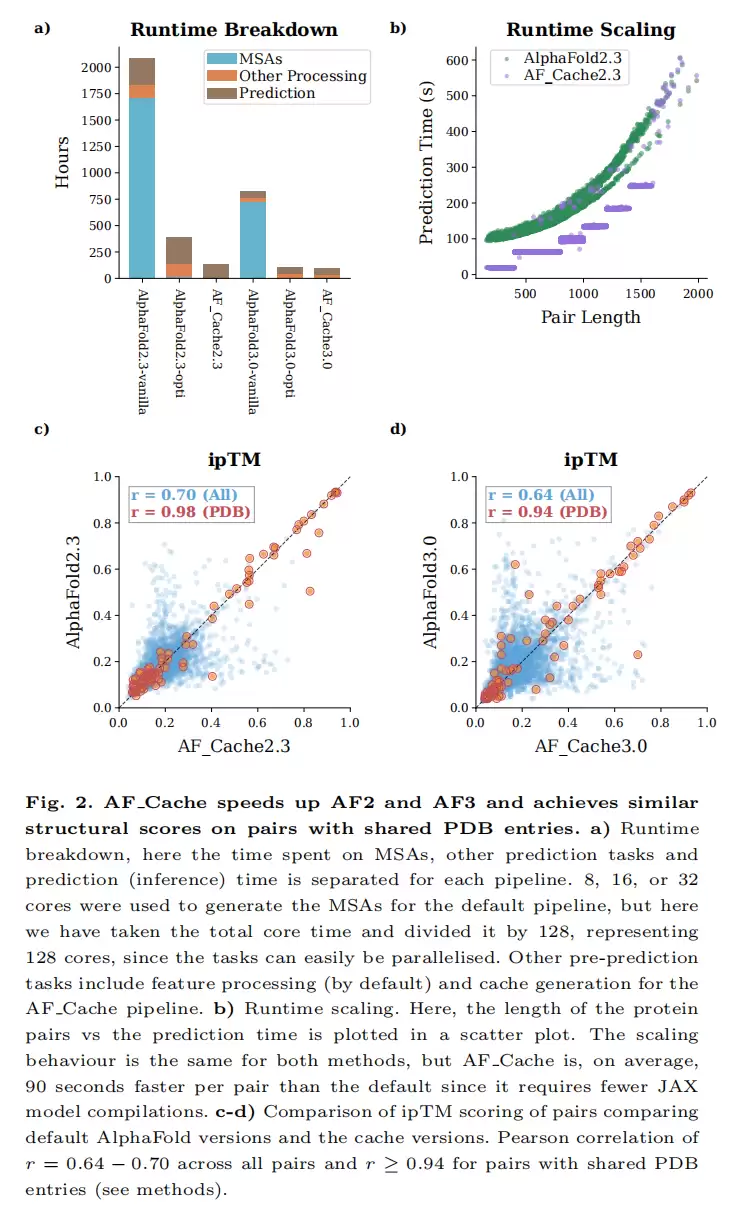
4.4 预测一致性(ipTM):整体中等,结构支持对高度一致
速度之外,作者利用ipTM评分对比新旧流程预测结果的一致性:
- 全体配对:相关性中等。AF2 r = 0.70、AF3 r = 0.64。
- 有共享PDB条目支持的配对:高度一致。r 升至0.98(AF2)/ 0.94(AF3)。
- AF2与AF3之间:整体相关0.42,但在共享PDB条目子集上升到0.92–0.94。
作者据此论证:对结构上真实可信的蛋白对,AF_Cache与官方流程给出几乎相同的判断;整体的中等相关反映的是AlphaFold自身对输入的敏感性,而非缓存引入的退化。
五、批判性评价
优点
- 定位精准,即插即用。不触碰预测内核,只消除冗余计算,因此风险低、可信度高。Nextflow封装、自动装依赖、AF3自动写JSON,工程完成度在同类工具中非常突出。
- 数字诚实。作者主动区分了“1702×的理想口径”与“13×的现实口径”,并坦陈HPC限制带来的可比性瑕疵。这种透明度在加速类论文里并不常见。
- 可分解、可复现。加速比能被干净地分解为“去冗余 × GPU比对”两个正交因子,且代码、MSA与预测模型全部公开。
需审慎看待之处
- 衡量的是“一致性”而非“正确性”。ipTM对比反映的是AF_Cache与默认AlphaFold输出是否彼此一致,而非它们对实验真值是否准确。全体配对仅中等相关,意味着两套流程在大量蛋白对上给出了不同的ipTM。无论使用哪套流程,都应谨慎解读单个配对的ipTM绝对值。
- 中等相关存在一个未被拆开的混杂因素。该相关性同时包含两个来源:(a) AlphaFold本身的随机性/输入敏感性,以及 (b) AF_Cache与“默认”在MSA数据库与比对工具上的系统性差异。论文将此主要归因于(a),但严格而言(b)也会有一定贡献。
- 基准范围有限。仅一个数据集(人类线粒体蛋白),对其他蛋白质组、超大复合物、超长或高度无序的序列的泛化性未直接验证。
- 加速比依赖硬件与基线。13×/5×取决于A100 vs Xeon的算力比以及“折算到128核”的假设。换一套硬件,结论会改变。
- 对AF3相对opti的净增益很小(~6%)。如果已在手动复用AF3的MSA,AF_Cache3.0的额外加速有限,其主要价值体现在自动化而非推理提速。
小结
AF_Cache将一个朴素却被长期忽视的事实——全互配筛查中绝大多数MSA与模型编译都是重复劳动——转化为一套工程扎实、覆盖AF2/AF3、通用性强的加速流程。其加速效果可以被清晰分解,对结构上可信的蛋白对,预测结果与官方流程高度一致。它并非一个新模型,但对于那些希望将AlphaFold真正应用于蛋白质组规模的研究者来说,这是一个极具价值的基础设施。




