一、前言
基因组学研究已进入下半场,精度与全面性成为临床诊断及群体研究的核心需求。然而,单一测序技术常常让人陷入选择困境:短读长测序(如 Illumina)准确性高、成本低廉,但在面对结构变异、重复序列和复杂区域时显得力不从心;长读长测序(如 Oxford Nanopore)虽能轻松跨越这些障碍,超长读长对大型结构变异的识别效果极佳,但其测序成本居高不下,同聚物区域的插入缺失错误率也是一个棘手问题。
传统的混合分析方法通常是将两种数据各自比对后进行简单的交叉验证,长读长中蕴含的丰富结构信息并未被充分利用,复杂区域的比对偏差也难以从根本上得到纠正。此外,长读长要求较高的覆盖度,计算开销巨大,这让许多实验室望而却步。
Sentieon 模块化工具箱中的 sentieon-cli dnascope-hybrid 模块,凭借创新的算法融合打破了这一僵局。它引入了一项独创的重比对步骤——利用长读长单倍型来指导短读长的比对。这样一来,即便在最具挑战性的医学相关基因和串联重复区域,也能实现近乎完美的变异识别。
实测数据表明,仅需 5x–10x 的低深度长读长数据配合标准短读长数据,插入缺失检测的准确性便可超越传统 30x 纯长读长流程,变异检测错误率降低 50% 以上。得益于 Sentieon 工业级的算法优化,该流程在 x86、ARM 等多平台上运行极为高效,全流程分析耗时约 100 分钟,计算成本最低仅需几美元。无论是精准医疗的临床诊断,还是大规模人口基因组计划,Sentieon DNAscope Hybrid 都能在成本、速度与精度之间提供理想的平衡方案。
二、流程总览
Sentieon® DNAscope Hybrid 是一种将同一份样本的短读长和长读长测序数据结合起来进行种系变异识别的流程。它充分发挥两种技术的优势,生成的变异识别结果比单独使用任何一种数据都更为准确。只需一条 sentieon-cli 命令即可完整跑完整个流程。
流程支持以下数据格式作为输入,且短读长和长读长数据都必须提供:
gzip 压缩的 FASTQ 格式的未比对短读长数据。
BAM 或 CRAM 格式的已比对短读长数据。
uBAM 或 uCRAM 格式的未比对长读长数据。
BAM 或 CRAM 格式的已比对长读长数据。
流程默认生成以下输出文件:
以 VCF 格式输出的小变异(单核苷酸变异和插入缺失)。
以 VCF 格式输出的结构变异。
以 VCF 格式输出的拷贝数变异。
如果输入的是未比对的原始读数,流程还会输出已比对的 BAM 或 CRAM 文件。
1. 硬件配置
Sentieon® 软件包版本 202503.01 或更高。
Python 版本 3.11 或更高。
bcftools 版本 1.22 或更高。
bedtools。
MultiQC 版本 1.18 或更高(用于生成指标报告)。
samtools 版本 1.16 或更高。
mosdepth 版本 0.2.6 或更高(用于从长读长数据中收集覆盖度指标)。
2. 基于已比对的短读长与长读长数据检测胚系变异
仅需一条命令即可从比对后的短读长序列中检测单核苷酸变异、插入缺失、结构变异和拷贝数变异:
sentieon-cli dnascope-hybrid -r $REFERENCE --sr_aln $srbam --lr_aln $lrbam --rgsm RGSM -m $MODEL_BUNDLE -t $THREADS -g --skip_multiqc ${SAMPLEID}.vcf.gz
DNAscope Hybrid 流程需要以下必备参数:
-r REFERENCE:参考 FASTA 文件路径,还需要对应的 FASTA 索引文件(.fai)。
–sr_aln:输入的短读长 BAM 或 CRAM 文件,可通过多次传递该参数指定多个文件。
–lr_aln:输入的长读长 BAM 或 CRAM 文件,也可指定多个文件。
-m MODEL_BUNDLE:模型包路径,模型包文件位于 sentieon-models 代码库中。
sample.vcf.gz:单核苷酸变异和插入缺失的输出 VCF 文件路径,该流程要求输出文件以 .vcf.gz 结尾。
DNAscope Hybrid 流程还接受以下可选参数:
–pop_vcf POP_VCF:包含用于 DNAModelApply 注释信息的群体 VCF 文件。某些模型包需要此文件,且必须与模型包匹配。
-d DBSNP:用于标记已知变异的 dbSNP 数据库文件(VCF 或 bgzip 压缩的 VCF),仅支持一个文件。提供后可对变异添加 dbSNP refSNP ID 注释,需要 VCF 索引文件。
