PostgreSQL 19 Beta 1 昨晚正式发布了。最近仔细啃了一遍 release notes,这里把几个值得关注的新特性拎出来聊聊——它们对现有生产系统是启发多还是隐患多,值得提前掂量一下。
- 参数 JIT 默认关闭
- checksums 在线启停
- 组合事务号回卷被终结
- autovacuum 并行且分主次
- 升级迁移的最后一公里 + 最后 100 米
- 安全链路连接支持多域名证书
- 逻辑复制补齐序列
- 优化器重新支持被短路的分支
一、参数 JIT 默认保持关闭
v19 有两个参数值发生了显著变化:
jit = off
default_toast_compression = lz4
其实 v14 就开始推荐使用 lz4 压缩 toas 字段了,v19 正式把默认值从 pglz 切到了 lz4,不过编译时得带上 --with-lz4 选项。
JIT(即时编译)从 v11 引入时可是个重磅特性,它借助 LLVM 提升 WHERE 条件、目标列表、聚合以及内部操作的表达式执行速度。要启用它,先得装好 LLVM,然后源码编译时加上 --with-llvm。从 v12 到 v18,jit 参数默认都是 on。
但社区收集了大量用户反馈后发现,在偏 OLTP 的场景下 JIT 很难带来明显收益,所以 v19 索性把它默认关掉了,OLAP 场景需要手工开启。release notes 里原话是这样描述的:

二、checksums 在线启停
以前需要开启 checksums 来校验数据文件块的完整性时,生产环境只能 offline 操作——先停库,再启用:
- offline
$ pg_ctl stop -D PGDATA
$ pg_checksums --enable -D PGDATA
要不要默认开启 checksums,或者 initdb 时强制开启,社区已经争论了好几个大版本。v19 借助 CPU 硬件加速实现了 checksums 的高效处理:

并提供了 SQL 接口函数,支持在线平稳启停:
- online
SQL function:pg_enable_data_checksums()
SQL function:pg_disable_data_checksums()
同时 data_checksums 的观测值变成了 on、off、inprogress-on、inprogress-off。调用这两个函数期间,会有短暂的窗口能观察到中间状态。
三、组合事务号回卷被终结
事务号回卷对数据库来说就像灾难降临。当前的 autovacuum 会根据系统资源情况进行预警或自救:
- 当事务号资源剩余 1 亿时,数据库日志会发出预警(v19 之前是 4000 万)
- 当事务号资源剩余 300 万时,触发安全边界,数据库只读不写,自救启动
ERROR: database is not accepting commands ..
这是从事务号资源的角度看。而从表上死元组的清理年龄角度,反映的是同一件事:

从表格的两列参数对比可以清晰看到,组合事务与普通事务是两条独立的线脉,处理机制类似。

但组合事务回卷的问题在 v19 算是被终结了。社区收到了真实用户反馈和验证,32 位组合事务确实很容易消耗殆尽引发故障。v19 把它加宽到了 64 位,并新增了 pg_get_multixact_stats() 函数来监控组合事务的统计信息:
select * from pg_get_multixact_stats();
-[ RECORD 1 ]----+-----
num_mxids | 207
num_members | 452
members_size | 2260
oldest_multixact | 1
当然,普通事务依然是 32 位,社区认为大多数常规场合没那么容易消耗完 21 亿资源。
四、autovacuum 并行且分主次
手工 VACUUM 从 v13 开始就已经支持并行能力:
19=# VACUUM (VERBOSE, PARALLEL 3) t;
INFO: vacuuming "evantest.public.t"
INFO: launched 2 parallel vacuum workers for index vacuuming (planned: 2)
...
parallel workers: index vacuum: 2 planned, 2 launched in total
...
memory usage: dead item storage 2.00 MB accumulated across 1 reset (limit 64.00 MB each)
...
v19 把同一套并行机制应用到了 autovacuum 上:针对单表的索引清理阶段可以并行化。前期的 Heap Scan 和后期的 Heap Truncation 两个流程仍然未并行化。举个例子,一张表有 N 个索引,可以将这些索引分配给 N 个 Worker 同时清理。控制参数是 autovacuum_max_parallel_workers 以及表级参数 autovacuum_parallel_workers。
生产环境里另一个 autovacuum 的难题是:某个核心表膨胀了,却因为等待队列排队迟迟清理不了。以往的 autovacuum 收集需要处理的表清单是先进先出、后进后出原则。v19 引入了 score 机制来解决排队问题:根据 insert、analyze、xmin、frozenxid 等因子打分,按重要性来处理:
select * from pg_stat_autovacuum_scores where relname='tab';
-[ RECORD 1 ]-------+---------------------
relid | 16472
schemaname | public
relname | tab
score | 0.01996008044823684
xid_score | 0.00028279
mxid_score | 5.175e-07
vacuum_score | 0
vacuum_insert_score | 0.000999800027789852
analyze_score | 0.01996008044823684
do_vacuum | f
do_analyze | f
for_wraparound | f
五、升级迁移的最后一公里 + 最后 100 米
以前用 pg_upgrade 进行大版本升级后,还得手工更新统计信息,例如:
vacuumdb --all --analyze-in-stages
v18 增加了两个系统函数来恢复表对象和表字段的基本统计信息:
SELECT * FROM pg_catalog.pg_restore_relation_stats(
'version', '180000'::integer,
'schemaname', 'public',
'relname', 'tab1',
'relpages', '345'::integer,
'reltuples', '10000'::real,
'relallvisible', '345'::integer,
'relallfrozen', '0'::integer
);
SELECT * FROM pg_catalog.pg_restore_attribute_stats(
'version', '180000'::integer,
'schemaname', 'public',
'relname', 'tab1',
'attname', 'col',
'inherited', 'f'::boolean,
'null_frac', '0'::real,
'a vg_width', '4'::integer,
'n_distinct', '100'::real,
'most_common_vals', '{1,..}'::text,
'most_common_freqs', '{0.01,..}'::real[],
'correlation', '0.009082272'::real
);
pg_dump 工具使用 --statistics-only 封装调用接口,这样 pg_upgrade 可以自动恢复基本统计信息。但用户如果创建了扩展统计信息(例如 CREATE STATISTICS test_stats (ndistinct, dependencies, mcv) ON id, descr FROM test;),升级后仍然需要手工处理。
v19 紧接着打通了最后 100 米——增加了 pg_restore_extended_stats() 系统函数来恢复扩展统计信息:
SELECT * FROM pg_catalog.pg_restore_extended_stats(
'version', '190000'::integer,
'schemaname', 'public',
'relname', 'test',
'statistics_schemaname', 'public',
'statistics_name', 'test_stats',
'inherited', 'f'::boolean,
'n_distinct', '[{"attributes": [1, 2], "ndistinct": 1}]'::pg_ndistinct,
'dependencies', '[{"attributes": [1], "dependency": 2, "degree": 1.000000}, {"attributes": [2], "dependency": 1, "degree": 1.000000}]'::pg_dependencies,
'most_common_vals', '{{1,a}}'::text[],
'most_common_freqs', '{1}'::doubleprecision[],
'most_common_base_freqs', '{1}'::doubleprecision[]
);
六、安全链路连接支持多域名证书
v19 给服务端加上了 SNI(Server Name Indication)支持。没有 SNI 之前,使用 SSL 时一个数据库实例只能绑定一个域名一套证书,不同 hostname 无法使用不同的 TLS 证书。其实 v14 已经在客户端层面支持发送 SNI,但那是铺垫性工作,服务端会忽略它。v19 终于把服务端的能力补齐了,支持多域名证书:

服务端的实现机制:
- 通过 GUC 参数
ssl_sni进行开关控制
dconfig+x ssl_sni
List of configuration parameters
-[ RECORD 1 ]-----+--------
Parameter | ssl_sni
Value | off
Type | bool
Context | sighup
Access privileges |
- 通过
pg_hosts.conf配置文件进行映射

当客户端发起 TLS 请求,服务端接收并回调,提取 hostname,然后查询 pg_hosts.conf,再切换到不同的证书和密钥文件。
七、逻辑复制补齐序列
逻辑复制从 v10 发布以来,每个大版本都在持续迭代功能和提升稳定性。2024 年曾有一篇文章详细介绍过逻辑复制从 v10 到 v16 的七大工艺,但限制依然不少:不支持 DDL、仅支持大事务并行应用、不支持并行解码、不支持单表粒度开启逻辑复制等等。
v19 终于补齐了长久以来缺失的序列支持:

此外 v19 还对逻辑复制做了多项改进,包括:
-
动态调整 WAL LEVEL:需要使用逻辑复制时 WAL LEVEL 自动增强为
logical,不使用时自动降级为replica。 -
为 REPACK (CONCURRENTLY) 提供技术支撑
-
发布端支持黑名单列表(
EXCEPT通常搭配FOR ALL TABLES使用)
CREATE PUBLICATION p1
FOR ALL TABLESEXCEPT TABLE public.audit_log, public.session_cache;
- 订阅端连接串可使用 FDW server 统一管理
八、优化器重新支持被短路的分支
这个特性比较隐蔽。release notes 里的描述是:
打开提交链接,标题是:
这个提交标题的描述和 release notes 里的描述有点不一样,尤其是 "Re-allow" 这个词——重新允许、重新支持。翻译过来就是:优化器重新支持被短路的布尔值分支。
这事要从 v12 讲起。v12 给函数增加了一个 support 特性,能让优化器更准确地预估行数。因为函数对优化器来说像黑盒,基本不可见,典型场景是 Function Scan 预估的行数不准:

没有 support 属性时,函数只能依赖 pg_proc 中固定的 procost 和 prorows。v12 引入 support 属性的同时,也短路了某条老路径——也就是 boolvarsel 分支。
下面这张图(GPT 辅助生成)清晰地展示了短路逻辑:
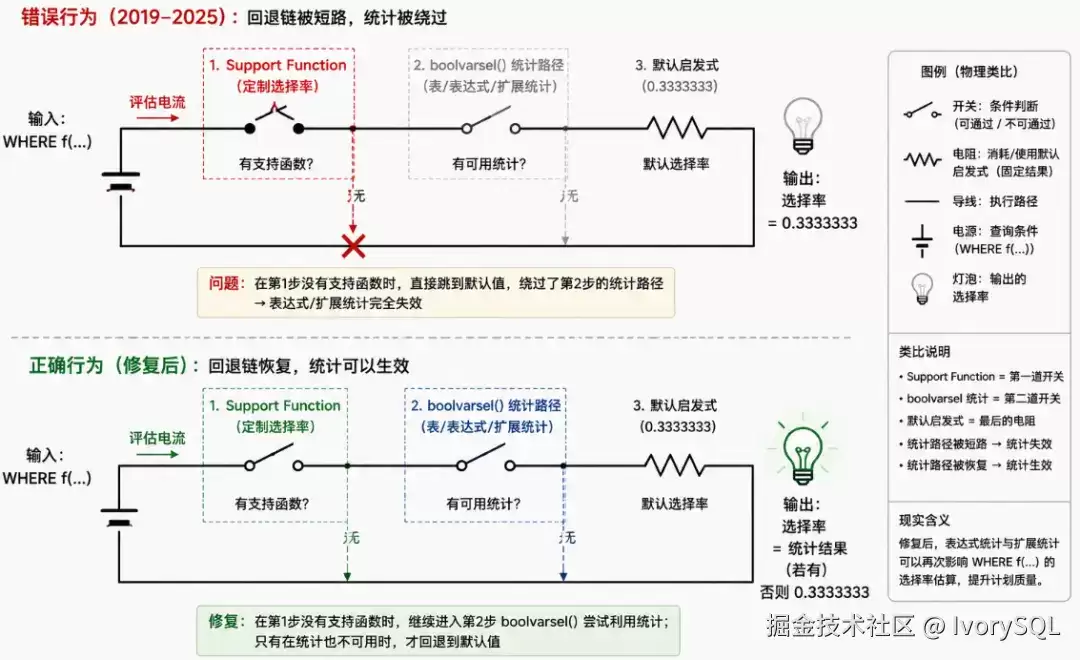
简单说,v12 引入 support function 的同时也埋下了一个隐藏 bug。6 年后的今天,社区终于修复了它。所以提交标题很诚实:WHERE 条件中的 bool-valued 函数被短路、不能使用统计信息的这个分支场景,如今可以重新使用了。
这个 bug 分支非常隐蔽,用户很难主动发现。触发条件需要满足:使用了 bool-valued function、存在表达式或扩展统计信息、同时函数没有 support 属性。
注:boolvarsel 是数据库内部函数,用于布尔表达式选择率估算。
PS:release notes 里的重头笔都在描绘优化器,其中也不乏一些 bug fix 的特性,还有一个貌似也像:




