0、前言
本文详细记录了在 Windows 11 本地环境下,使用 Ollama 部署 Qwen2.5 大模型并实现 API 调用的完整流程。无需独立显卡也能流畅运行,同时确保数据隐私安全——所有信息完全掌握在自己手中。
通过本安装与部署教程,你将全面了解并掌握以下关键点:
Ollama的核心功能、安装与基本使用方法;Modelfile的配置规则及其在模型定制中的作用;ModelScope如何帮助我们快速获取模型文件;Notebook在云端体验大模型的便捷方式;- 如何将上述工具组合使用,完成本地大模型部署,并通过 API 进行远程调用。
下面直接进入实操环节。
1、环境与准备
- Win11:Windows 11 专业版 25H2
- CPU:Intel(R) Core(TM) i7-8750H CPU @ 2.20GHz (2.21 GHz)
- 内存:16.0 GB
- 显卡:GTX1050Ti(实际部署中基本未调用,对结果影响有限)
- Ollama: 0.17.7
- 大模型:
- qwen2.5-3b-instruct-q4_k_m
- qwen2.5-7b-instruct-q4_k_m
前置依赖检查
PowerShell(Win11 内置,无需额外安装)Git(可选,用于下载代码)Python(仅在使用ModelScope CLI时需要,若只用浏览器下载可省略)
2、核心概念速览
2.1、模型文件名 qwen2.5-3b-instruct-q4_k_m.gguf 的含义?
模型文件名通常呈现为 qwen2.5-3b-instruct-q4_k_m.gguf,逐段解析即可明白其含义。
instruct 代表该模型经过指令微调,适用于对话场景;而 base 版本更擅长续写或二次微调,直接聊天效果不佳。
1)q + 数字:每个参数存储使用的比特数。
- 数字越小 → 文件体积小、推理速度快,但可能轻微降低精度。
- 数字越大 → 文件体积大、推理速度慢,但保留更高质量。
- 推荐阈值:目前行业公认 4-bit (
q4) 性价比最高,几乎无损智商,体积减半。
2)k:表明采用了 K-quants 量化技术(一种更先进的压缩算法,比传统 q4_0 效果更好)。
3)m / s / l:分别对应 Small (小)、Medium (中)、Large (大) 三种变体。
q4_k_s:体积更小,但性能略有折扣。q4_k_m:标准版,平衡性最佳,强烈推荐首选。q4_k_l:体积更大,性能微增(显存占用也相应上升)。
2.2、Modelfile 的基本结构及含义
FROMSYSTEM PARAMETER TEMPLATE ADAPTER PROJECTOR MESSAGE LICENSE
各字段解释:
FROM: 指定基础模型(必填项)。 SYSTEM : 设定系统提示词(定义模型角色与行为)。 PARAMETER : 配置推理参数(如温度、上下文长度等)。 TEMPLATE : 定义对话模板格式。 ADAPTER : 加载 LoRA 适配器文件(用于微调模型)。 PROJECTOR : 加载多模态投影器(让模型具备图片理解能力)。 MESSAGE : 预设对话示例(Few-shot 提示)。 LICENSE : 声明模型许可证信息。
日常最常用的简洁配置如下:
FROM llama3 # 1. 选择基座 SYSTEM "你是个诗人" # 2. 设定角色 PARAMETER temperature 0.8 # 3. 调整参数
2.3、Notebook 是什么
