最近这两年,不管是做知识图谱还是智能推荐系统,或者 AI Agent 应用,图数据库这个词开始频繁出现在各种技术方案里。有小伙伴跑来问:Neo4j 到底是什么?跟 MySQL 有啥区别?它能做什么?其实答案很直接——如果把数据比作一个社交关系网,MySQL 会用多个表格来描述这种关系,而 Neo4j 会直接画出这张网:节点就是人,线就是关系。数据的本来面貌就是一张网,我们非要把网拆散了放到表格里,就是在做“破镜重圆”的事。
前言
今天,用一份完整的入门教程,带你从头到尾搞懂 Neo4j。希望对你会有所帮助。
一、Neo4j 到底是什么?
先说一个最核心的点,可能会打破你的认知——图数据库里的“图”,跟我们平时说的“图片”没有任何关系。“图”在这里是 Graph 的意思,也就是一张由“点”和“线”组成的网络。
传统的关系型数据库(比如 MySQL、PostgreSQL)用表格来存数据,而 Neo4j 用节点和关系来存数据。打个比方,你在微信朋友圈里:用户张三是一个“节点”,李四也是一个“节点”,张三跟李四是好友关系,这条线就是“关系”。
在 MySQL 里:
CREATE TABLE users (id INT, name VARCHAR);
CREATE TABLE friends (user_id INT, friend_id INT);想在 MySQL 里找出“张三朋友的朋友”?要套两层 JOIN,SQL 长得像裹脚布一样,而且在深度查询场景下,这种多表 JOIN 的性能会随着关系深度呈指数级下降。在 Neo4j 里,你连脑子都不用动,数据就是一目了然的网。
说人话:MySQL 擅长存“谁是谁”;Neo4j 擅长存“谁跟谁有什么关系”。但千万别误解——这不是选择题,不是说用了 Neo4j 就要抛弃 MySQL。两者各司其职:MySQL 负责业务数据主航道,Neo4j 负责关系分析和推理,完美配合。
二、安装 Neo4j
先把环境搭起来。三种方式任你选,新手最推荐方式一:Neo4j Desktop。在 Mac 上运行 Neo4j 前,建议确保系统满足 macOS 10.15 或更高版本。内存方面:学习/开发环境至少需要 2GB,推荐给到 16GB;内存越足,图越丝滑。Windows 用户按提示下载 .exe,Linux 用户直接用 .AppImage。
方式一:Neo4j Desktop(最省心,有图)
下载:访问 Neo4j 官网的部署中心,找到适合你系统的安装包(Mac:.dmg,Windows:.exe,Linux:.AppImage)。安装:Mac:双击 .dmg,把 Neo4j Desktop 图标拖到 Applications 文件夹。Windows:双击 .exe 一路 Next。创建数据库:打开应用,点 New → Local DBMS,输入密码后点击 Create。启动:把光标放在数据库卡片上,点击 Start,等圈圈变绿点。访问:点 Open Browser,或者在浏览器里打开 https://localhost:7474,输入 neo4j 和你设的密码。看到这个 Web 界面了吗?以后我们写的所有 Cypher 查询就在这里执行。
方式二:Docker(推荐有 Docker 基础的同学)
这是一个用 Docker 在 Mac、Windows、Linux 上运行 Neo4j 的示例:
