先给出一个核心结论:市面上常见的智能体算法搜索框架——例如 AlphaEvolve、OpenEvolve 或 AK 风格的 AutoResearch——在编程题和浅层 benchmark 上表现确实不错。然而,一旦将这些框架应用于实际的机器学习训练流水线,问题便会逐渐暴露。原因并不复杂:ML 拥有独特的成本结构与失败模式,而通用框架并未充分考虑这些因素。
ml-evolve 正是针对这一空白而设计的。它是一个专为 ML 垂直领域打造的多智能体自进化系统。系统中的每个智能体角色,都对应着生产环境中真实踩过的坑,而整个自进化循环也完全基于 ML 训练的经济学逻辑重新构建。本文不空谈理论,而是深入拆解这些设计选择,并说明它们为何优于现有方案。
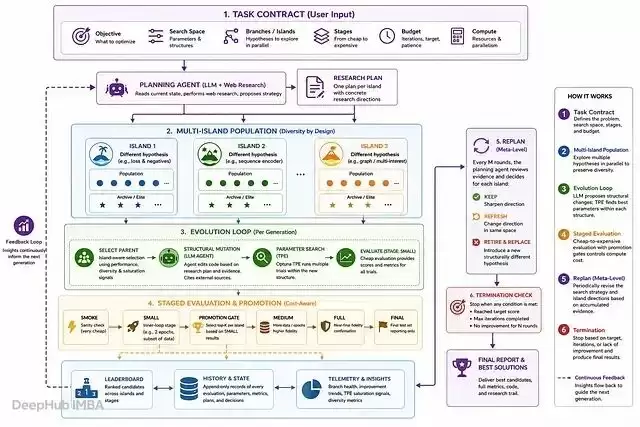
为什么 ML 需要专属的智能体系统
当前智能体算法搜索系统的底层逻辑,本质上是为代码搜索设计的。候选对象是一段代码,评估器是一个单元测试运行器,一轮执行以秒计。接着进行变异、打分、重复,节奏高效流畅。
但 ML 的情况则截然不同:
- 候选对象是一次完整的训练运行,耗时从十分钟到数小时不等。
- 评估器需要在真实数据上、采用合理的数据划分来训练模型,并避免数据泄露、分布偏移及噪声淹没微弱信号。
- 真正能带来突破的维度,并非“对函数做语法级编辑”,而是架构选择、训练方案设计、特征工程构建、采样策略调整——每一项都是研究级别的决策。
- 有价值的已有成果不仅藏身于 arXiv 论文中,更大量存在于工业界团队已上线系统的技术博客里。
- 计算资源是实打实的成本。一次粗放的搜索可能烧掉全部预算,却输出不了任何可上线的模型。
在这种条件下,通用循环很快就会暴露出缺陷。例如,同一个 LLM 三次就能写出一个合格的排序函数,但给它一百次迭代,也未必能有效改进一个推荐系统架构。问题不在于缺乏想法,而是围绕它的循环缺少足够结构来公平验证这些想法。
四个痛点,以及对应的智能体角色
我们换一种思路:先梳理那些导致智能体在 ML 场景中失败的典型模式,然后基于这些模式,设计最精简的智能体拓扑结构来逐一解决。
1. 一个 LLM 难以兼顾架构推理与数值优化
让同一个 LLM 同时负责模型架构设计与超参数调优,结果往往是两项任务都难以做好。
一个七维的连续参数空间并非 LLM 的强项,TPE 和贝叶斯优化方法在此类问题上表现更为稳定。此外,LLM 容易锚定在前几轮的数值上,导致搜索坍缩为局部微调,即使架构明显陷入瓶颈也难以跳出。
因此,我们将任务拆分为两个智能体,分别在不同层面工作。
- 变异智能体负责架构与算法代码本身——它修改候选程序中的
EVOLVE块。但它不直接选择数值,而是将数值参数化。 - 参数搜索智能体则在冻结的架构上运行 Optuna TPE——在试点数据上进行 12 次试验,其中 5 次热启动。这是标准的贝叶斯超参数优化(HPO),无需 LLM 介入。
这样一来,每一层都使用了最擅长的工具:变异智能体负责结构推理,参数搜索智能体负责数值搜索。如果一个架构在最优参数下仍然表现不佳,那就可以判定是架构本身的问题,而非“参数没调好”。信号质量得到提升,计算浪费显著降低。
2. 智能体搜索容易坍缩为浅层微调
如果没有有效管控,LLM 驱动的循环会一轮接一轮地在刚刚奏效的方案上修修补补。例如出现“Embedding 维度 64→128→96→80”这样的循环,排行榜上挤满几乎一模一样的模型。这是由于智能体需要在“本轮出成果”与“尝试有风险的方向”之间做权衡,短期决策必然导致这种结果。
