在 MySQL 的世界里,长事务经常是被低估的那一类问题。它不像慢 SQL 那样立刻把 CPU 打满,也不一定会现场报个错给你看。
更多时候,它只是安静地挂在那里:事务已经开启了,SQL 也执行完了,就是迟迟不肯提交或回滚。表面看似风平浪静,但背后可能长期占用锁资源不放,阻碍 undo 日志的清理进度,甚至给后续的故障排查埋下不少隐患。

长事务最令人头疼的,不只是它待得久
长事务真正的麻烦在于,它往往不单是影响自己。一个事务如果长时间赖着不结束,可能一直攥着行锁,让后面排队等待的更新操作干着急;也可能导致历史版本迟迟无法被清理,给 undo 表空间带来持续压力。如果这个事务里还做了大量写入,那回滚成本也会同步抬高,一旦需要回滚,代价可就大了。
在业务高峰期或批量任务阶段,这些影响还会被进一步放大。排查时会经常遇到一种很头疼的场景:当前没有明显的慢 SQL,可数据库却不够稳定;有些会话看起来像是空闲连接,但背后却挂着未提交的事务;某些 DDL 或者更新任务一直在等待,追根溯源,真正的原因就是前面有个事务迟迟没有释放资源。
只看表面 SQL 的话,这类问题很难被发现。你需要把事务状态、会话信息、锁等待情况、执行历史等要素都放到同一个上下文里,才能判断问题到底卡在了哪个环节。
先找出那笔一直没结束的事务
ChatDBA 在做 MySQL 长事务诊断时,会重点盯着几个维度:事务持续时间、所属会话、执行用户、来源主机、当前 SQL、是否持有锁,以及它是否还在继续阻塞其他会话。真正需要先看清楚的,不是“有没有事务”,而是哪一笔事务已经构成了运行风险。
它会帮助用户判断:这个事务是不是已经运行太久、里面是否包含大量写入或大事务操作、是否持有锁并影响到其他会话、是否可能阻碍清理、变更或备份窗口,以及当前更稳妥的处理方式是提交、回滚、终止还是继续观察。
持续时间长和操作量大,很多时候是共存的
长事务有时单纯是持续时间拖得久,大事务则是一次性操作量太大。但在真实的 MySQL 生产环境里,这两类问题经常绑在一起出现,而不是彼此独立。