本文虽以本地部署为主,但若本地资源有限(如显存不足),可使用 ModelScope Notebook 在云端免费体验大模型,完全无需担心硬件配置。
ModelScope Notebook 是一款云端机器学习开发 IDE,提供交互式编程环境,内置限时免费算力,用户可在浏览器中直接运行模型,对新手非常友好。
2.4、运行大模型的通俗理解
将运行大模型类比为“搬家”,更易理解:
- 量化等级(Quantization)= 家具的压缩打包程度(压得越小搬得越快,但可能轻微损坏)
- 推理框架 = 运输工具的选择(Ollama 如同专用搬家车)
- 上下文长度(Context Length)= 本次搬运的货物总量(记忆容量)
3、实战部署:安装与运行
3.1、安装 Ollama
Ollama 是一款开源工具,专为本地运行大型语言模型(LLM)而设计,可视为“大模型领域的 Docker”。

从官网下载安装后,在终端验证:
# 查看版本号 ollama -v ollama version is 0.17.7
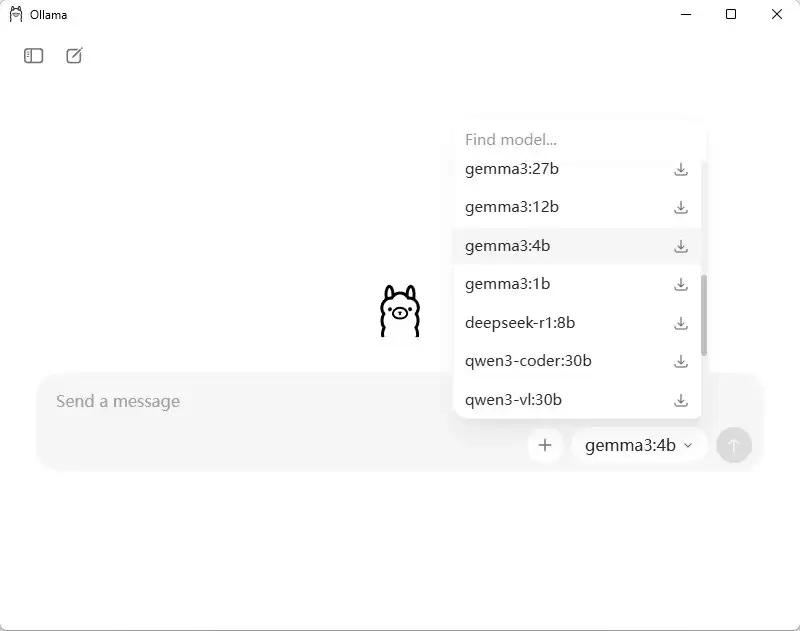
3.2、方式一:一键拉取(官方推荐),Ollama 界面/命令行拉取
通过 Ollama 直接拉取模型,无需编写 Modelfile,操作简便。
# 下载并运行模型 ollama run qwen2.5:3b
3.3、方式二:自定义导入 (进阶),下载 gguf 文件自行配置
1)从 ModelScope 下载 gguf 文件
通过 modelscope 在浏览器中直接下载模型。本例以 Qwen2.5-3B-Instruct-GGUF 演示(实际部署亦采用此模型)。
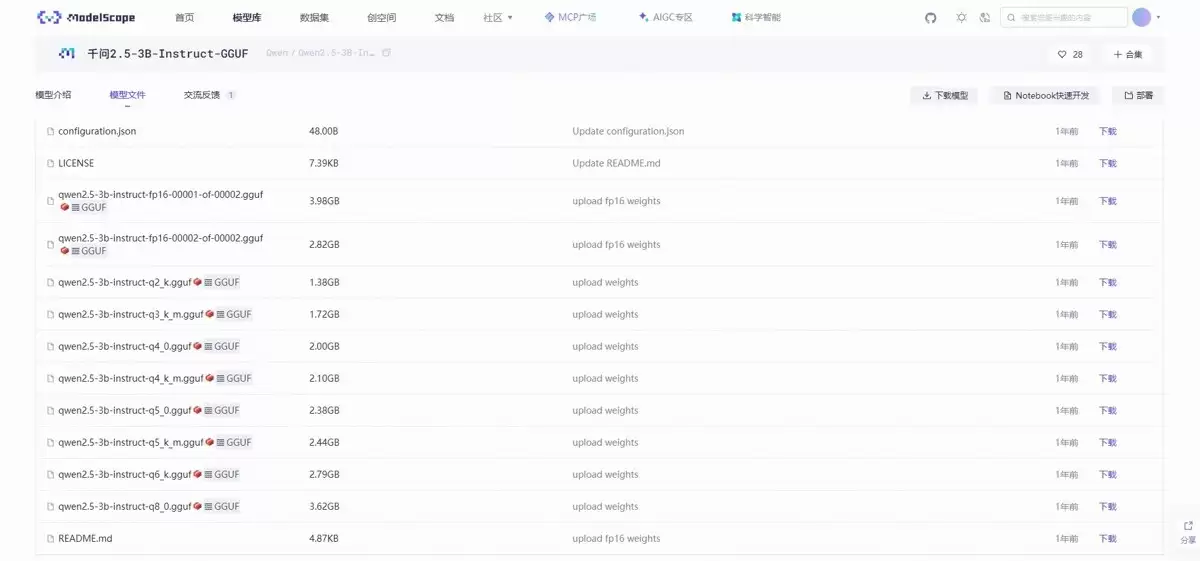
进入模型文件页面,找到如 qwen2.5-3b-instruct-q4_k_m.gguf 的文件,下载即可。
2)编写 Modelfile 文件
Modelfile 是 Ollama 用于定义大模型推理参数的自定义文件,类似 Dockerfile。对于简单对话,Ollama 官方库已预先适配 Qwen 系列模板,通常无需手动指定 TEMPLATE;仅在需要特殊对话格式或微调时才有必要。详情可参考文末【4.3、Modelfile 的基本结构及含义】。
新建文件,命名为 Modelfile,内容如下:
FROM "G:AIModelfilesqwen2.5-3bqwen2.5-3b-instruct-q4_k_m.gguf"
TEMPLATE """{{- if .Messages }}
{{- range $i, $_ := .Messages }}
{{- $last := eq (len (slice $.Messages $i)) 1 }}
{{- if eq .Role "user" }}<|im_start|>user
{{ .Content }}<|im_end|>
{{ else if eq .Role "assistant" }}<|im_start|>assistant
{{ .Content }}<|im_end|>
{{ else if eq .Role "system" }}<|im_start|>system
{{ .Content }}<|im_end|>
{{ end }}
{{- if $last }}<|im_start|>assistant
{{ end }}
{{- end }}
{{- else }}
{{- if .System }}<|im_start|>system