docker run -d --name neo4j -p 7474:7474 -p 7687:7687 -e NEO4J_AUTH=neo4j/your_password_here -e NEO4J_dbms_memory_heap_initial__size=1G -e NEO4J_dbms_memory_heap_max__size=2G -e NEO4J_dbms_memory_pagecache_size=1G -v $HOME/neo4j/data:/data eo4j:5.26.2参数详解:-p 7474:7474 -p 7687:7687:映射两个关键端口。7474 是 HTTP 管理端口,7687 是 Bolt 协议端口(Ja va 等语言连接用的)。-v $HOME/neo4j/data:/data:数据持久化卷,把容器内 /data 挂载到宿主机。没这行,删容器后数据就丢了。-e NEO4J_AUTH=neo4j/your_password_here:强制设置身份验证(Neo4j 5.x 起必须要认证)。-e NEO4J_dbms_memory_heap_initial__size=1G:JVM 堆内存初始值。-e NEO4J_dbms_memory_pagecache_size=1G:页面缓存,用于加速查询。
方式三:Homebrew(Mac 用户最爱)
如果你在 Mac 上偏好命令行,这套命令最顺手:
brew tap neo4j/neo4j
brew install neo4j
brew services start neo4j安装后验证
不管哪种方式,启动后在浏览器打开 https://localhost:7474。看到如下界面,恭喜你,环境搭好了!登录后建议先执行一个测试查询:RETURN 1 AS result,确保能正常返回数据。
三、核心概念:搞懂节点、关系和路径
从现在起,忘掉“表”的概念。我们用三个基本积木,就能搭建整个数据世界。
积木一:节点(Node)——具体的“人”或“物”
节点就是图里每一个独立的实体,比如一个用户、一部电影、一个地址。节点可以打标签(Label),相当于把相同类型的节点归类。一个节点可以有多个标签,比如一个人同时是 Person 和 Engineer。节点可以有属性(Property),就是键值对,比如用户的名字、年龄、所在地。
创建一个“张珊”的人节点,并打上 Person 和 Student 两个标签:
CREATE (n:Person:Student {name: "张珊", age: 22, city: "北京"})
RETURN nCREATE:创建命令。(n):括号里的是节点变量名,字母随意,方便后面引用。:Person:Student:两个标签,用冒号连接,表示这个节点既是人也是学生。{...}:属性,JSON 格式的键值对。RETURN n:显示结果,方便在 Browser 里直观看到节点。
积木二:关系(Relationship)——节点之间的连接线
关系就是节点之间的那条线。它具有方向、类型、属性三个特征。关系的方向和类型必须指定,这样才能清晰地表达语义。在 Cypher 中,--> 表示有向关系,-[:KNOWS] 表示关系类型是 KNOWS(认识)。
创建 Person-A 认识 Person-B 的关系:
CREATE (alice:Person {name: "爱丽丝", age: 24}),
(bob:Person {name: "鲍勃", age: 26})
CREATE (alice)-[r:KNOWS {since: 2021, trust_level: 5}]->(bob)
RETURN alice, r, bob代码详解:第一个 CREATE 一次性创建了两个独立的人节点。第二个 CREATE 直接引用前面定义的变量 alice 和 bob,在两者之间拉一条关系线,类型是 KNOWS,且这个关系有一个 since 属性和一个 trust_level 属性。关系方向不能马虎:如果查询时方向写反了,可能找不到结果;但查数据时用 -[:KNOWS]- 可以忽略方向,双向查找。
积木三:路径(Path)——多段关系的“路线图”
路径就是多条关系串联成的一条链。路径是图数据库的精华——在现实世界里,关系的价值往往不是孤立的两个点,而是一整条链路。例如:爱丽丝认识鲍勃,鲍勃认识查理,查理认识大卫。从爱丽丝到大卫的路径长度就是 3 跳。
