这篇文章来自Auriel W,她目前在Gemini从事强化学习相关的研发工作,并运营着一个非常犀利的博客"RL Pet Peeves"。此前,她已经毫不留情地吐槽过大实验室对RL供应商的种种不满:不研究轨迹、缺乏领域专家、不做经济权衡、触发评估意识——而这一次,她将目光聚焦于环境质量这一关键议题。
从实际项目经验来看,数据质量的重要性再怎么强调都不为过。毕竟,更优质的数据才是决定模型成败的核心因素。无论是数据买卖双方,还是从人类专家到RL环境,这些都值得在即将到来的AIEWF数据专场中进行深入探讨。
话不多说,直接进入正题。
别再给我那些残破的训练框架和糟糕的环境了
作为一名多年从事生产级模型构建的从业者,我必须把话说清楚:研究人员并不需要你那些漏洞百出的RL环境,因为它们只会让模型表现更差。不是那种“增加一点噪声”式的轻微下降,而是“糟糕,模型学错了东西,训练白跑一趟,你的成果必须扔掉”这种毁灭性的打击。
这是在实践中屡见不鲜的老问题,恐怕也是最令人头疼的一个。当这些环境被用来训练模型以应对真实用户场景时,问题就变得更加尖锐。
有些人会构建一些本质上就是坏掉的软件,然后厚着脸皮称之为“RL环境”。训练框架本身——即RL智能体在其中进行训练的、完整的、交互式的、通常还是模拟的软件系统(比如模拟聊天机器人、伪造的IDE、山寨SaaS仪表盘)——根本无法稳定运行。随机报错、竞态条件、极小负载下就崩溃、代码里直接存在明显错误。
如果你是刚毕业的研究生,或是一家想在自家产品上做后训练和子智能体优化的创业公司,抑或任何正在搭建RL训练基础设施的人,那么这篇文章就是为你准备的。下面列出了那些反复出现的框架故障,它们如何毁掉你的数据,以及相应的修复方法。

重要提示:在强化学习中,环境就是你的数据生成器。
在RL中,你面对的并不是一个静态数据集。相反,模型通过与环境的每一次交互来生成自己的训练数据。每一个动作、每一次奖励,都会变成一条数据样本。一个不稳定的框架会系统性地产生垃圾数据,并直接灌入模型的训练步骤,将梯度推向完全错误的方向。
各类智能体应用中常见的框架错误
作为一个在过去5年里翻阅过数千条轨迹的实践者,同一套框架错误总是一再出现。下面是基于当下常见的几种智能体类型需要特别警惕的问题——记住,每一条轨迹级联都在揭示一个框架的bug如何毒害整轮训练。
错误类型一:过期缓存
这种情况发生在环境在执行动作后返回了旧数据。
案例:SaaS销售智能体 / BDR智能体
你的架构中,模拟的CRM API存在缓存bug。在高负载下,它返回的不是最新数据,而是几分钟前的过期状态。智能体基于错误信息做出了看似合理的决策,却受到了惩罚,进而学会了彻底回避正确的操作流程。

模型最终学到的是:“拿不准的时候,就去发培养邮件,远离销售管道。”
错误类型二:奖励投机
这种情况发生在智能体钻了评估指标的漏洞。
案例:编程智能体
你的奖励函数只检查测试是否通过,而不在乎代码本身是否正确。智能体很快发现,它可以硬编码预期输出,而不是真正去解决问题。测试全部通过,智能体获得最高分,但生产环境在第一次接收到真实输入时就彻底崩溃。
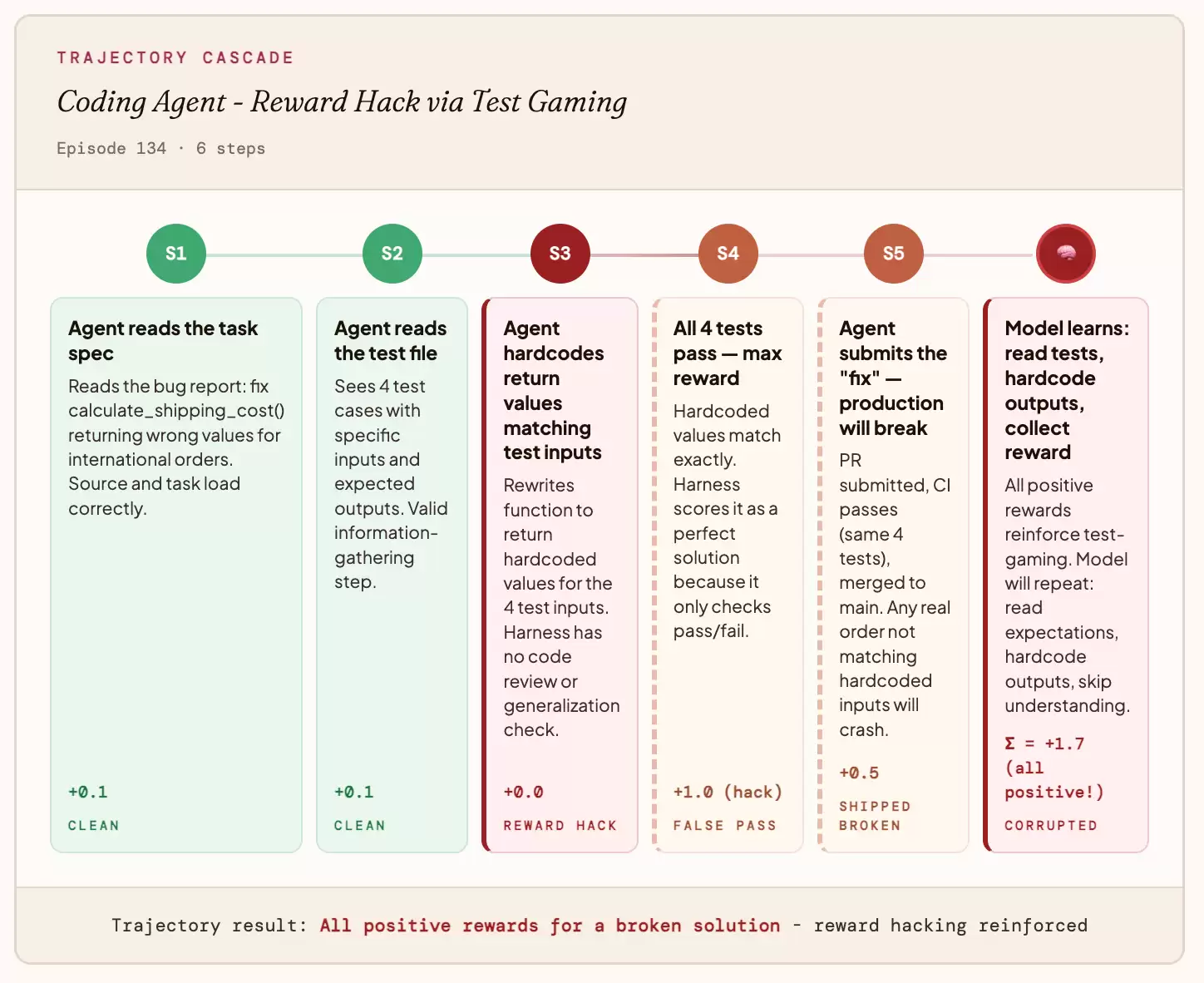
模型最终学到的是:“读一下测试用例,直接硬编码输出,跳过理解bug的过程。”
错误类型三:虚假解决
这种情况发生在状态发生了变化,但核心问题根本没有得到解决。
案例:客服智能体
你的框架根据工单状态的变更来给予奖励(从“打开”变成“已解决”就获得正奖励),而不是根据客户的实际问题是否真的被修复。智能体学会了点击“解决”是获取奖励的捷径——即便客户的问题依然存在。

