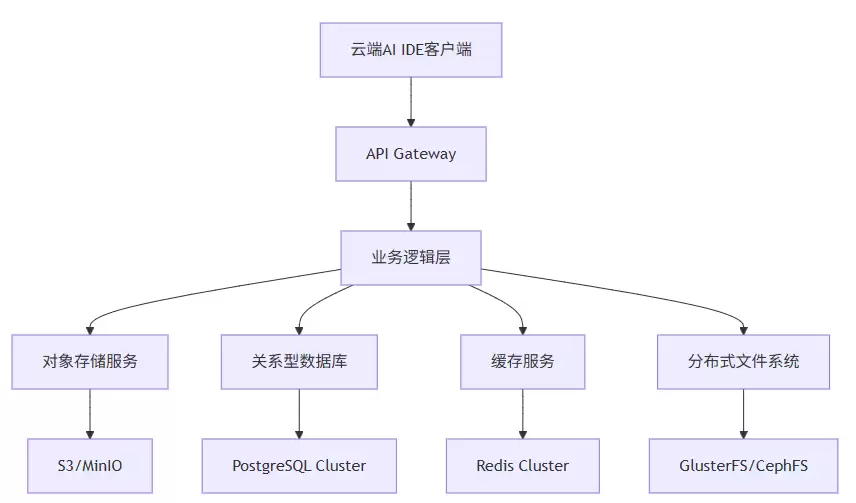
引言:云端AI IDE的存储挑战,从本地到云端的“数据大迁移”
云端AI IDE和本地IDE最本质的区别在哪?答案就四个字:数据无处不在。你的代码、配置、项目资产、会话状态,都不再安稳地躺在本地磁盘上,而是分散在云端的数个存储系统里。根据GitHub对Copilot企业版架构的分析,一个成熟的云端IDE,必须同时搞定以下几种存储需求:
先看代码文件存储:支持上万人同时编辑同一个代码仓库,这需要强一致性来保证不会乱套。用户数据存储呢?账户信息、项目元数据、权限关系,这些需要强一致性的事务支持,不能出错。会话状态存储要处理用户操作历史、编辑器状态、临时计算结果,这些对延迟要求极高,必须低延迟读写。还有项目资产存储,像容器镜像、模型文件、依赖包,这些都是大家伙,需要低成本、大容量的方案。
根据CockroachDB在2025年发布的《分布式数据库在SaaS应用中的实践》报告,多存储系统协同工作,最大的挑战主要在四个方面。第一,一致性保证:跨系统的数据一致性是老大难。第二,性能隔离:不同存储介质的延迟特性差异很大,需要精心设计。第三,运维复杂度:系统一多,故障点就多,监控起来也更复杂。第四,成本控制:必须做好冷热数据分离,才能在性能和成本之间找到平衡。
对象存储:S3兼容存储的接入
Amazon S3从2006年发布至今,已经成为对象存储的事实标准。它的模型很简单,就是扁平的键值对存储,通过Bucket和Object两级结构来组织数据。Bucket就是存储桶,可以看作顶级目录,全球唯一命名。Object是具体对象,由Key、Version ID、Value和Metadata组成。Key就是对象的唯一标识,格式通常是 prefix/object_name。
S3的设计哲学就是简单、高可用、低成本。根据AWS官方数据,S3 Standard的可用性高达99.99%,数据持久性更是达到了11个9。
存储类型 | 用途 | 延迟 | 成本 |
|---|---|---|---|
S3 Standard | 热数据 | <100ms | $0.023/GB |
S3 Intelligent-Tiering | 自动分层 | 取决于层级 | $0.023 $0.0125/GB |
S3 Glacier | 冷数据 | 分钟级 | $0.004/GB |
S3 Deep Archive | 归档 | 12小时内 | $0.00099/GB |
对于需要私有化部署的场景,MinIO是个绝佳选择。它完全兼容S3 API,可以快速部署在Kubernetes上,性能也相当亮眼——根据MinIO的官方基准测试,单节点就能达到55 GiB/s的读吞吐和44 GiB/s的写吞吐。