因此,需要一个独立的计划智能体,掌握搜索广度的结构性权力。
- 分支提前声明,明确假设,计划智能体只能在预设槽位内操作。它可以将某个槽位的具体方向翻新(例如“温度试过了,试试 hard negatives”),但不能将两个槽位合并为一个思路。
- 计划智能体定期唤醒(每 K 轮),读取完整排行榜,然后重写研究计划。它不是第 0 轮一次性出场后就沦为摆设。
- 计划智能体允许联网搜索。工业 ML 中最实用的经验通常不在 arXiv 上——而是来自已上线过类似系统的团队博客。例如,它可以将“Meta 的双塔笔记提到 BM25 hard negatives 配合课程学习有效”直接引入分支假设。
- 每条分支都设有终止条件。卡住的分支不能悄悄耗尽所有预算,其槽位会被回收。
这样运行 15 轮后,产出的不是一个模型的 15 个小变体,而是每条分支上两到三个真正不同的架构,各自已调至局部最优。广度不再是被贪心优化剩下的边角料,而是系统的首要选择。
3. 训练成本远超其他环节 100-10000 倍
这个问题是通用代码搜索框架完全忽视的——它们的候选对象毫秒级就能编译。而在 ML 中,这却是决定搜索循环能否承受的关键瓶颈。
我们的解决方案是一个嵌入在自进化循环中的三阶段训练门控。
| 阶段 | 数据量 | 用途 |
|---|---|---|
| search(试点) | 约 10% 样本 | 内循环探索。每个候选、每个参数试验均在此阶段运行。 |
| promote(完整) | 100% | 晋升门控。仅 search 阶段的前 K 名可以进入此阶段。 |
| final(报告) | 100% | 仅用作最终报告,绝不用于选型反馈。 |
举例说明:一个 3 节点 × 15 迭代 × 12 试验的任务,若每轮训练需 40 分钟,全量运行一个节点则需要 360 GPU 小时。采用分阶段策略后,内循环仅使用 10% 试点数据,一个节点缩减至约 36 小时,再加上少量完整晋升。探索深度保持不变,计算成本节省约 10 倍。
门控不仅提升效率。final 阶段与选型完全隔离,有效堵住了报告泄漏——一种无声而破坏性的偏差,会导致保留的评估集逐渐演变为选择信号。临时搭建的智能体循环上线一周内几乎必然会踩中这个坑。因此,控制器明确禁止将 final 分数用于父代选择。
4. 信号带噪声时,排行榜可能失真
即使划分了阶段,基于 10% 试点数据的排行榜噪声仍远大于全量评估。LLM 可能追逐前十名中的假象,将噪声误当作信号来生成方案。
为此,我们需要在智能体角色和控制器中嵌入一组小规则。
- 参数搜索智能体使用带显式
tpe_startup_trials热启动的 TPE,防止早期轮次锚定在一颗老鼠屎上。 - 控制器定期(每 K 轮)执行晋升:将 search 阶段的前 K 名用全量数据重新评估。持续领先者存活,噪声领先者暴露。
- 计划智能体不仅读取原始分数,还关注分支健康度(多久未进步、试验分散度如何)。它能区分“本轮噪声较大”和“该分支结构上已无潜力”。
- 排行榜显式标注分数所属阶段,选型时始终清楚分数来源。试点分数不会与完整分数等同比较。
这些并非高深技术,而是有经验的 ML 工程师用痛换来的教训,并将其固化为脚本规则。
智能体与阶段的配合方式
将四个痛点的解决方案整合在一起,便得到系统的拓扑结构:
┌─────────────────────────────────────┐
│ PLAN AGENT (算法广度) │
│ 读取排行榜与分支健康度 │
│ 可选网络搜索;每个节点 │
│ 分配一条假设 │
└──────────────┬──────────────────────┘
▼
┌─────────────────────────────────────┐
│ MUTATION AGENT (架构) │
│ 重写 EVOLVE 块;参数化数值旋钮 │
│ 但不选择具体值 │
└──────────────┬──────────────────────┘
│ 冻结架构
▼
┌─────────────────────────────────────┐
│ PARAM-SEARCH AGENT (数值) │
│ Optuna TPE,N 次试验 │
│ 在 PILOT(10% 数据)上运行 │
└──────────────┬──────────────────────┘
│ 最佳分数
▼
┌─────────────────────────────────────┐
│ PROMOTION (每 K 轮) │
│ top-K 试点 → 全量数据 │
│ 噪声过滤,泄漏屏障 │
└──────────────┬──────────────────────┘
│ 更新排行榜
└─► 回 PLAN AGENT
每个智能体专注于自身擅长的任务,每个阶段花费合理的计算成本,每轮循环最终返回上一层形成闭环。这正是“自进化”的本质:本轮的排行榜成为计划智能体下一轮的输入,而计划智能体对广度的掌控确保了搜索不会坍缩。
与现有自进化算法对比
最接近的参考系是 AlphaEvolve、OpenEvolve 以及更广泛的 AK 风格 AutoResearch 智能体。它们共享一个骨架——提出、评估、学习、重复——均依赖排行榜驱动的自我改进信号。我们的差异如下:
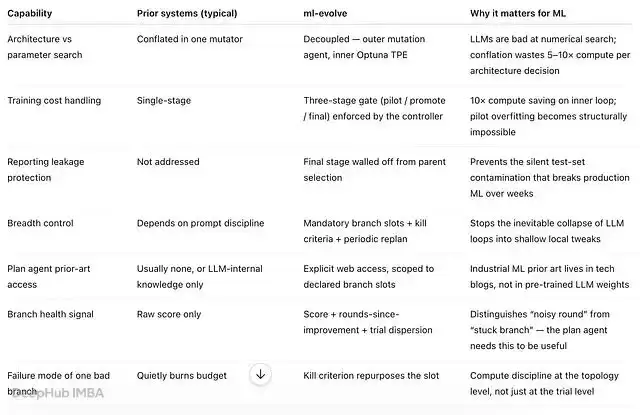
观察最右列。每一行代表一个场景:当用通用智能体搜索循环运行真实 ML 训练系统时,要么计算消耗过高,要么输出结果浅层,要么悄悄污染评估指标。我们并非换了一个比喻——而是针对具体生产故障做出的针对性回应。
AlphaEvolve、OpenEvolve 和 AutoResearch 主要优化研究广度与能力天花板。它们之所以令人印象深刻,正是因为其不受约束的特性。而 ml-evolve 优化的是生产级 ML 迭代效率——追求可重复、可审计、可负担、抗泄漏。不同目标,互为补充设计。
双塔检索优化案例
来看一个具体场景:双塔检索流水线。已知基线如下:
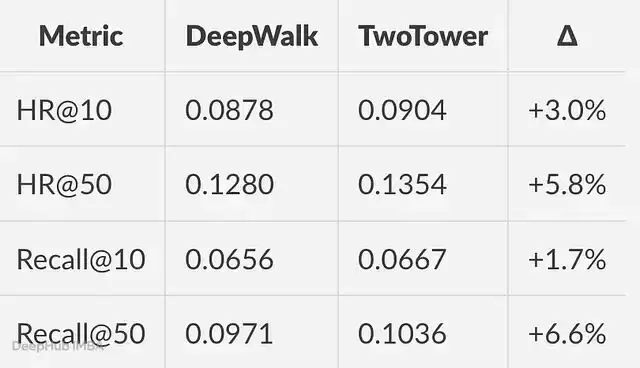
TwoTower 作为新基线,目标是将 Recall@50 进一步提升。我们声明了三个结构上不同的假设节点:in-batch 负样本调优、基于 ANN 的 hard negative 挖掘、多兴趣用户塔(MIND / ComiRec 风格)。每条分支均设有终止条件。
第 6 轮(共 15 轮)的运行情况:
[Stage] search (10% data pilot)
[Branch] hard_negative_mining
Plan agent → "Round 5 converged at temperature 0.05.