{{ .System }}<|im_end|>
{{ end }}{{ if .Prompt }}<|im_start|>user
{{ .Prompt }}<|im_end|>
{{ end }}<|im_start|>assistant
{{ end }}"""
PARAMETER stop <|im_end|>
PARAMETER stop <|im_start|>
PARAMETER temperature 0.7
PARAMETER top_p 0.8
PARAMETER top_k 20
PARAMETER repeat_penalty 1.05
LICENSE """https://huggingface.co/Qwen/Qwen2.5-3B-Instruct/blob/main/LICENSE"""
最精简版本(仅含 FROM 一行,基本无法自问自答):
FROM "F:\Downloadsqwen2.5-3b-instruct-q4_k_m.gguf"
3)创建模型
打开 Powershell,切换至 Modelfile 所在目录,执行以下命令:
# 将 GGUF 文件打包为 Ollama 模型 ollama create qwen2.5:3b -f Modelfile # 或使用绝对路径 ollama create qwen2.5:3b -f G:AIModelfilesqwen2.5-3bModelfile

4)运行模型
Ollama 默认自动检测并使用 GPU 加速。为优化资源,若连续 5 分钟无活动,模型会自动卸载;下次请求时重新加载,因此首次请求可能稍慢(加载延迟)。
ollama run qwen2.5:3b

查看大模型运行状态:
SIZE: 占用内存大小PROCESSOR:100% CPU表示模型完全在 CPU 上运行,未启用显卡加速(因 GTX1050Ti 显存仅 4GB,无法驱动)CONTEXT:上下文窗口大小,即当前会话保留的“记忆”长度(Token 数量)。数值越大,占用内存越多。UNTIL(自动卸载倒计时):若后续无人使用,Ollama 将在 2 分钟后自动卸载模型,释放资源。

5)示例:Qwen2.5-7B 的配置
文件名:qwen2.5-7b-instruct-q4_k_m.gguf
FROM ./qwen2.5-7b-instruct-q4_k_m.gguf
TEMPLATE """{{- if .System }}
<|im_start|>system
{{ .System }}<|im_end|>
{{- end }}
<|im_start|>user
{{ .Prompt }}<|im_end|>
<|im_start|>assistant
"""
PARAMETER stop <|im_end|>
PARAMETER stop <|im_start|>
PARAMETER temperature 0.7
PARAMETER top_p 0.8
PARAMETER top_k 20
SYSTEM "你是一个有帮助的AI助手。"
4、通过API访问大模型
4.1、启动服务
# 查看服务运行端口 ollama serve # 返回信息:Error: listen tcp 127.0.0.1:11434: bind: Only one usage of each socket address (protocol/network address/port) is normally permitted.