-b DIPLOID_BED:用于限制二倍体变异检测的参考区间(BED 格式),提供后只在该区间内检测二倍体变异。
-t NUMBER_THREADS:并行进程的计算线程数,可选,省略时默认使用服务器所有线程。
-g:以 gVCF 格式输出变异,输出 bgzip 压缩的 gVCF 文件及索引。
-h:打印命令行帮助并退出。
–dry_run:打印管道命令但不实际执行。
3. 基于未比对的短读长和长读长数据检测胚系变异
同样只需一条命令就能从未比对的短读长序列中检测单核苷酸变异、插入缺失、结构变异和拷贝数变异:
sentieon-cli dnascope-hybrid -r $REFERENCE --sr_r1_fastq HG002.novaseq.pcr-free.35x.R1.fastq.gz --sr_r2_fastq HG002.novaseq.pcr-free.35x.R2.fastq.gz --sr_readgroups "@RG\tID:HG002-1\tSM:HG002\tLB:HG002-LB-1\tPL:ILLUMINA" --lr_aln $lrbam --rgsm RGSM -m $MODEL_BUNDLE -t $THREADS -g --skip_multiqc ${SAMPLEID}.vcf.gz
DNAscope Hybrid 流程需要以下参数:
–sr_r1_fastq:输入的 R1 短读数据(gzip 压缩的 FASTQ),可以指定多个文件。
–sr_r2_fastq:输入的 R2 短读数据(gzip 压缩的 FASTQ),可指定多个文件。
–sr_readgroups:每个 FASTQ 文件的读取组信息,参数数量必须与 –sr_r1_fastq 一致。例如:–sr_readgroups "@RG\tID:HG002-1\tSM:HG002\tLB:HG002-LB-1\tPL:ILLUMINA"。
–lr_aln:输入的长读数据(uBAM 或 uCRAM 格式),可指定多个文件。
–lr_align_input:指定流程对输入的长读 BAM/CRAM 进行比对(如果这些 BAM/CRAM 是未比对状态)。
可选参数包括:
–sr_duplicate_marking:重复标记设置。markdup(默认)标记重复读取序列,rmdup 删除重复读取,none 跳过重复标记。
–lr_input_ref:用于解码输入长读取文件的参考 fasta,长读取 uCRAM 或 CRAM 输入时必须提供。可与 -r 参数指定的 fasta 不同。
–bam_format:输出对齐文件时使用 BAM 格式而不是 CRAM 格式。
三、流程输出
1. DNAscope Hybrid 流程输出文件
sample.vcf.gz:在 -b DIPLOID_BED 文件所定义的基因组区域内生成的单核苷酸变异和插入缺失变异检测结果。
sample.sv.vcf.gz:来自 Sentieon® LongReadSV 工具的结构变异检测。
sample.cnv.vcf.gz:来自 Sentieon® CNVscope 工具的拷贝数变异检测。
sample_deduped.cram:已比对、按坐标排序并标记重复(从输入的 FASTQ 中提取的短读数据)。
sample_mm2_sorted_*.cram:已比对和坐标排序的长读段(从输入的 uBAM、uCRAM、BAM 或 CRAM 中提取)。
sample_metrics:包含样本质量控制指标的目录。
四、实际测试运行
1. Sentieon 软件下载安装

2. 参考基因组下载
# 方法一:wget -c https://ftp-trace.ncbi.nlm.nih.gov/ReferenceSamples/giab/release/references/GRCh38/GRCh38_GIABv3_no_alt_analysis_set_maskedGRC_decoys_MAP2K3_KMT2C_KCNJ18.fasta.gz
# 方法二:curl -C - -0 --progress-bar https://ftp-trace.ncbi.nlm.nih.gov/ReferenceSamples/giab/release/references/GRCh38/GRCh38_GIABv3_no_alt_analysis_set_maskedGRC_decoys_MAP2K3_KMT2C_KCNJ18.fasta.gz
# 解压
gunzip GRCh38_GIABv3_no_alt_analysis_set_maskedGRC_decoys_MAP2K3_KMT2C_KCNJ18.fasta.gz
