基于ResNet50的鱼类识别系统设计
海洋生物多样性的监测与保护,如今正日益依赖自动化智能技术。鱼类识别看似简单,实则关乎渔业管理、生态研究等多个领域的实际需求。传统方法依赖专家肉眼鉴定,效率低下且主观性较强。而深度学习,尤其是卷积神经网络(CNN)的成熟,为这一领域带来了全新的解决思路。本文介绍的是一套基于ResNet50的鱼类识别系统设计方案——通过对经典模型进行微调,并结合合理的数据处理流程,最终实现较高精度的自动分类,能够适应多种真实场景。
1 引言
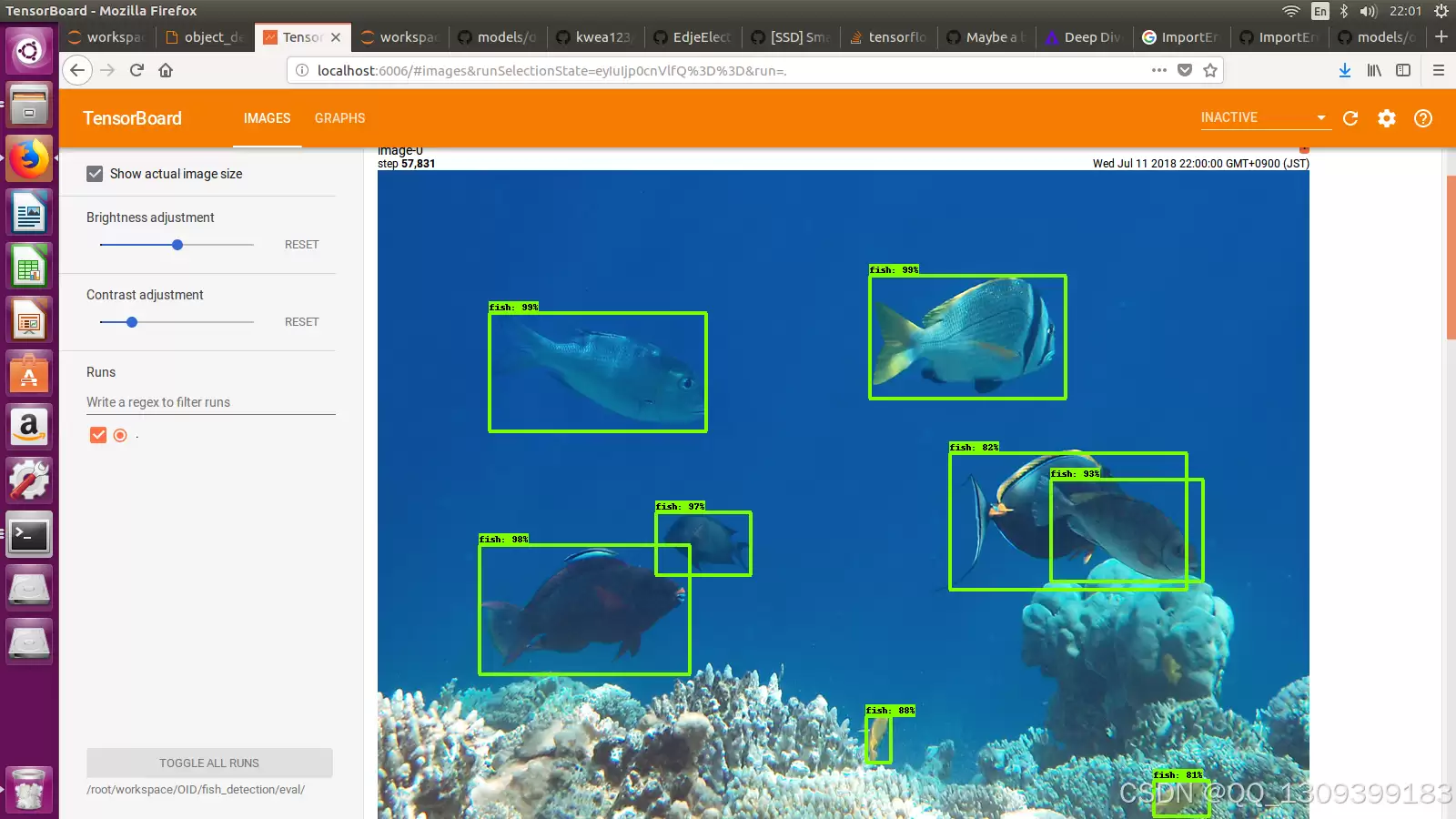
鱼类识别是水生生态系统监测的关键环节。传统的识别手段高度依赖专家经验,既消耗人力,又难免受到主观判断的影响。近年来,深度学习在图像识别领域大放异彩,尤其是基于CNN的方法,已展现出超越传统算法的潜力。ResNet50作为残差网络家族的经典代表,凭借强大的特征提取能力与良好的泛化性能,在各类图像分类任务中频繁亮相。那么,如何基于ResNet50构建一套高效的鱼类识别系统?下面将详细阐述具体实现方法。
2 ResNet50简介
ResNet50由微软亚洲研究院提出,属于Residual Network系列,网络深度达到50层。其最大创新在于引入“残差块”(Residual Block),有效解决了深层网络训练中梯度消失的难题。每个残差块包含两条路径:主路径执行常规卷积操作,快捷路径则将输入直接叠加到输出上,两者相加形成最终结果。这种设计使得信息能够无障碍流动,保证了深层网络的训练效果与性能表现。