查找从爱丽丝出发,往外走 3 跳以内的所有认识关系:
MATCH (alice:Person {name: "爱丽丝"})-[r:KNOWS*1..3]-(friend)
RETURN alice.name, friend.name[r:KNOWS*1..3] 的含义:*1..3 表示匹配 1 到 3 跳的关系,- 两侧没有箭头表示忽略方向。所以这个查询能找出爱丽丝认识的人(1 跳),她认识的人认识的人(2 跳),以及更远的朋友圈(3 跳)。
节点、关系、路径三者的关系:节点是实体,关系是连接线,路径是业务答案。路径越长,图数据库越有优势——想一下 MySQL 里做 5 层 JOIN 的感受,再对比一下 Neo4j 里一行 1..5 的简洁。
四、Cypher 完全实战手册
Cypher 是 Neo4j 的查询语言,设计得像 SQL 一样直观,但专门为图做了优化,用 () 表示节点,-[]-> 表示关系,匹配模式的可读性极强。下面从零开始,掌握所有的增删改查操作。
4.1 创建数据
基础创建:单一节点
CREATE (u:User {id: 1, name: "张三", age: 25})
RETURN uRETURN 不是必须的,但不加就看不到刚造出来的点。
批量创建:多个节点同时插入
CREATE (u1:User {name: "李四", age: 28}),
(u2:User {name: "王五", age: 23})
RETURN u1, u2级联创建:节点和关系一步到位
CREATE (u1:User {name: "赵六", age: 27})-[b:BUY {price: 999}]->(p:Product {name: "耳机", brand: "Sony"})
RETURN u1, b, p这种模式在一个事务中完成创建:创建人、创建商品、同时建立购买关系。如果其中任何一步失败,整个操作回滚,保证数据一致性。这是 Neo4j 完全支持 ACID 事务的结果。
链式创建多跳关系
CREATE (u1:User {name: "小红"})-[f:朋友]->(u2:User {name: "小明"})-[c:同事]->(u3:User {name: "小强"})
RETURN *RETURN * 返回查询中所有涉及的节点和关系。
4.2 查询数据
查找所有数据
MATCH (n) RETURN n适合开发环境做验证,生产环境千万别用(会拉取全库,导致 OOM)。
条件查找
MATCH (u:User) WHERE u.age > 25 RETURN u.name, u.age ORDER BY u.age DESC LIMIT 5关系查找
// 查找所有认识关系,并返回两端的人名和认识年份
MATCH (p1:Person)-[r:KNOWS]->(p2:Person)
RETURN p1.name, p2.name, r.since多跳关系——两度关系(朋友的朋友)
MATCH (p1:Person {name: "张三"})-[:KNOWS]->(p2:Person)-[:KNOWS]->(p3:Person)
RETURN p3.name AS secondDegreeFriend共同好友查询(这是图数据库的经典能力)
MATCH (p1:Person {name: "张三"})-[:KNOWS]-(common:Person)-[:KNOWS]-(p2:Person {name: "李四"})
RETURN common.name AS commonFriend这个查询的含义是:先找到张三的所有朋友,再找到李四的所有朋友,取出交集。在 MySQL 里需要嵌套两个集合查询,在 Cypher 里三步就走完——"张三-朋友-张三的朋友-朋友-李四",中间的 common 就是他们要找的人。
4.3 路径的高级查询
这是 Neo4j 的杀手级功能。
查找最短路径
