先说几点核心判断。智能体从原型迈向生产环境的最大鸿沟,从来不是“一次性跑通”——这谁都做得到。真正令人头疼的是:它能否实现长期稳定运行?能否承受分布式部署的复杂性?多租户隔离应该如何落地?这些在原型阶段根本看不见的挑战,一旦进入企业真实场景,一个都不会缺席。
AgentScope Ja va 2.0 本次升级,正是直击这些真实场景中的“硬骨头”。作为 AgentScope 多语言体系面向 JVM 生态的关键组件,它延续了 1.0 版本“透明开发”的核心理念——让开发者能清晰洞察智能体每一步的决策——但将重心彻底转向工程层面:稳定运行、安全管控、分布式部署、企业级接入。简而言之,它的目标是让智能体在企业环境中“可靠地持续运行”,而非“漂亮地一次性演示”。
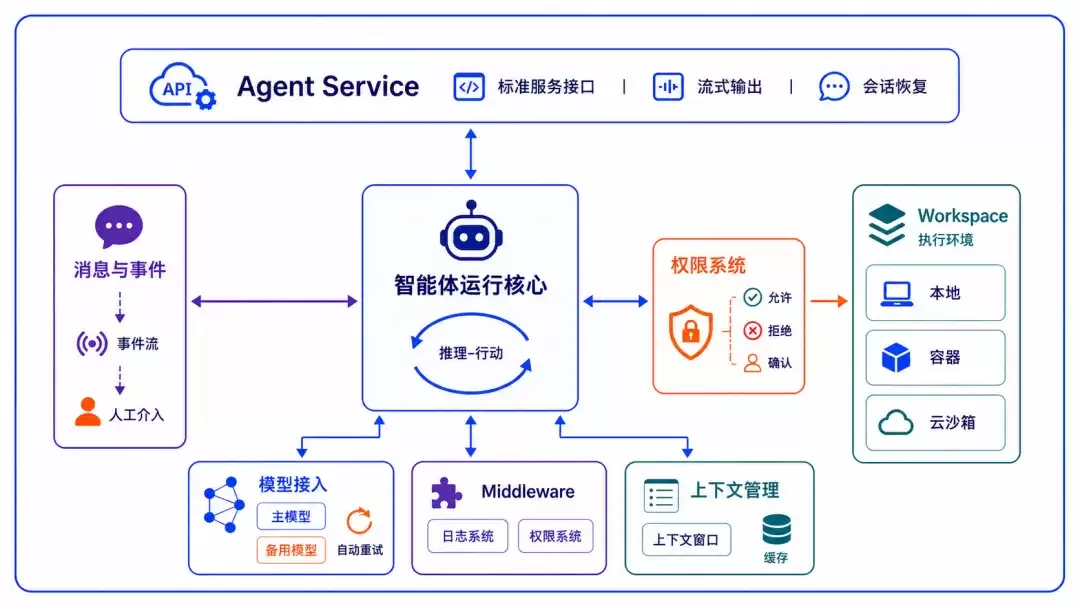
企业级分布式部署:无状态水平扩展、零停机发布、多租户隔离
真正考验一个智能体框架的,并非单次 Agent 调用的响应速度,而是 Agent 部署上线后能否长期稳住。AgentScope Ja va 2.0 将分布式部署作为框架的一等公民——开发者编写同一份业务代码,按需切换至分布式形态,任意一个副本都能恢复任意用户的完整上下文。
首先谈会话与沙箱的管理。在单机开发阶段,会话状态默认保存在本地 workspace 目录,零配置即可开箱即用。进入生产环境后,只需将状态后端切换为分布式存储——对话历史、上下文摘要、计划进度、待办清单、权限规则等运行时状态全部外置——任何副本都能获取完整快照并继续执行。如需启用沙箱,还需更进一步:智能体在容器中积累的可执行环境(如克隆的代码仓库、安装的依赖、临时文件)会在每次调用结束时打包成快照,存储至对象存储或 Redis。当容器漂移到其他节点,下一次调用能从快照中重建出完全一致的工作区,用户完全感知不到节点切换。框架在装配阶段会校验配置一致性——一旦启用沙箱或远端存储却未将会话状态也切换为分布式后端,启动时即报错,避免上线后才发现状态丢失。
再论多租户隔离,它贯穿整个执行链路。RuntimeContext 中的 userId 和 sessionId 不仅是日志字段——它们直接参与工作区路径、KV 命名空间、沙箱环境的资源寻址。开发者只需按业务语义选择隔离粒度:每段对话各自独立、同一用户的多轮会话共享工作区、公共工具型智能体全员共享,或全局共享。框架将“谁能访问谁的数据”这一核心约束交由系统强制实施,无需依赖业务代码的自觉性。