3 系统设计
3.1 数据收集与预处理
数据来源方面,公开数据集如Fish4Knowledge是不错的选择;当然也可以自行采集图像,但需注意版权问题。收集完成后需进行清洗:剔除模糊不清、背景杂乱的图片,只保留主体清晰、特征明确的样本。数据增强是防止过拟合的有效手段——采用旋转、翻转、缩放、色彩变换等方法,提升样本多样性。最后一步是标签整理,确保每张图片都有正确的类别标注,必要时可请专业人员复核。3.2 模型构建
首先下载在ImageNet上预训练好的ResNet50权重,这是站在巨人肩膀上的策略。然后修改顶层:移除原有的全连接层,替换为适配鱼类识别任务的新全连接层,输出节点数等于待识别的鱼类种类数。训练初期先冻结大部分卷积层,仅微调新增的全连接层——这样收敛速度会显著提升。随着训练深入,再逐步解冻底层卷积层,让模型对更细微的特征进行精细调整。3.3 训练策略
损失函数选用交叉熵(Cross Entropy Loss),这是多分类问题的标准配置。优化器采用Adam,其自适应学习率特性让调参更加省心。批次大小根据硬件条件设定,32或64均为常见选择;总迭代次数则依据验证集表现而定。早停法同样需要应用:设置一个耐心期,若连续若干轮验证误差不再下降,则果断停止训练,避免过拟合。3.4 后处理与应用接口
模型输出为概率分布,需进行后处理——要么设定阈值过滤,要么直接取最大值,最终确定预测结果。在用户使用层面,可开发图形界面或API接口,让用户上传图片即可获得识别结果。同时建议加入反馈机制:若用户发现识别有误,可提交反馈,这些数据将用于后续模型迭代优化。4 实验结果与分析