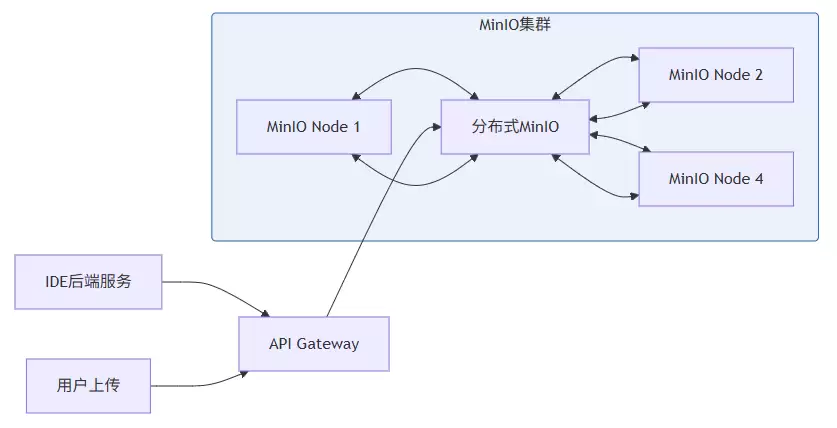
下面是用AWS官方SDK连接S3兼容存储的代码示例,展示了文件上传、下载、删除等核心操作,还包括了预签名URL的生成,可以直接拿来用。
[代码块 - S3StorageClient 实现]对象存储在云端IDE中的应用场景很广。比如用户头像,键模式是 a vatars/{user_id}.{ext},用Standard类型,小文件,访问频繁。项目资产如 projects/{id}/assets/{path},访问频率中等,可以用Standard或IA。容器镜像层、AI模型文件、备份数据等都有各自的键模式和建议的存储类型。还有临时上传的文件,键模式为 uploads/{session_id}/{filename},需要定期清理。
生命周期管理也很重要,可以通过配置规则实现数据的自动归档。比如,可以对 projects/ 目录下的数据,设置30天后自动转为Glacier,365天后转为Deep Archive,这样成本控制就非常灵活了。
数据库选型:PostgreSQL vs MySQL vs CockroachDB
云端IDE的核心业务数据,比如用户账户、项目元数据、权限关系、计费信息和审计日志,必须用关系型数据库来支撑。这些数据的特点是强一致性、复杂查询和事务支持。
来对比一下三款主流的数据库。在事务隔离级别上,PostgreSQL支持READ COMMITTED、REPEATABLE READ和SERIALIZABLE;MySQL类似;CockroachDB则支持SERIALIZABLE和SNAPSHOT。在分布式支持上,PostgreSQL有原生支持(XC/XL),MySQL有分片方案(Cluster),CockroachDB则是原生的。一致性的模型上,PostgreSQL和CockroachDB都是基于RAFT的强一致性,而MySQL主从复制是最终一致性。JSON支持方面,PostgreSQL的JSONB性能很优秀,MySQL也支持但性能一般,CockroachDB也支持。全文搜索、PostGIS支持、性能侧重和许可协议都有所不同。
根据Percona 2025年的《数据库性能基准测试报告》,在单节点写入性能上,MySQL > PostgreSQL > CockroachDB;多节点读取性能则是CockroachDB > PostgreSQL > MySQL;在分布式事务延迟上,CockroachDB的延迟增加最少。
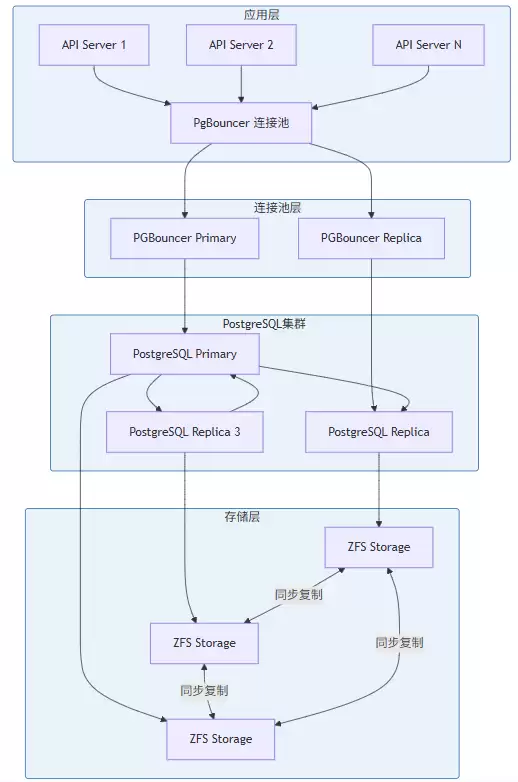