Meta two-tower notes recommend BM25-retrieved
hard negatives & curriculum schedule.
Direction: add hard_neg_ratio and pool_size."
Mutation agent → edits EVOLVE block, parameterizes the two knobs.
Param-search → 12 Optuna TPE trials, 5 startup.
best → Recall@50 = 0.1112 (pilot)
cost: 12 × 4 min = 48 min on one GPU
[Branch] in_batch_neg_tuning best → 0.1071
[Branch] multi_interest_user_tower best → 0.1058 (2/3 kill criterion)
[Promotion] every=5 → round-5 top-1 promoted; full-stage check
→ Recall@50 = 0.1098 (consistent with pilot — not noise)
[Replan] replan_every=5 fires → multi_interest_user_tower flagged
for hypothesis refresh next round.
这一轮暴露了系统设计的几个关键点:
- 解耦搜索(痛点 1):计划智能体从不过问温度值,那是 Optuna 的任务。
- 广度控制(痛点 2):三个结构不同的分支并行推进,其中一条即将被回收。
- 多阶段训练(痛点 3):试点阶段仅耗时 48 分钟,而全量约为 8 小时——节省 90% 计算量,探索深度不减。
- 噪声过滤(痛点 4):晋升阶段使用全量数据验证试点领先者,避免噪声进入后续计划。
运行完成后产出的文件包括:leaderboard.md(每分支最优结果及历史记录)、research_plan.md(当前计划智能体指令)、param_trials/*.json(每次 Optuna 试验详情)、report.md(最终报告,不参与选型)。两个月后有人询问为何选择 hard negative 而非多兴趣方案,答案就存在于这些文件中——而非某个 Slack 讨论串里。
何时该使用本系统
适合的场景:
- 单标量目标(NDCG@K、Recall@K、IC、AUC、利润等)
- 训练任务足够长,使分阶段搜索能够自我回本(每个候选训练时间约 ≥ 10 分钟)
- 有多个真正不同的研究方向值得并行探索
- 需要在下个季度仍能审计“尝试过什么、为什么选择该方案”
不适合的场景:
- 纯超参数网格搜索——Optuna 已足够
- 在线 / 人在环评估——本系统为离线循环
- 训练成本太低,分阶段引入的开销反而超过节省(工业界少见)
总结
智能体 ML 领域正朝着更开放、能力更强的系统演进,这对研究而言是积极的。但有一个平行问题较少被讨论:如何设计一个多智能体系统,使其在本季度、在真实 ML 训练流水线上就能收回成本?
这并非模型规模的问题,而是智能体设计的问题:按照角色擅长的决策来分配职责,按照可承担的计算资源来划分时间尺度,将广度与深度拆分开,避免它们互相干扰。
如果你的算法搜索循环尚未挣回算力投资,答案或许不是换一个更大的 LLM,而是将智能体系统设计得更加完善。