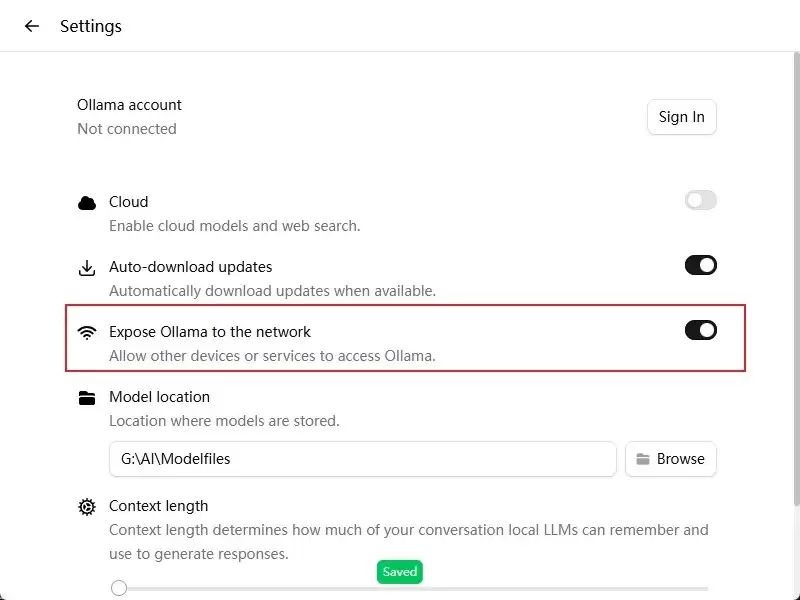
默认情况下,Ollama 仅接受本机连接,拒绝局域网 IP(如 192.168.x.x)。如需局域网内其他设备访问,需配置环境变量。Windows 下操作如下图所示。
4.2、Powershell 中测试接口
# Windows Powershell
curl https://192.168.2.111:11434/api/generate -d "{"model": "qwen2.5:3b", "prompt": "hello"}"
curl https://192.168.31.87:11434/api/tags
4.3、后台方式运行技巧
Start-Process ollama -ArgumentList "run","qwen2.5:3b" -WindowStyle Hidden
这样模型将在后台静默运行,不会弹出控制台窗口。
5、常用命令速查表
掌握以下 Ollama 命令,足以应对日常操作:
# 查看帮助 ollama -h # 列出本地已下载模型 ollama list # 下载并运行模型(交互模式) ollama run qwen2.5:3b # 单次问答(非交互) ollama run qwen2.5:3b "你好,请介绍一下你自己" # 删除模型 ollama rm <模型名> # 启动后台服务 ollama serve # 查看模型详情 ollama show <模型名> # 查看正在运行的模型 ollama ps # 停止指定模型 ollama stop qwen2.5:3b
6、附录与参考资料
ModelScope Pip 安装详解
# 确认已安装 Python python -V Python 3.11.9 # 安装 ModelScope 库 pip install modelscope # 下载完整模型库(以 Qwen2.5-3B-Instruct-GGUF 为例) modelscope download --model Qwen/Qwen2.5-3B-Instruct-GGUF # 下载单个文件到指定本地目录(以下载 README.md 到当前目录下的“dir”文件夹为例) modelscope download --model Qwen/Qwen2.5-3B-Instruct-GGUF README.md --local_dir ./dir




