第七部分:深入理解NoSQL数据库与混合持久化架构
关系型数据库并非万能解决方案,在特定应用场景下,NoSQL数据库能够提供更优异的性能与灵活性。对于进阶开发者而言,核心在于掌握各类数据库的适用场景,并依据实际业务需求进行组合运用——这正是混合持久化架构(Polyglot Persistence)的精髓所在。
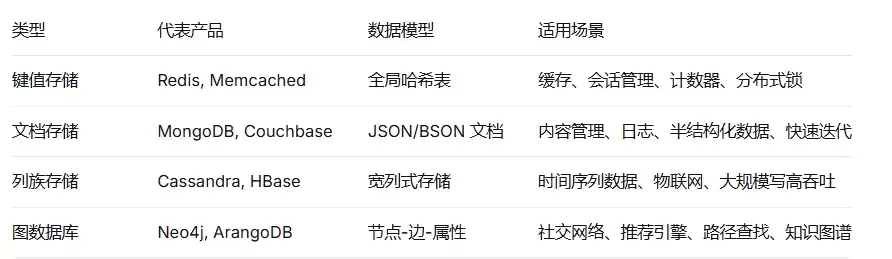
7.1 常见NoSQL分类与选型指南
7.2 Redis高级用法与持久化机制
许多开发者提到Redis只想到缓存,实际上它完全可以胜任主数据库或消息队列的角色。
7.2.1 数据结构的高级使用
哈希表(Hash)用于存储对象,相较于分散的多键方案更为优雅;有序集合(Sorted Set)天然适合实现排行榜功能;位图(Bitmap)统计日活跃用户则极为节省空间,每位用户仅占用1位。以下是几个典型用法示例:
# 哈希表存储对象(优于多key)
HSET user:1001 name "Alice" age 30
HGETALL user:1001
# 有序集合做排行榜
ZADD leaderboard 100 "playerA" 95 "playerB"
ZREVRANGE leaderboard 0 2 WITHSCORES
# 位图统计日活(每个用户占用1位)
SETBIT login:2025-06-01 1001 1
BITCOUNT login:2025-06-017.2.2 持久化机制
RDB采用快照方式,定期生成全量备份,恢复速度较快,但存在丢失最近一次快照后数据的风险。AOF则通过追加写命令日志实现持久化,安全性更高(可配置每秒fsync),然而文件体积较大且恢复较慢。生产环境中通常同时启用两者,或直接采用Redis Enterprise提供的持久化方案。
7.2.3 高可用与集群
Redis Sentinel实现主从自动切换,确保高可用性;Redis Cluster采用分片方案,支持横向扩展,但部分跨键操作可能受限。具体选择哪种方案,需根据业务规模及对一致性的要求来决定。
7.3 MongoDB的索引与聚合框架
MongoDB的索引机制与关系型数据库有相似之处,但还额外支持嵌套字段索引、地理空间索引、全文索引等特色功能。其聚合框架替代了复杂的分组与连接操作,通过管道(如 $match、$group、$lookup)处理数据,灵活性极高。例如,统计每个商品销量前10的用户:
db.orders.aggregate([
{ $match: { status: "completed" } },
{ $group: { _id: { productId: "$product_id", userId: "$user_id" }, total: { $sum: "$amount" } } },
{ $sort: { total: -1 } },
{ $group: { _id: "$_id.productId", topUsers: { $push: { userId: "$_id.userId", total: "$total" } } } },
{ $project: { topUsers: { $slice: ["$topUsers", 10] } } }
]);7.4 混合持久化架构示例
模拟一个典型的电商系统:
- MySQL:承载核心订单与用户账户——这些场景强事务与强一致性是底线。
- Redis:缓存商品详情、用户会话、秒杀库存计数器——追求极速响应。
- Elasticsearch:商品搜索与日志分析——严格来说并非标准NoSQL,但与数据库配合使用非常普遍。
- Cassandra:存储用户行为流水与点击流——写吞吐量极高,且支持线性扩展。
应用层依据业务规则决定数据写入的目标存储,同时妥善处理最终一致性问题,例如先写入MySQL,再异步同步至Elasticsearch。这才是真正的全栈数据架构思维。
第八部分:数据库进阶实战 —— 一个完整案例
首先明确核心思路:通过一个典型的“排名系统”串联前面所有知识点。需求十分简单——实现一个游戏排行榜,能够实时更新玩家得分、高效查询前100名,同时支持查询玩家自身的排名。
8.1 方案一:关系数据库 + 索引优化
表结构如下:
CREATE TABLE scores (
user_id INT PRIMARY KEY,
score INT NOT NULL,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
INDEX idx_score (score DESC)
);查询前100名可直接使用 ORDER BY + LIMIT,效率较高。但查询某个玩家的排名则较为棘手——需要借助子查询 + COUNT,在数据量较大时性能堪忧。此外,实时更新排名需频繁写入操作,该方案较适合中等规模(千万条以内)的数据量。
8.2 方案二:使用Redis有序集合
ZADD leaderboard 1500 playerA