最后是文件系统层的统一抽象。智能体的所有文件操作——读写、检索、上传下载——均通过一层 AbstractFilesystem 抽象进行收敛。每次调用自动携带当前会话与用户身份信息,框架据此将读写动作隔离至对应租户的命名空间。本地磁盘、容器沙箱、远端存储三类后端共用同一套上层语义,这意味着开发→测试→生产的三段部署路径无需修改代码。业务代码、工具集、智能体逻辑保持不变,部署时仅切换底层存储后端即可。
这些设计并非孤立的开关,而是 AgentScope Ja va 2.0 为企业级部署配套的三层相互支撑的抽象。下面通过 Harness、Workspace、Context 几个核心概念展开详细说明。
Harness:将“长期稳定运行”沉淀为框架内核实现
Ja va 版 AgentScope 2.0 引入了一个核心抽象:HarnessAgent。它是 ReActAgent 之上的工程化封装——核心的 ReAct 推理循环完整保留,但围绕长期稳定运行所需的工作区、长期记忆、上下文压缩、子智能体编排、沙箱隔离、计划模式等工程能力,全部打包进一个 builder。开发者从 ReActAgent 起步,需要长期稳定运行时即可无缝迁移至 HarnessAgent,业务代码无需改动。
AgentScope Ja va 2.0 的设计目标十分直接:ReActAgent 提供 Agent loop 抽象和所有底层原子能力,而 HarnessAgent 则提供保障效果、稳定性、分布式部署、长期运行的一站式解决方案。它对应的并非某项新模型能力,而是真实生产场景中那些“上线前看不到、上线后绕不开”的工程问题——身份持续注入、上下文规模可控、状态可恢复、能力可沉淀。这些问题在原型阶段几乎不存在,但在企业部署中几乎成为全部。Harness 在不改写推理循环的前提下,将这些问题的解法以 middleware 和 toolkit 的形式叠加到关键时机上——只叠加,不替换。
后续章节将展开 Harness 各项能力背后的工程取舍。现在可以先把 Harness 理解为:让 Ja va 开发者使用熟悉的 builder 范式,将一套“长期运行 Agent 必备的工程基础设施”以增量、可叠加、可替换的方式接入项目。
Workspace:实现执行环境与 Agent 逻辑的解耦