3. 测试数据下载
wget -c https://data.nist.gov/od/ds/ark:/88434/mds2-2336/input_fastqs/HG002_35x_PacBio_14kb-15kb.fastq.gz
wget -c https://data.nist.gov/od/ds/ark:/88434/mds2-2336/input_fastqs/HG002.novaseq.pcr-free.35x.R1.fastq.gz
wget -c https://data.nist.gov/od/ds/ark:/88434/mds2-2336/input_fastqs/HG002.novaseq.pcr-free.35x.R2.fastq.gz
wget -c https://42basepairs.com/download/gs/deepvariant/ont-case-study-testdata/HG002_R104_sup_merged.50x.bam
需要说明的是,GIAB 早期使用的 ONT 数据为 R9.4.1 版本,对插入缺失的检出率相对较低,而目前业界普遍推荐使用 R10.4 版本以获得更好的表现。
4. 分析运行
sbatch HG002_35X_ill_10X_ONT_R104.sh
sbatch HG002_35X_ill_15X_PB.sh
5. 质控统计
第二代测序数据的质控信息如下:
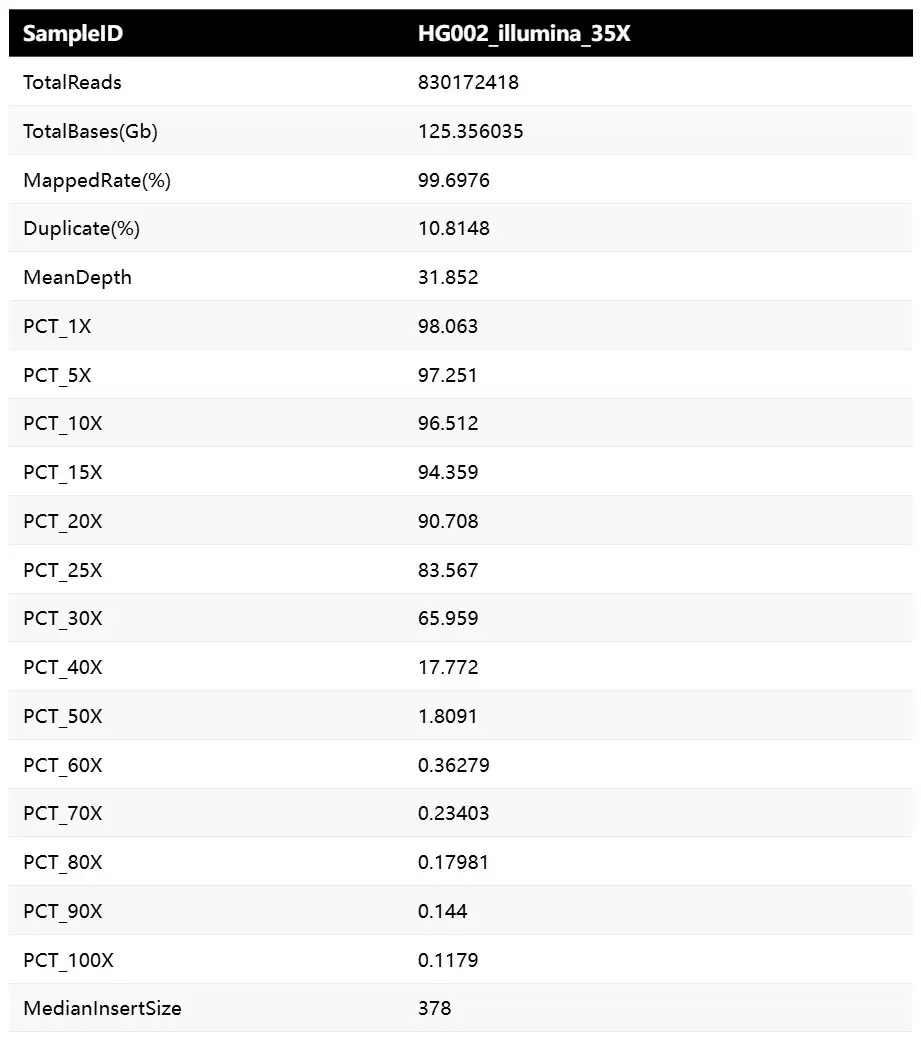
第三代测序数据的质控信息如下:

6. 分析结果一致性比较
DeepVariant 被公认为精度标杆——它开创性地将测序数据图像化,并利用深度学习进行变异识别,在多项 PrecisionFDA 挑战赛中表现优异,常被视为评估新算法精度的“金标准”;Dragen 也是一款广受好评的优秀商业软件。本文使用这两款软件与 Sentieon DNAscope Hybrid 进行性能对比。
DeepVariant (v1.8.0) 使用默认设置,仅从长读长数据中生成变异结果。