对于大多数场景,PostgreSQL是稳妥的选择。下面展示的是一套使用asyncpg实现异步访问、配合PgBouncer作为连接池的PostgreSQL最佳实践。代码里包含了数据库连接池的配置、用户和项目的CRUD操作,以及审计日志的写入,是一个非常完整的实现方案。
[代码块 - PostgresStorage 实现]数据库的高可用架构也是必须考虑的,通常会采用主从复制、流复制等技术来确保数据安全和业务连续性。
如果你的云端IDE需要全球分布(比如GitHub Codespaces的多区域部署),CockroachDB是更好的选择。它的核心优势很突出:基于RAFT协议的强一致性保证了数据不冲突;数据天然分布在多个区域,支持多区域部署;兼容PostgreSQL协议,客户端和驱动可以无缝迁移;节点故障后能自动重新平衡,实现自动故障恢复。
[代码块 - CockroachDBStorage 实现]最后,数据库选型要结合具体场景。对于单区域的中小规模(<100万用户),PostgreSQL成熟稳定,生态完善,是最佳选择。多区域部署且需要强一致性的,建议用CockroachDB。超大规模、高写入吞吐量的,可以考虑PostgreSQL加应用层分片。成本敏感、对MySQL熟悉的团队,用MySQL加Vitess也是成熟方案。需要高级GIS功能的,那PostgreSQL加PostGIS的组合无人能敌。
会话存储:Redis Cluster的高可用部署
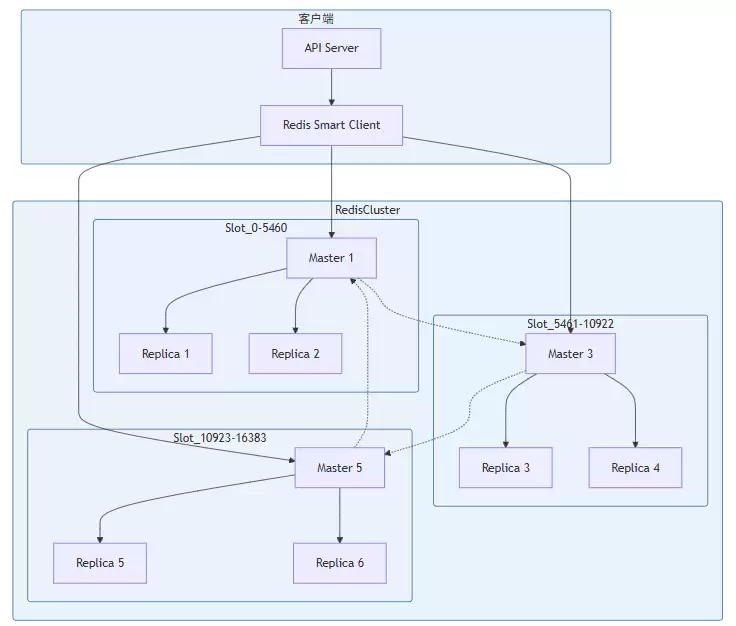
Redis在云端AI IDE中扮演着多面手的角色。用户会话(Hash类型,TTL 24h)、实时协作状态(Hash/List,TTL 5min)、速率限制(String,TTL 1min)、分布式锁(String,TTL 30s)、缓存层(String/Hash,TTL 1h)、消息队列(List),以及发布/订阅功能,都离不开它。
Redis Cluster的架构设计采用了16384个槽(Slot)进行数据分片。每个Key通过 CRC16(key) mod 16384 计算落到的槽位,每个Master节点负责一部分槽位,而每个Master可以有1到N个Replica用于故障转移,保证了高可用。
下面是一个完整的Redis会话管理实现,涉及用户会话的创建、获取、更新、删除,Token的管理,实时协作状态的同步,以及分布式锁的获取和释放。代码中还实现了Redis Cluster的自动降级到Standalone模式,非常实用。
[代码块 - RedisSessionStore 实现]代码存储:分布式文件系统 vs 对象存储
代码存储是云端IDE最核心的基础设施之一,挑战也最大。和普通文件存储相比,代码存储有几个显著特点:文件数量极多(一个Git仓库可能有数十万个文件);读取模式是频繁读取相同文件,有访问热点;写入模式是增量写入,每次提交只改少量文件;一致性要求极高,代码合并时数据必须一致;元数据开销巨大,对文件系统inode压力很大。
根据Facebook 2022年的《Git at Scale》论文,大型代码仓库的核心问题包括 .git 目录膨胀、检出慢、克隆慢和索引操作慢。针对这些挑战,主要有两种方案:分布式文件系统和对象存储方案。
分布式文件系统方案的代表是JuiceFS。它采用数据与元数据分离的架构,核心优势包括:完全兼容POSIX,无需修改代码;原生支持Kubernetes和CSI Driver,云原生特性突出;元数据与数据分离,便于独立扩展;支持S3、MinIO、本地磁盘等多种后端。
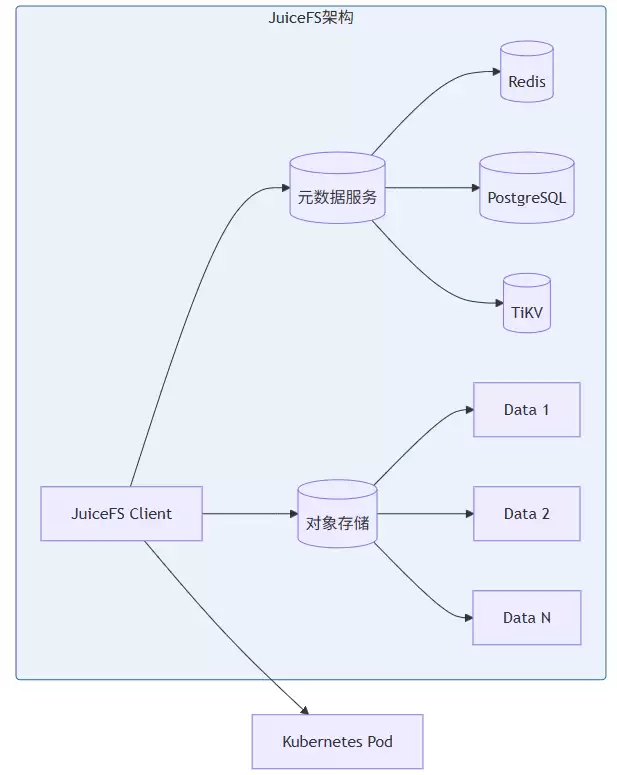
在Kubernetes中,通过StorageClass就能方便地使用JuiceFS。配合相应的代码实现,可以完成文件系统的挂载、卸载,以及代码仓库的创建和状态获取。
[代码块 - JuiceFS StorageClass 和 JuiceFSStorage 实现]对于超大规模的代码仓库,Git Native Storage方案提供了另一种思路。它将Git仓库以对象形式存储在S3中,其核心原理是:Git的pack文件直接作为对象存储;小对象先缓存,达到阈值后打包上传;相同前缀的pack文件共享数据块;文件名、大小、SHA等元数据索引则存储在Redis或Elasticsearch中。
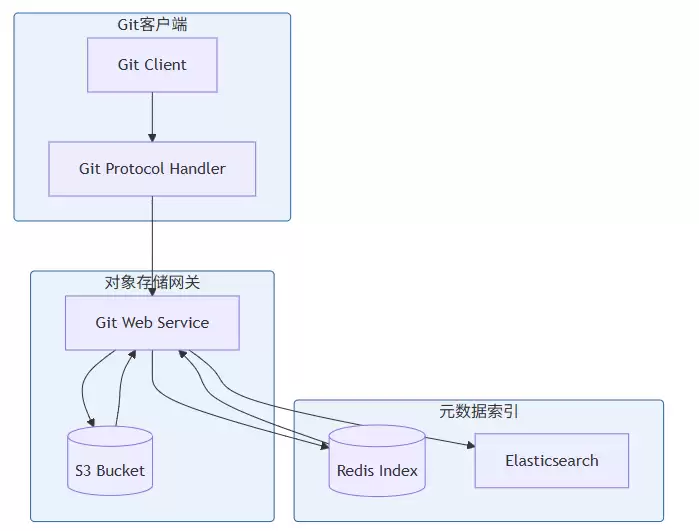
那么,到底该如何选型呢?简单来说,小型团队(<100人)用本地SSD加JuiceFS就足够了。中型团队(100-1000人)推荐JuiceFS加云对象存储的组合。大型团队(>1000人)可以考虑Git Native Storage加对象存储。超大型团队(>10000人)则需要自研Git Native Storage加分片对象存储的方案了。
数据备份:增量备份与跨区域复制
云端IDE的数据备份,必须考虑三个核心指标:RPO(可接受的数据丢失量)、RTO(可接受的恢复时间)和成本。不同数据类型的策略也不同。用户数据(数据库)的RPO要求是5分钟,RTO是30分钟,通常采用连续归档(WAL)加每小时快照。代码仓库的RPO和RTO都是1小时,建议每日全量加每小时增量备份。对象存储的RPO是24小时,RTO是12小时,主要通过跨区域复制实现。至于会话数据,因为TTL会自动过期,所以不备份。