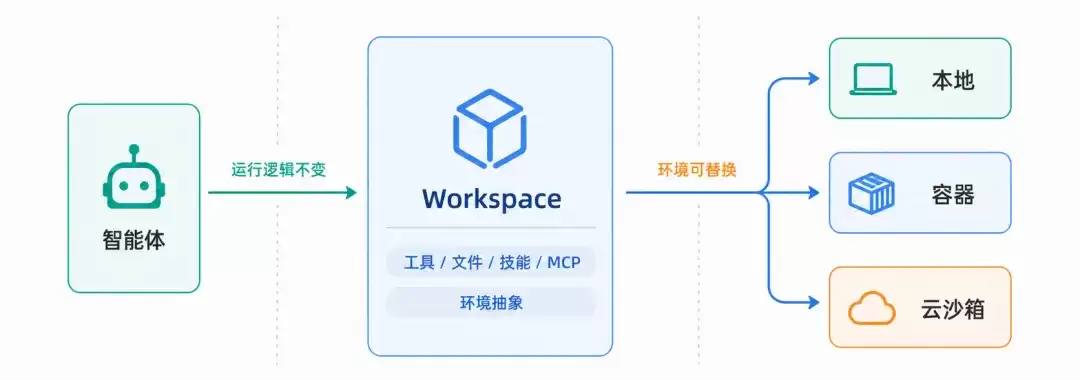
智能体在长期运行中需要持续读写文件、加载技能、连接 MCP 服务、保存对话状态。如果“智能体要做什么”与“它在哪里读写”绑定在一起,那么从本地切换到容器、再切换到云端,就需要逐处适配。
AgentScope Ja va 2.0 将此拆分为两层正交的抽象——工作区作为逻辑视图,抽象文件系统作为物理载体。前者定义了“智能体的资源长什么样”,后者决定了“这些资源真正落在哪里”,两者通过一套统一的目录布局实现解耦。
工作区是智能体执行环境的逻辑视图。它将智能体长期运行所需的全部资源——人格设定、长期记忆、领域知识、可复用技能、子智能体声明、工具与 MCP 白名单,以及运行时产出的会话快照与对话日志——统一组织成磁盘上的一套标准化目录结构。每轮推理时,框架会按需将这些资源拼入 system prompt。开发者只需将工作区版本化进 Git,智能体的“配置”便拥有了 PR、CR 和版本号,修改文件即升级智能体,无需重启服务或改动一行业务代码。这层抽象的关键在于:智能体本身不依赖任何具体存储,它看到的始终是一个统一的文件视图。至于这些文件实际存储在何处,由部署侧决定。
抽象文件系统是工作区的物理存储载体。同一份工作区的目录布局,可背后挂载三类不同的存储后端,开发者只需在部署阶段选择一种:
三种模式之上是同一套统一的文件系统语义。每一次读写都会自动携带当前会话与用户的身份信息,由框架将数据隔离到对应租户的命名空间——多租户隔离被推到底层强制约束,业务侧无需再自行实现。如果业务上需要将“只读的团队知识库”叠加在“可写的会话工作区”之上,框架也支持这种分层组合,用共享底座承载共性、上层私有空间承载个性化状态。
这种“逻辑视图/物理载体”的两层拆分,使得开发→测试→生产的三段路径无需修改代码。同一份智能体实现,按环境切换底层存储即可在本地磁盘、容器沙箱、远端存储之间自由迁移。对企业落地而言,这是将“一次写好的智能体能跨环境运行”从口号变为默认行为的关键一步。
Context:支撑长期任务的上下文管理机制
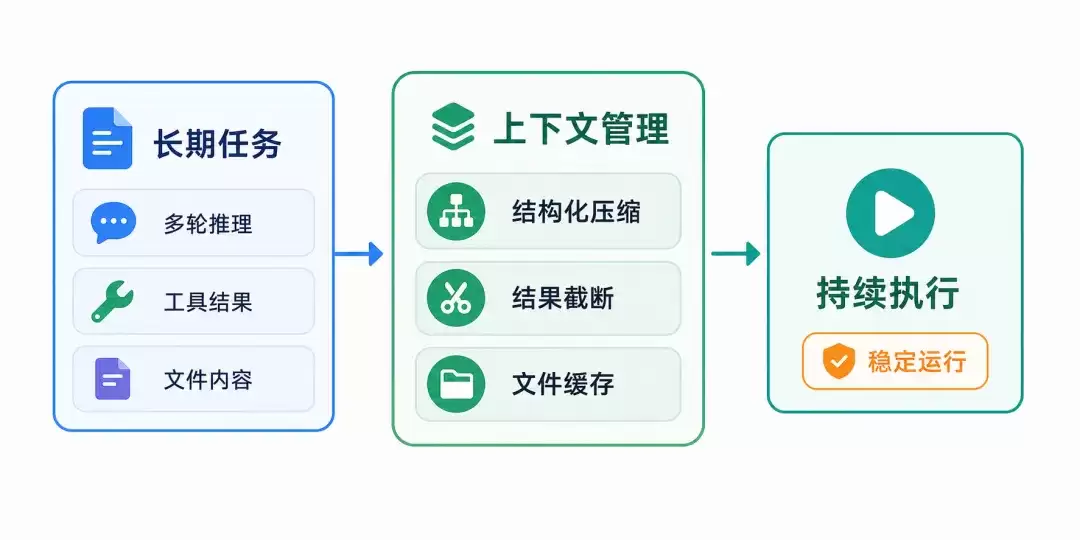