MATCH p = shortestPath((alice:Person {name: "爱丽丝"})-[*]-(bob:Person {name: "鲍勃"}))
RETURN p[*] 表示任意长度、任意类型的关系。Neo4j 返回爱丽丝到鲍勃的最短路径,应用在地铁换乘、社交好友最短联系、疾病传播追溯等场景,一行代码搞定。
按最大长度查找路径
MATCH (alice:Person {name: "爱丽丝"})-[:KNOWS*..4]-(connected)
RETURN DISTINCT connected.nameKNOWS*..4 表示仅考虑 KNOWS 类型的关系,最大长度为 4 跳。DISTINCT 去重。
查找所有最短路径
MATCH p = allShortestPaths((a:Location {name: "A站"})-[*]-(b:Location {name: "B站"}))
RETURN pallShortestPaths 返回所有等长的最短路径,不单单是任意一条。
4.4 更新数据
更新节点属性
MATCH (u:User {name: "张三"})
SET u.age = 26, u.updated_at = datetime()
RETURN udatetime() 返回当前时间戳,类型为 DateTime。
给关系增加属性
MATCH (u:User {name: "张三"})-[r:KNOWS]-(friend)
SET r.meeting_place = "北京"这里关系搜索没有箭头 > <,匹配双向的认识关系。
4.5 删除数据
删除关系但保留节点
MATCH (u:User {name: "张三"})-[r:KNOWS]-(friend)
DELETE r删除节点及所有关联的关系(重点)
MATCH (u:User {name: "王五"})
DETACH DELETE uDETACH DELETE 会先自动删除节点上的所有关系,再删除节点。如果直接使用 DELETE 去删一个带关系的节点,Neo4j 会报错。
清空整个数据库(慎用,操作前先备份数据)
MATCH (n) DETACH DELETE n五、给大家的建议
查询前先预览:不确定要删什么的时候,先 MATCH (n) 不写 DELETE,看看结果对不对。锁定范围:在大图里一定要加 WHERE 限定标签,否则一个查询可能导致内存飙升。分页 LIMIT:返回节点很多时,先用 RETURN ... LIMIT 20 看预览。SHORTEST 路径查询:在 Neo4j 5.21 之后推荐用 SHORTEST 1 语法,不用再用 shortestPath() 函数了。
六、Spring Boot 集成
作为 Ja va 后端,你肯定不想每次都在网页里敲命令。接下来把 Neo4j 能力用到自己的业务系统中。
6.1 引入依赖
org.springframework.boot
spring-boot-starter-data-neo4j
6.2 配置 YAML
spring:
data:
neo4j:
uri: bolt://localhost:7687
authentication:
username: neo4j
password: 你的密码6.3 映射实体(@Node)
import org.springframework.data.neo4j.core.schema.*;
@Data
@Node("Person") // 标签名
public class Person {
@Id @GeneratedValue
private Long id;
private String name;
private Integer age;
@Relationship(type = "KNOWS", direction = Relationship.Direction.OUTGOING)