ZADD leaderboard 2800 playerB
ZREVRANGE leaderboard 0 99 WITHSCORES # 前100名
ZREVRANK leaderboard playerB # 获取排名(0-based)Redis的操作均为 O(log N) 复杂度,百万级玩家轻松应对,天然支持实时更新。唯一的缺点是内存成本较高,数据量过大时成本会剧增。常用的应对策略是冷热分离——活跃玩家数据存放在Redis,历史玩家数据回迁至MySQL。
8.3 方案三:基于数据库的分区 + 缓存
如果坚持使用MySQL,可以按score范围进行分区,例如每1000分一个分区。这样查询前100名时只需扫描高分区的前几页。同时配合Redis作为查询缓存,在score更新时使缓存失效。这是一个折中但稳健的方案。
8.4 完整代码实现(应用层逻辑)
以下使用Python实现排行榜服务,包含缓存策略与降级方案:
import redis
import pymysql
import json
class LeaderboardService:
def __init__(self):
self.redis_client = redis.Redis(host='localhost', port=6379, db=0)
self.db = pymysql.connect(host='localhost', user='app', password='xxx', database='game')
def update_score(self, user_id, new_score):
# 先更新数据库
with self.db.cursor() as cursor:
cursor.execute(
"INSERT INTO scores (user_id, score) VALUES (%s, %s) ON DUPLICATE KEY UPDATE score = %s",
(user_id, new_score, new_score)
)
self.db.commit()
# 再更新Redis
self.redis_client.zadd('leaderboard', {user_id: new_score})
# 删除该用户的缓存排名(懒加载)
self.redis_client.delete(f'rank:{user_id}')
def get_top_n(self, n=100):
# 优先从Redis读取,不存在则从MySQL回源并写入缓存
cached = self.redis_client.get(f'top_{n}')
if cached:
return json.loads(cached)
with self.db.cursor() as cursor:
cursor.execute("SELECT user_id, score FROM scores ORDER BY score DESC LIMIT %s", (n,))
rows = cursor.fetchall()
result = [{'user_id': r[0], 'score': r[1]} for r in rows]
# 缓存60秒,避免频繁穿透
self.redis_client.setex(f'top_{n}', 60, json.dumps(result))
# 同时预热Redis ZSET(如果Redis内存允许)
for r in rows:
self.redis_client.zadd('leaderboard', {r[0]: r[1]})
return result
def get_user_rank(self, user_id):
# 先尝试从Redis ZSET获取
rank = self.redis_client.zrevrank('leaderboard', user_id)
if rank is not None:
return rank + 1
# 降级查数据库
with self.db.cursor() as cursor:
cursor.execute(
"SELECT COUNT(*) + 1 FROM scores WHERE score > (SELECT score FROM scores WHERE user_id=%s)",
(user_id,)
)
rank = cursor.fetchone()[0]
# 回填到Redis
self.redis_client.zadd('leaderboard', {user_id: self._get_user_score_from_db(user_id)})
return rank需要牢记,数据库是系统的核心,任何疏忽都可能导致严重事故。每次对数据库的变更——添加索引、修改表结构、调整参数——都应在测试环境充分验证,并制定灰度上线与回滚方案作为保障。以敬畏之心对待数据,以科学之眼分析性能,这才是成为真正数据库专家的必经之路。