处理长期任务是智能体应用走向真实场景时绕不开的一环。一个长期任务可能包含多轮模型调用、多个工具结果、大量文件内容和用户反馈。如果上下文管理仅停留在“将历史压缩进窗口”这一层,很快就会发现:哪些信息应保留、哪些工具结果需截断、文件内容如何避免重复读取、任务状态如何在长链路执行中持续延续——这些问题会逐一浮现。
AgentScope 1.0 已提供上下文管理能力;到了 2.0,这部分能力进一步系统化。AgentScope 2.0 会结合任务状态、工具结果和文件读写过程管理上下文:压缩结果不只是简单摘要,而是结构化保留任务目标、当前状态、关键发现、下一步计划和需长期保留的信息;超大工具结果(如动辄几十 K 字符的 git diff、mvn test 输出、搜索结果)会被自动卸载到工作区,上下文里仅保留首尾摘要加一个 read_file 路径占位符;内置文件读写工具也加入了文件缓存机制,减少重复 IO,并要求编辑现有文件前先读取文件内容,从而提升性能和操作可靠性;当真正遇到模型 context_length_exceeded 时,框架还会自动触发兜底压缩重试,避免任务直接在边界处中断。
因此,上下文管理在 AgentScope 2.0 中不只是“压缩历史”,而是升级为支撑长期任务执行的系统策略。它让智能体能够更有条理地维护任务状态、控制上下文规模,并在持续推理和多次调用工具的过程中保持稳定。
模型接入:在开放生态之上,增强容错能力
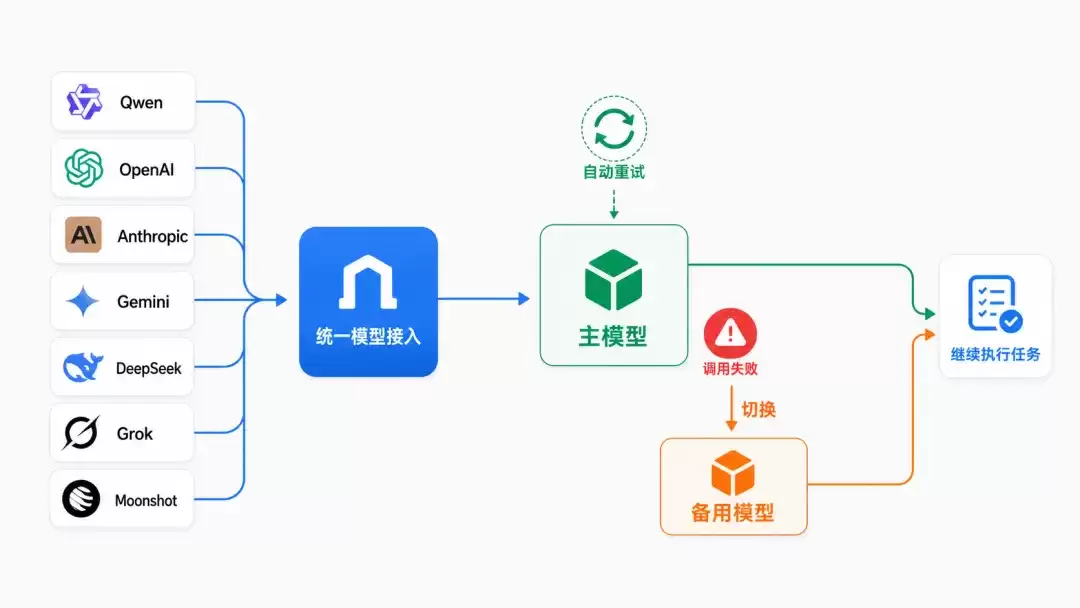
AgentScope 2.0 继续保持开放的模型接入能力。OpenAI?没问题。DeepSeek?可以。Qwen 和 Anthropic 也同样支持。但 2.0 的重点不是“又接了几个新模型”——而是让模型调用在复杂任务中尽可能少出问题。
真实任务中,Agent 往往需要多轮推理和多次工具调用。任何一次模型接口失败、超时或不可用,都可能使整个后续执行中断。为此,AgentScope Ja va 2.0 在模型层引入了统一的 Credential 和 ChatModel 抽象,每个厂商都是同一套 builder 背后的一份独立实现。并在此之上提供统一的重试与备用模型机制——通过 FallbackModel 包裹主模型,开发者可配置最大重试次数和备用模型链,主模型不可用、限流或过载时框架自动透明切换,尽可能保持任务执行的连续性。
模型接入部分的升级,使 Agent 不只是“能调用模型”,而是具备了更稳健的模型运行策略。对于需要持续推理和多步执行的任务而言,模型层的稳定性也成了 Agent 能否顺利完成任务的重要基础。