private Set friends;
} @Relationship 告诉 Spring Data Neo4j:当前节点通过 KNOWS 关系指向 friends 集合里的其他 Person 节点。
6.4 写 Repository
import org.springframework.data.neo4j.repository.*;
import org.springframework.data.repository.query.Param;
@Repository
public interface PersonRepository extends Neo4jRepository {
Optional findByName(String name);
@Query("MATCH (p1:Person {name: $name1})-[:KNOWS]-(common)-[:KNOWS]-(p2:Person {name: $name2}) RETURN common")
List findCommonFriends(@Param("name1") String name1, @Param("name2") String name2);
} 6.5 在 Service 里调用
@Service
public class SocialService {
@Autowired
private PersonRepository personRepository;
public void demo() {
Person alice = new Person();
alice.setName("爱丽丝");
alice.setAge(24);
personRepository.sa ve(alice);
List friends = personRepository.findCommonFriends("张三", "李四");
System.out.println("共同好友个数:" + friends.size());
}
} 集成时的两个踩坑点:确保 Spring Boot 版本在 2.5.x 以上,才能获得对 Neo4j 4.4/5.x 的完整支持;生产环境推荐基于 SDN6 的 Ja va Driver 路线,避免 OGM/嵌入式混搭。
一个实际案例:某企业智能知识库系统就用到了图数据库Neo4j,效果如下:
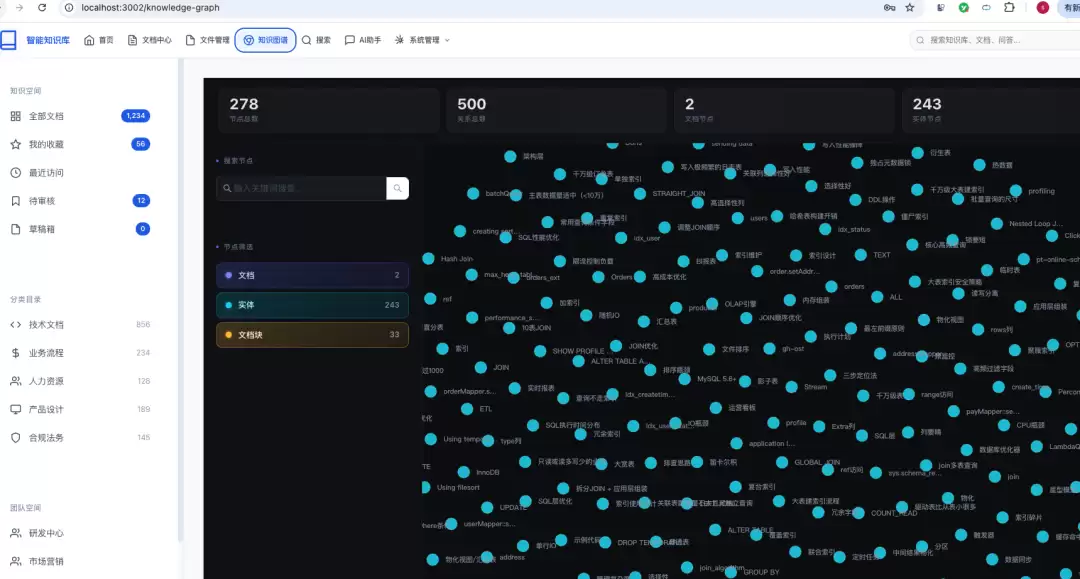
可以帮你生成项目中的知识图谱。
七、优缺点
Neo4j 的主要优点
关系查询性能极强:得益于原生图存储引擎,关系本身就是一种数据结构,图遍历通过指针完成,在深度关联查询场景下比关系型数据库快几个数量级。建模方式高度直观:模型图跟白板上画的业务图几乎一样,开发和沟通成本大幅降低。Cypher 语言简洁:声明式查询语言,接近自然语言的语法,写起来像打字聊天一样轻松。完全 ACID 事务:这是 Neo4j 区别于很多 NoSQL 数据库的核心能力,金融、交易类场景有保障。成熟的工具链和生态:官方提供 Bloom 可视化工具(为分析师定制的无代码图探索工具)、Graph Data Science 库、ETL 工具 Neo4j Connector 等。
需要注意的局限
社区版限制较明显:社区版只支持单机部署,没有高可用、备份、集群能力。企业版按 CPU 核心数计费。内存消耗大:全量数据需要在内存中缓存才能获得最佳性能。水平扩展能力相对受限:超大规模图(百亿级边以上)需要考虑分布式图数据库。写入性能低于关系数据库:维护图结构的开销比写入 MySQL 要高。
八、适用场景一图看懂
结合不同行业的最佳实践经验,整理了一张图,对照着看更清晰:
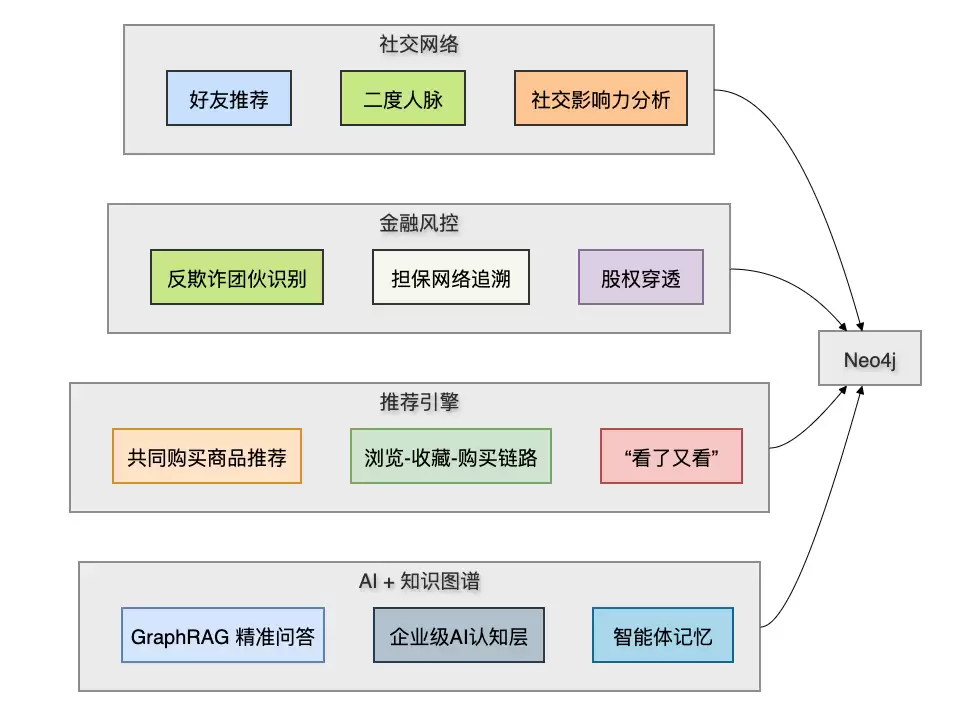
每个场景都指向一个核心能力——深度关系遍历。如果你的业务需要“把链条绕几圈再找答案”,Neo4j 就对了。