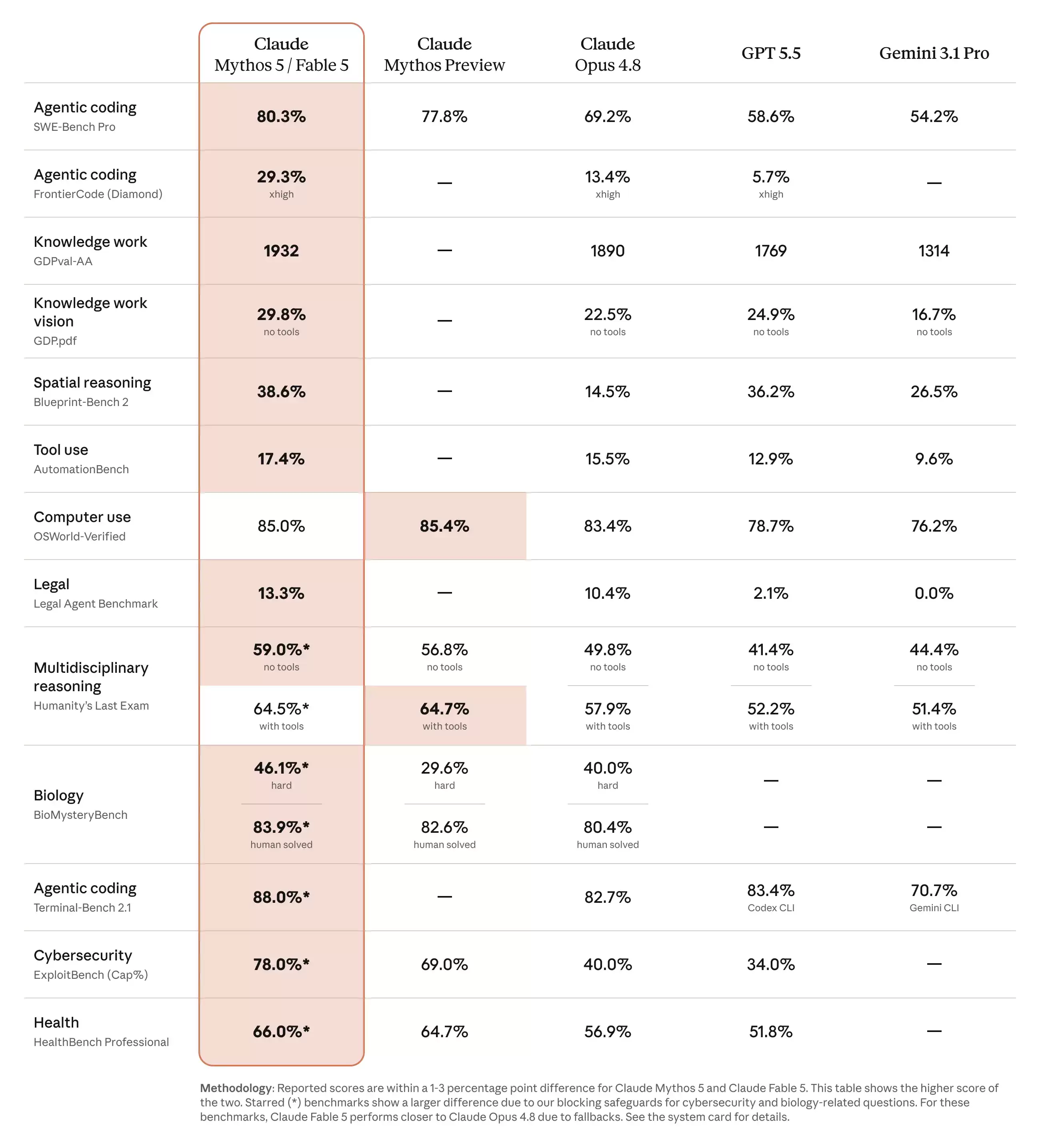
Anthropic 于 2026 年 6 月 9 日正式发布 Claude Fable 5,其定价一经公布,开发者便需仔细权衡成本效益。Fable 5 与 Opus 4.8 的选择,本质上取决于预算考量——Fable 5 的每 token 价格正好是 Opus 4.8 的两倍。输入成本为每百万 token 10 美元(Opus 4.8 仅需 5 美元),输出成本则为每百万 token 50 美元(Opus 4.8 为 25 美元)。因此,在审视任何基准测试数据之前,数学逻辑已然清晰:同一供应商、同一 Messages API 环境下,新模型溢价达 2 倍。关键在于判断在哪些场景下这笔溢价物有所值,哪些情况下纯粹是资源浪费。
Claude Fable 5 和 Opus 4.8 同属一个模型家族。Fable 5 的每 token 成本正好是 Opus 4.8 的 2 倍(10/50 美元 vs 5/25 美元)。对于大多数常规聊天、代码生成和检索任务,Opus 4.8 是更经济实惠的选择。只有在需要处理跨越数百万 token 且能保持连贯性的超长周期自主任务时,才值得考虑使用 Fable 5。否则,建议节省这笔额外开支。
由于两者唯一的区别在于模型标识字符串,你可以按请求进行灵活路由。将日常流量发送至 claude-opus-4-8,仅针对少数需要长周期自主性的任务将字符串切换为 claude-fable-5,全部在同一个客户端和相同的代码路径下完成。这使得“默认低成本、按需升级”策略易于实施:仅需一个配置值或一行条件判断,即可决定由哪个模型处理指定请求。
自行对比的方法
定价表与基准测试声明所能提供的信息终究有限。解决 Claude Fable 5 与 Opus 4.8 对比问题最可靠的方式,是向两个模型 ID 发送相同的 prompt,然后直接比较输出结果。这正是 API 测试工具擅长处理的工作。针对 Anthropic Messages API 配置一个请求,随后复制该请求,仅修改模型字段:一个填入 claude-fable-5,另一个填入 claude-opus-4-8。使用真正接近生产环境流量的 prompt 进行测试,避免采用过于简单的示例性问题。然后将两个响应并排对比:哪个回答更准确?哪个更完整?质量差距是否足以显著影响你的应用场景?
API 测试工具还能呈现驱动成本决策的关键数据:观察每次调用的延迟,直接从每个响应中读取 token 使用情况(包括输入和输出计数)。将两个模型的使用情况与质量差异结合起来评估,2 倍的溢价便不再抽象。通过真实 prompt 的检验,你就能判断 Fable 5 的输出是否值得额外的 token 和金钱投入,或者 Opus 4.8 是否已完全胜任。将这两个请求保存为一个小型集合,你就拥有了一套可重复的 A/B 测试框架,每次 prompt 变更或新模型发布时均可重新运行。这比再读一份规格表更能让你快速获得确定性的答案。