消息与事件:从聊天消息升级为可交互执行流
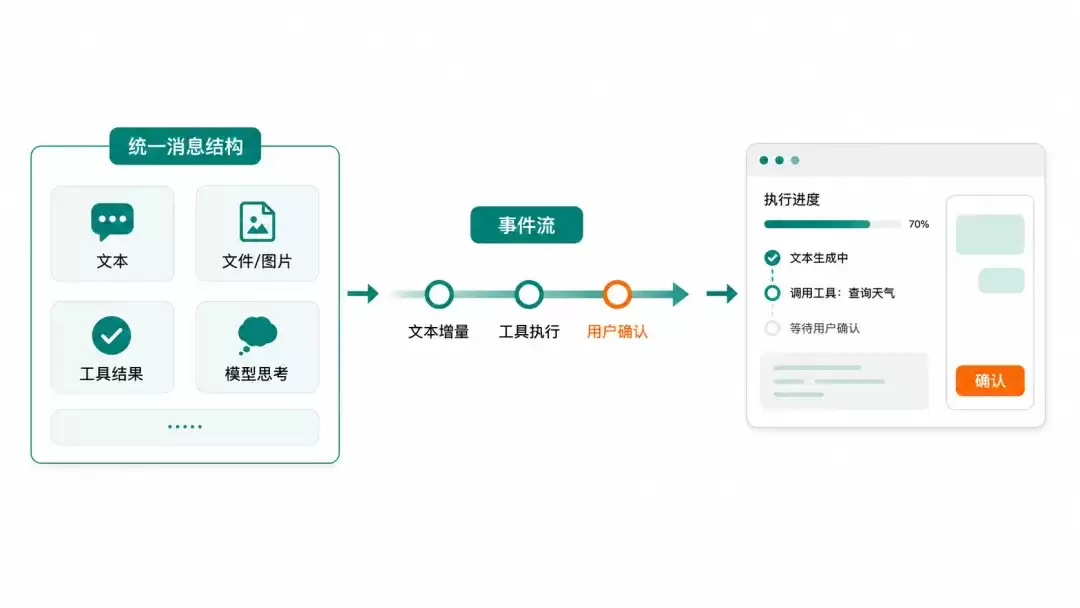
智能体应用的复杂度也体现在消息上。普通聊天应用中,消息可能只是字符串;但在智能体执行过程中,一条消息里可能同时包含文本、图片、文件、工具调用、工具结果、模型思考、用户确认状态、外部执行结果等。AgentScope 2.0 对消息模块进行了重构,通过统一的 ContentBlock 承载以上不同的消息类型,并在 Ja va 侧借助 sealed class 与 record 将每一种 block 表达为强类型——非法的 role × content 组合在构造期即被拦截,而非运行时才报错。其中,DataBlock 同时兼容 base64 与 URL 两类数据源,可更好地适配不同模型 API 的多模态与文件能力。
在此基础上,AgentScope 2.0 引入了事件系统。一次 call() 不再仅返回最终文本,而是可通过 streamEvents() 流式产生模型调用开始、文本增量、工具调用、工具结果、用户确认、外部执行等类型化事件——基于 Project Reactor 的 Flux 输出,前端 UI 直接订阅即可实时跟随,无需手动 diff 或轮询。这使人工确认、人工介入和外部工具执行成为框架的内生能力。例如,当智能体要执行某个敏感工具时,可触发用户确认;当工具需在外部环境中执行时,也可等待外部执行结果后继续任务。
因此,消息模块与事件系统的升级,不仅延续了 AgentScope 对“透明”的强调,也让智能体的执行过程变得可展示、可交互、可干预。开发者看到的不仅是最终答案,而是一个可以被持续观察和持续推进的智能体执行过程。
权限系统:为自主执行划定清晰边界
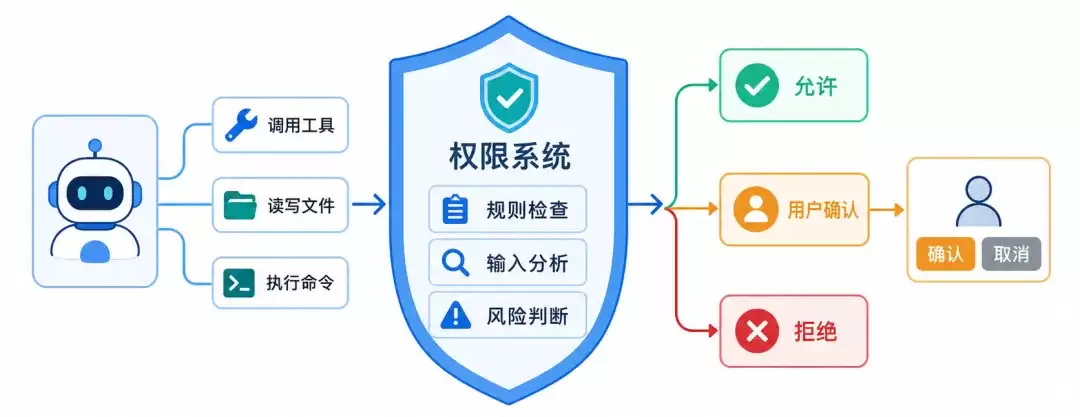
为了充分发挥大模型的潜力,智能体需要拥有更强的自主性:它不只被动地产生回应,还能根据任务进展主动选择工具、读取信息、执行操作。但智能体越能自主行动,就越需要明确的权限边界——尤其是在企业环境中,触发智能体的可能是任意一位员工或外部用户,宿主系统必须假设输入不可信。