举个例子,一次 INSERT INTO ... SELECT ... 把大量数据导入到备份表,如果事务一直不提交,很可能形成一笔既大又长的事务。它不仅会持续占用资源、持有锁、增加回滚成本,还会让后续的排查现场变得更复杂。
ChatDBA 可以把这种场景从会话和事务中先识别出来,然后提示用户:当前问题更偏向于长时间未提交、大批量写入造成的压力,还是两者同时存在。继续往下追问时,它也能给出拆批执行、缩短事务窗口、避开业务高峰、增加发布前审核等一系列治理建议。
别只靠 DBA 一个人记这些经验
过去处理长事务,很大程度上依赖 DBA 的个人经验。查哪些视图、怎么看事务年龄、如何判断能否 kill、怎样评估回滚风险——这些都需要长期的实战积累。
真到操作时,可以这样问 ChatDBA
先登录 NineData 控制台,再进入 ChatDBA,这一步的目标是打开长事务诊断的入口。
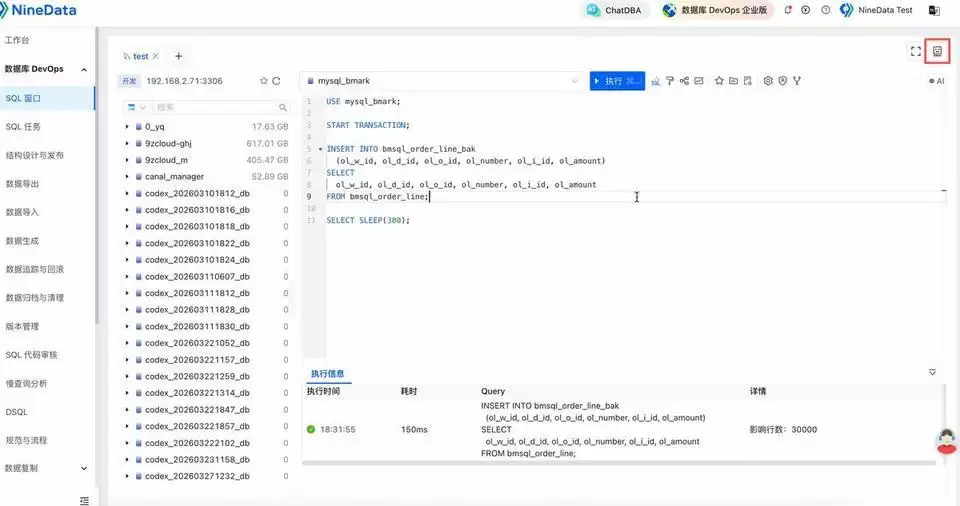
然后在对话框里直接输入长事务诊断需求就行,比如“请检查当前 MySQL 是否存在长事务或大事务,列出事务持续时间、会话、执行 SQL、可能风险和处理建议”。
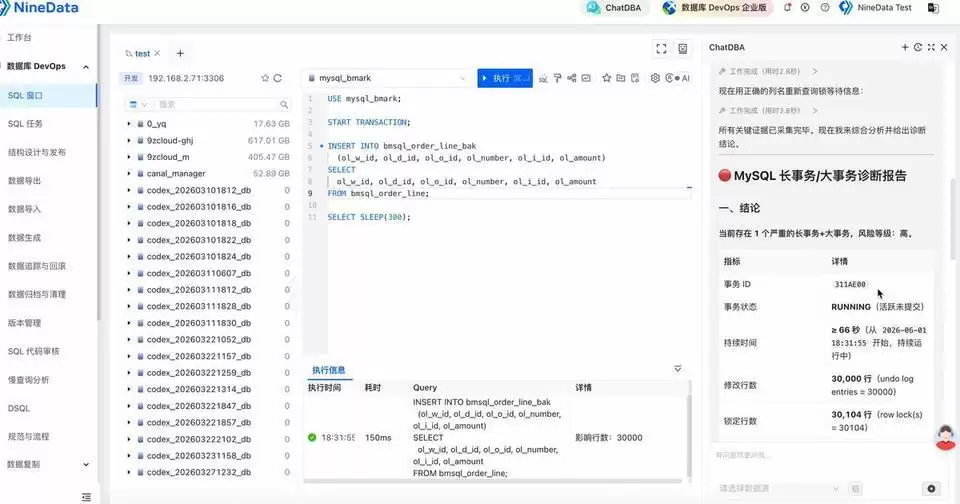
结果返回后,重点先看事务持续时间、相关会话、写入量、是否持锁、回滚风险,以及更稳妥的处理建议。先确认目前最该优先关注的是哪一笔事务。
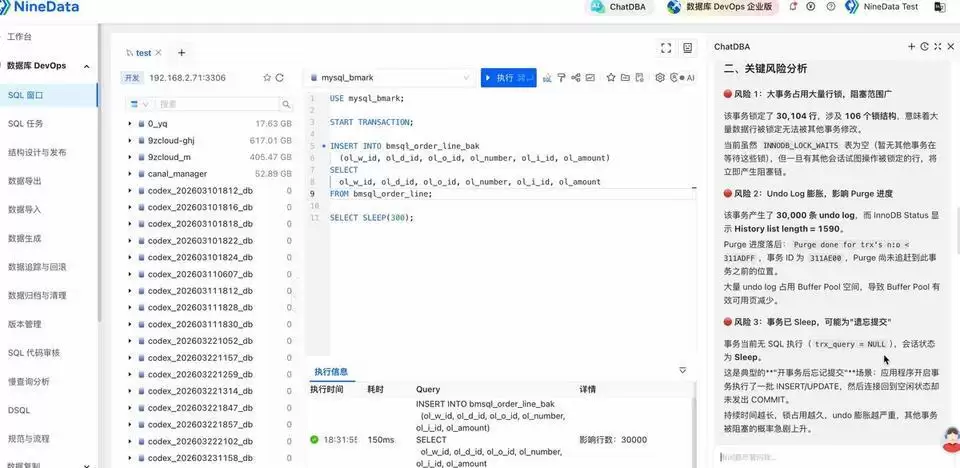
如果回答里已经提到了未提交风险、大事务压力或锁影响,那就继续顺着上下文往下追问,让 ChatDBA 把这笔事务为什么危险、当前从哪里入手最合适,讲得更清楚一些。
最后一句
MySQL 长事务最令人头疼的地方,就在于它会拖住别人。ChatDBA 的长事务诊断,核心价值就是帮助团队更快地发现未提交事务,判断影响范围,区分长事务和大事务,并给出更谨慎的处置建议。