4.1 数据集描述
实验所用的数据集包含N种鱼类共M张图片,每种类别至少有X张样本,确保训练样本量充足。数据经过前述预处理步骤后,划分为训练集、验证集和测试集三部分。
4.2 实验设置
硬件方面,实验在配备NVIDIA GTX 1080Ti显卡的工作站上运行。软件环境为Python 3.7 + TensorFlow 2.x + Keras 2.x。超参数方面:学习率设为0.001,批次大小32,最大迭代次数50轮。4.3 性能评价
测试集上的整体准确率达到Y%,表明模型具有较好的泛化能力。通过绘制混淆矩阵,可以直观看到各类别之间的误判情况,找出容易混淆的识别难点。再挑选典型错误案例进行深入分析,明确问题所在,后续改进方向也随之清晰。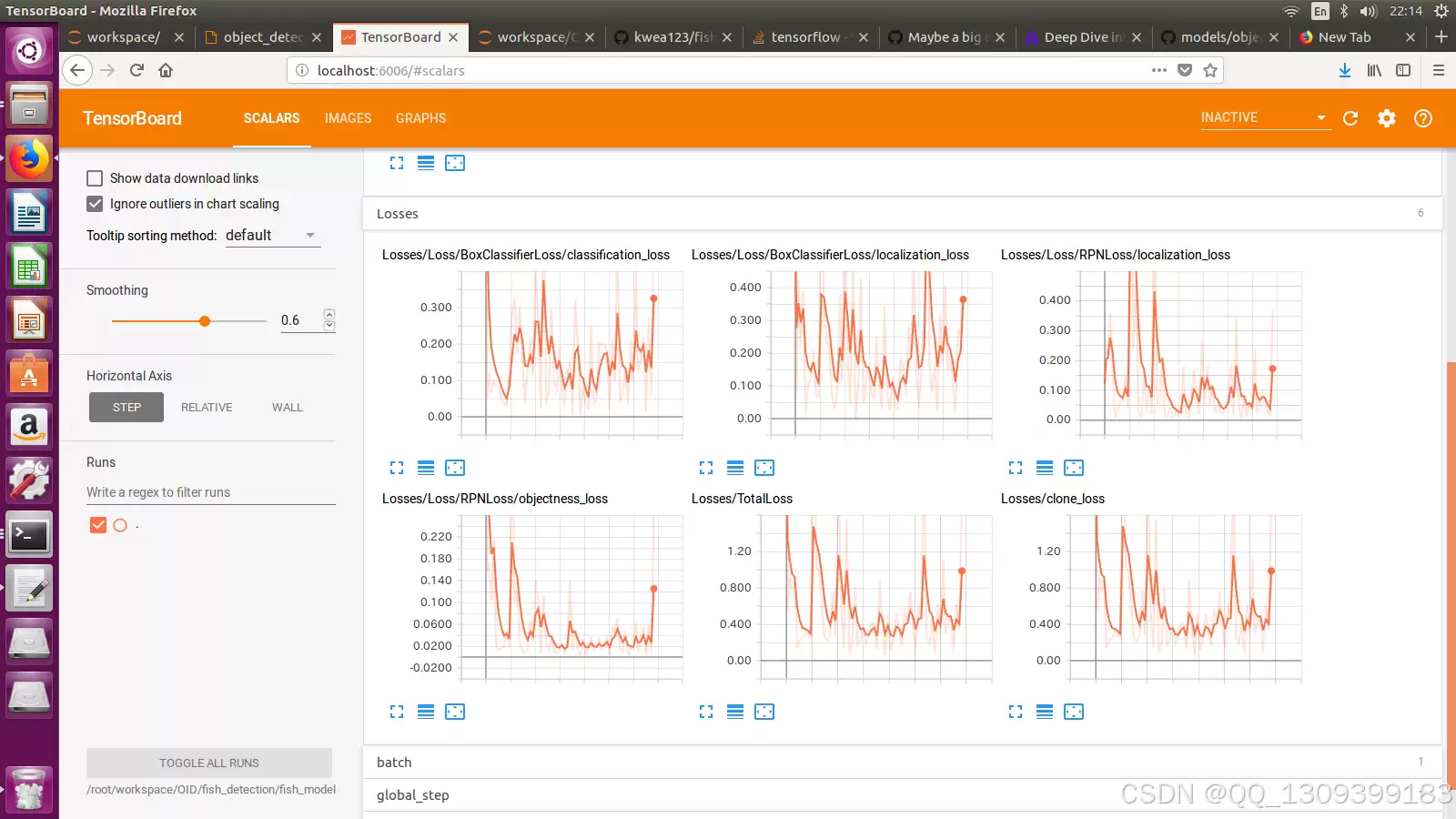
5 结论与展望
总体而言,这套基于ResNet50的鱼类识别系统展现了良好的识别性能,尤其在处理大量相似物种时优势明显。当然,仍有不少值得深化的方向:
- 扩展数据规模:增加更多鱼类种类和样本数量,使模型适用范围更广。 - 集成学习:尝试将多个不同架构的模型结合起来,利用集成策略进一步提升识别效果。 - 移动端部署:优化模型结构,使其能在智能手机等移动设备上高效运行,真正落地到实地场景。可以预见,随着研究与实践的不断推进,基于深度学习的鱼类识别技术将在海洋生物多样性保护中发挥越来越重要的作用。