AgentScope 2.0 引入了更加系统化的权限系统,用于控制智能体在调用工具、读写文件、执行命令时的行为边界。工具调用不再是简单的允许或禁止,而是基于静态规则、工具类型和输入内容综合判断:“允许 / 用户审批 / 拒绝”三态决策。例如,文件读写工具会检查是否涉及危险目录和敏感文件;命令执行工具会分析高风险命令、动态 shell 结构和危险删除操作;对于未知或高风险行为,框架会自动进入用户审批流程(HITL),将决策权交回给用户。
权限系统的引入,让智能体不只是“能调用工具”,而是能够在清晰可控的边界内自主执行任务。对于需要持续使用工具、访问文件或执行命令的复杂任务而言,安全边界也成为智能体能否稳定完成任务的重要基础。
Middleware:使框架扩展更灵活
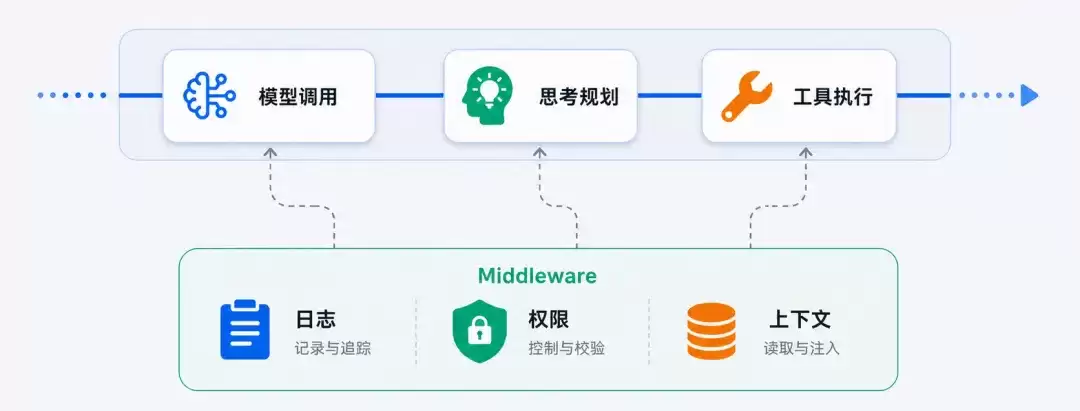
真实场景中的智能体往往需要接入不同的日志记录、权限策略、业务上下文和模型调用策略。如果这些能力都需通过修改框架内部实现来完成,扩展成本会很高,也会影响框架本身的稳定性。
AgentScope Ja va 2.0 引入了 middleware 机制,将原本松散的 Hook 列表收敛为五个清晰阶段——onAgent / onReasoning / onActing / onModelCall / onSystemPrompt。开发者可在 Agent 的关键执行环节插入自定义逻辑:模型调用前后的日志追踪与限流,工具执行前的安全检查,reasoning 与 acting 流程中的业务策略,以及 system prompt 构造阶段的动态上下文注入。每个关注点各居其层,组合起来干净利落。通过 middleware,AgentScope 2.0 可在保持核心框架稳定的同时,为不同应用场景留下足够灵活的扩展空间——这也延续了 1.0 的透明理念:框架不是黑盒,开发者可以清晰地理解它、介入它。
总结:AgentScope 2.0 打造企业级生产底座
AgentScope Ja va 2.0 本次升级,核心可以凝练为一句话:让智能体在企业环境中可靠运行。从模型层的容错切换,到执行环境的抽象解耦;从细粒度的权限边界,到分布式 Session 与沙箱快照;从结构化的事件流式输出,到多租户隔离与可观测体系。这些升级系统性地回应了真实场景中智能体长期运行、安全调用工具、持续推进任务、跨副本恢复和接入外部应用的共同需求。
AgentScope Ja va 2.0,为企业级智能体应用提供更坚实的系统底座。