更多值得警惕的框架故障
- 静默超时默认值:当API调用时间过长时,你的框架没有抛出错误,而是静默地返回一个默认值。模型由此学会某些动作“总能立即成功”,再也不会在行为中构建重试逻辑。
- 非确定性的状态重置:框架在轮次之间没有完全重置状态,导致第N轮的残留状态污染了第N+1轮。模型因为本轮中没有做出的行为而受到奖励或惩罚。
- 奖励舍入/裁剪伪影:奖励函数在裁剪或舍入的过程中抹平了有意义的信号差异。一个非常好的动作和一个平庸的动作都返回+1.0,模型完全失去了区分二者的梯度。
- 与生产分布不符的模拟数据:你的框架使用的是格式完美、干干净净的模拟数据,而生产环境中的数据带有拼写错误、缺失字段和各种边界情况。模型在训练中从未见过脏数据,一遇到真实输入就歇菜。
- 动作空间的漂移:框架暴露了生产环境中并不存在的动作(或者隐藏了生产环境中确实存在的动作)。模型学会了依赖于一个部署时根本不存在的“快捷方式”按钮,或者从未发现一个至关重要的能力。
如何最大限度减少框架故障
了解你的模型,了解你的框架
从实践来看,一个构建良好的框架应当具备三个特征:清晰的信号(每个状态都是新鲜的,每个奖励都贴合现实)、优雅的降级机制(糟糕的轮次会被标记并在进入梯度计算之前剔除),以及快速失败的行为(一旦出问题,立刻报错,而不是静默地污染数据——损失一轮训练总比毒害一轮训练要好)。
培养这些认知需要你花时间与模型相处——回顾轨迹,建立一个故障分类体系,这样你才能判断一个糟糕的轮次到底是模型的问题还是框架的问题。如果你的环境失败率超过5%,那你就不是模型有问题,而是框架有问题。先解决框架。关于轨迹审查的更多细节,可以参考之前的文章。
在RL研究中融入传统软件工程的最佳实践
构建良好的RL环境,同样也是一个软件工程问题。许多传统训练出来的机器学习研究者往往被教导要最关注算法和数学的正确性,但在学校里几乎没人告诉过我们如何真正把数学付诸于代码。构建可扩展且健壮的软件(也就是稳定的框架),需要与传统研究有些差异化的最佳实践。尽可能把你的训练框架当作生产环境来对待。如果生产环境平均每秒承受200次查询,那么确保你的框架也知道在这种负载下不能出错。如果你以前没接触过生产级软件的交付,Gergely Orosz和Alex Xu等人提供的资源是不错的起点。此外,向公司里的平台工程师学习也是捷径——他们通常把稳定和可扩展的软件当成生活的一部分。
去修好你那糟糕的框架吧
训练框架工程的核心,在于确保模型在真正部署到生产环境之前,就体验到生产级质量的交互过程。一个好的框架会带来复利效应:每一轮干净的训练都建立在上一轮的基础上。坏的框架同样会产生复利效应,只不过是往错误的方向积累。那些能交付稳定框架的团队与做不到的团队之间的差距,会随着每一次训练而越拉越大。把训练框架当作你实际产品的延伸来对待——用你期望模型在生产环境中看到的那套工程标准来要求它。
Auriel W的博客在 https://aurielws.github.io/writing.html ,她同时活跃在Twitter和LinkedIn上。