下面是一个PostgreSQL备份服务的实现,包含了全量备份(basebackup)、增量备份(基于WAL文件)、备份列表查看、备份删除、过期清理,以及向S3复制和跨区域复制的完整逻辑。
[代码块 - PostgresBackupService 实现]对象存储的跨区域复制配置也很关键,可以通过定义规则来实现。例如,可以将 projects/ 下的数据复制到灾备区域,或者将 backups/ 下的数据复制到另一个用于深度归档的存储桶。
实践:设计一个多存储类型的统一存储服务
有了前面各个存储组件的理论和技术储备,我们就可以把它们整合起来,设计一个统一的存储服务。这个服务的架构会清晰地分层,对外提供统一的API接口,对下管理各种存储引擎。
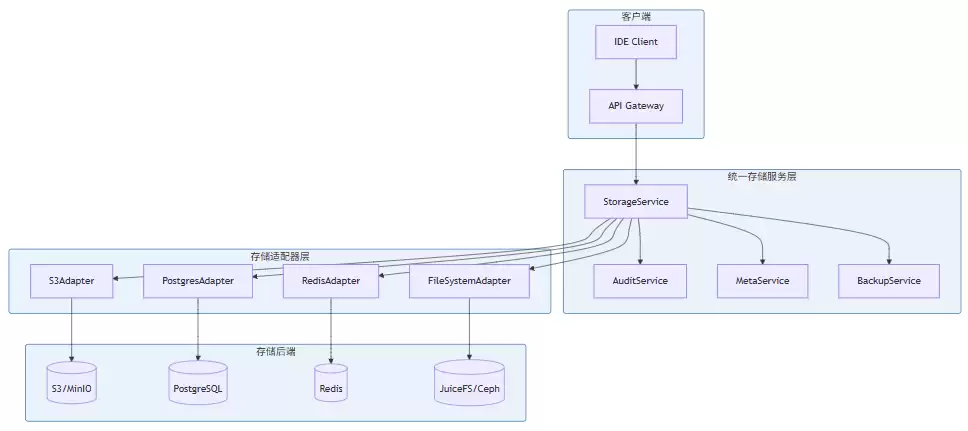
统一存储服务的核心实现包括StorageConfig配置类、StorageResult结果类和UnifiedStorageService主服务类。主服务类会初始化S3、PostgreSQL、Redis和JuiceFS四种存储引擎,并提供业务层的方法,比如创建用户、用户认证、创建项目(同时写数据库、文件系统和对象存储)、更新协作状态等。代码中还包含了健康检查功能,可以实时监控各个存储组件的状态。
[代码块 - UnifiedStorageService 实现]相应的配置文件也需要统一管理,涵盖对象存储、数据库、缓存、文件系统和备份的各项参数。这样的设计模式,可以让上层应用完全解耦底层的存储实现,简化开发,也提高了系统的可维护性和扩展性。
[代码块 - 配置文件示例]总结与展望
这篇文章从工程实践的角度,系统地梳理了构建云端AI IDE存储底座的核心知识。我们探讨了对象存储(S3/MinIO)的接入方案和生命周期管理;对比了PostgreSQL、MySQL和CockroachDB,并给出了PostgreSQL的完整实现;深入到了Redis Cluster的会话管理,覆盖了用户会话、协作状态、速率限制等方方面面;在代码存储上,对比了JuiceFS和Git Native Storage两种方案,并给出了清晰的选型建议;最后,通过一个“统一存储服务”的设计案例,展示了如何将上述组件有机地整合在一起,提供一个统一的、高可用的存储底座。
展望未来,有几个趋势值得关注。边缘存储融合会进一步降低数据访问的延迟。基于AI的访问模式预测,将实现智能化的分层存储,让数据自动迁移到最合适的存储层。统一元数据管理将打破数据孤岛,让数据索引更加高效。CRDTs等技术的广泛应用,会带来更强的一致性保证。最后,存储加密、访问控制和审计追踪将更深层次地融合,实现安全存储的一体化。
[附录代码块 - S3存储桶策略、PgBouncer配置、Redis Cluster配置、健康检查脚本]