Dragen 的短读长准确性指标来自近期一项已发表研究中下载的 VCF 文件。
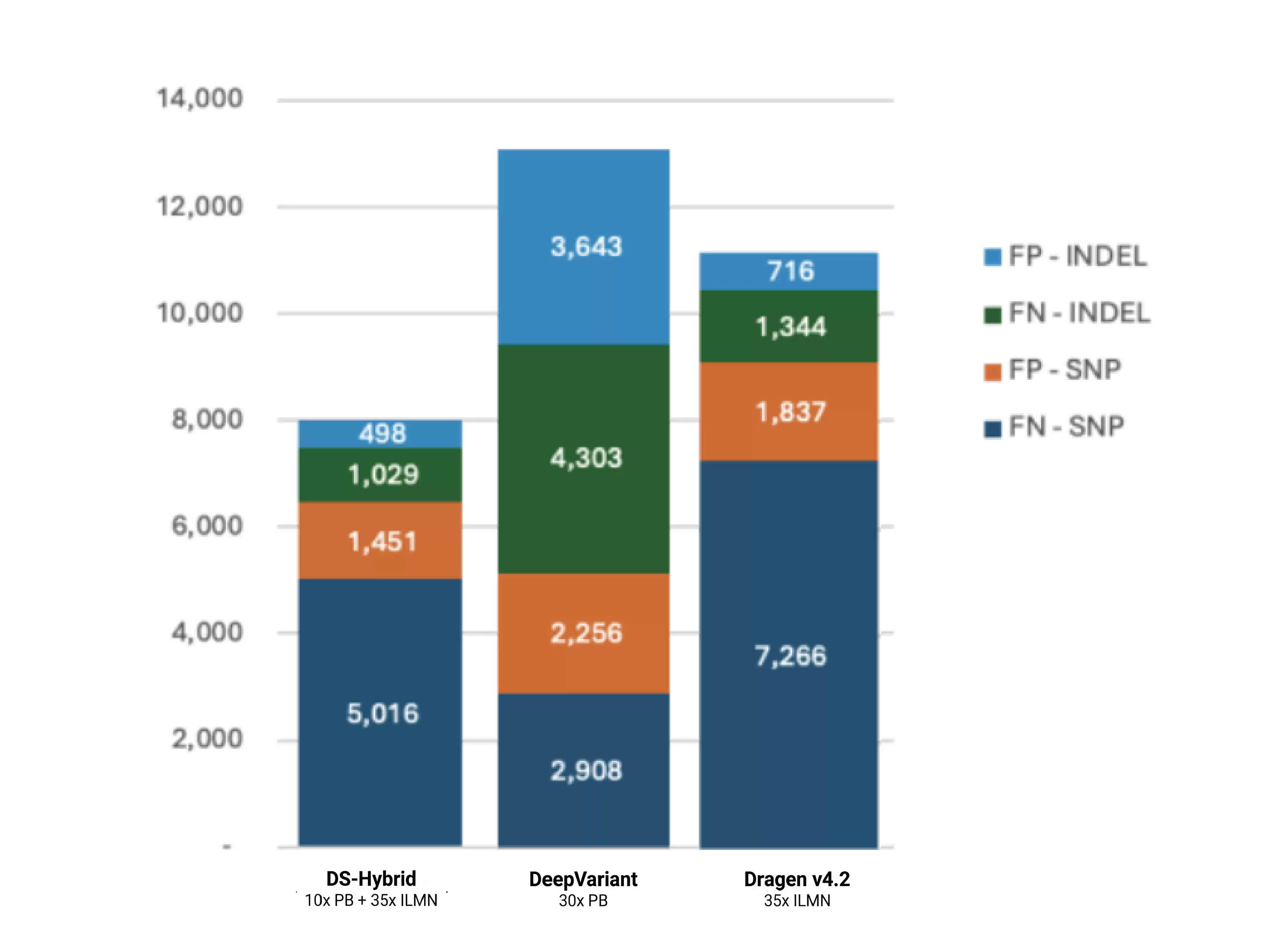
通过 HG002 参考样本,详细比较了 Illumina+PB 与 Illumina+ONT 数据在单核苷酸多态性和插入缺失检测上的准确性。下面两个表分别列出了单核苷酸多态性和插入缺失的假阳性与假阴性统计。
- Illumina+PB 数据:各流程的变异检测准确性统计:
- Illumina+ONT 数据:各流程的变异检测准确性统计:
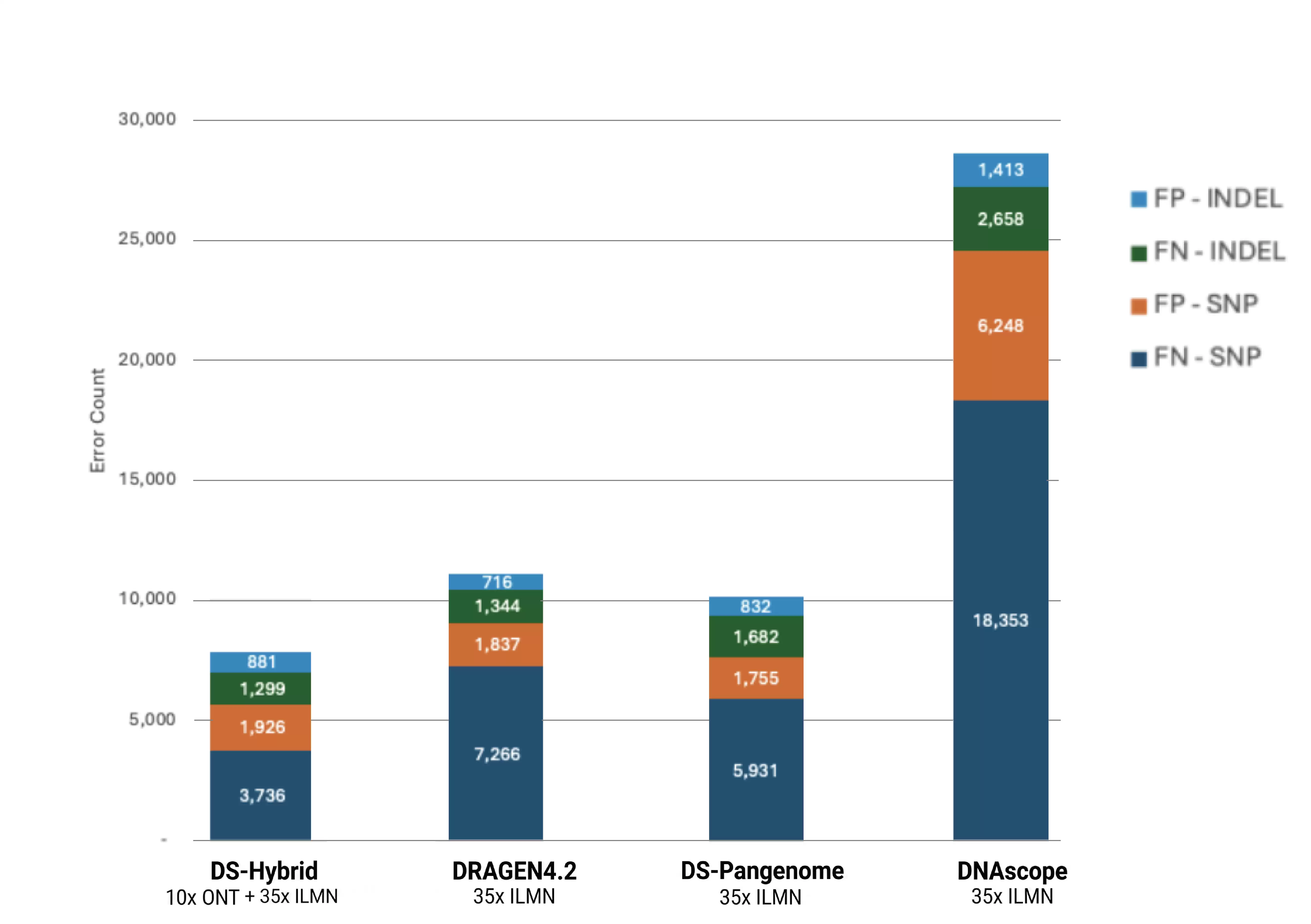
结果非常明确:DNAscope Hybrid 的变异识别准确性均高于单独使用短读长或长读长的方法,充分体现了 Sentieon DNAscope Hybrid 混合分析策略的稳健性和广泛适用性。未来,泛基因组信息也可以集成到 DS-Hybrid 流程中,从而提供更高的准确性。
7. 耗时统计
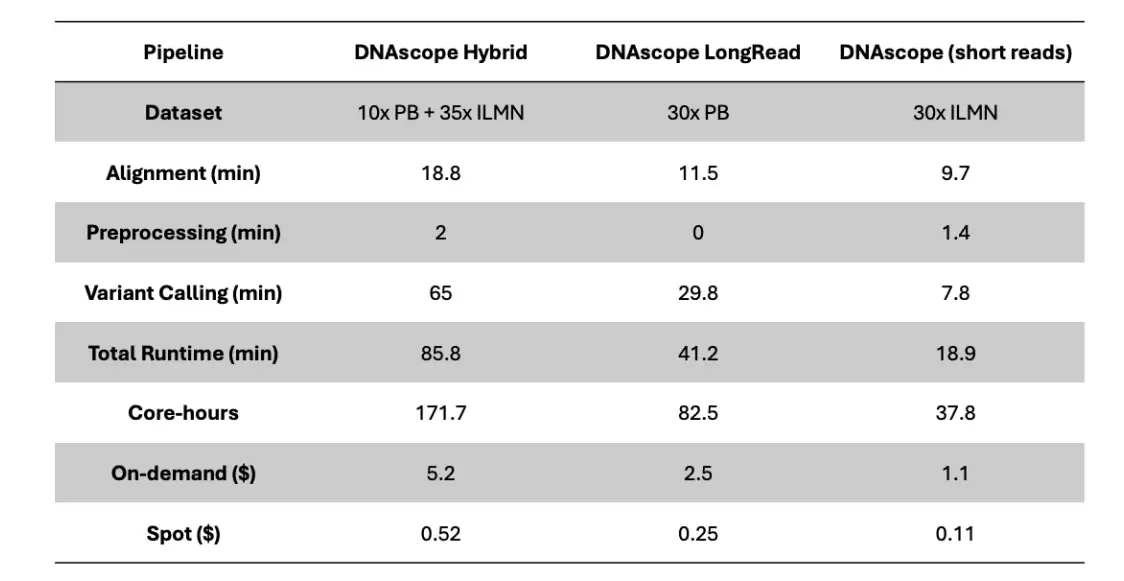
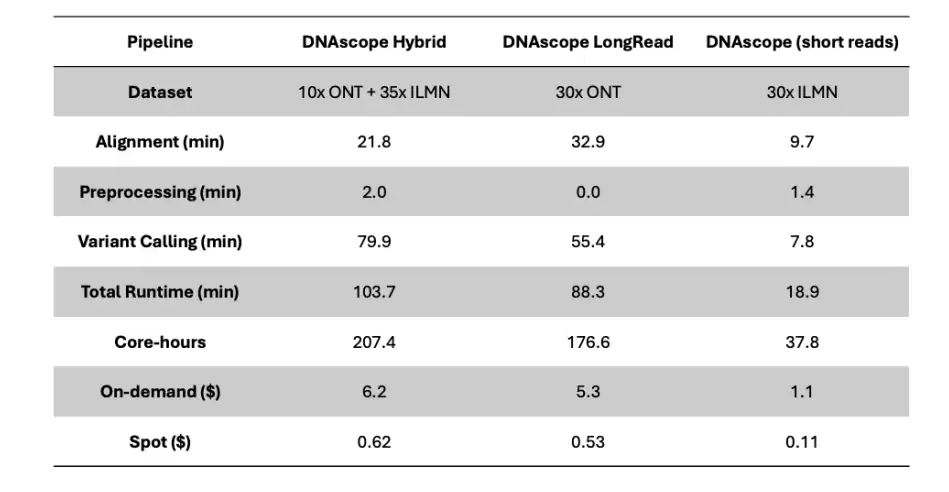
本次基准测试统一采用 Azure Standard HB120rs v3 实例(120 个 vCPU,456 GiB 内存,512GB 高级 SSD)。下表分别展示了 Illumina+PB 和 Illumina+ONT 数据下各流程的运行时间与计算成本。
需要说明的是:DNAscope Hybrid 流程输出单核苷酸变异/插入缺失/结构变异/拷贝数变异;DNAscope LongRead(长读长)流程输出单核苷酸变异/插入缺失/结构变异;DNAscope(短读长)流程输出单核苷酸变异/插入缺失/拷贝数变异。
- Illumina+PB 数据:计算资源基准结果:
- Illumina+ONT 数据:计算资源基准结果:
五、总结
在 120 核 456GB 内存的测试环境下,35X 人类全基因组测序数据加上 10X PB 数据仅需 85.8 分钟;35X 人类全基因组测序数据加上 10X ONT 数据也只需 103.7 分钟。分析时间大幅缩短,科研成果转化速度自然显著提升。
Sentieon 持续优化算法的运行效率,为科研工作者提供更快速、更经济的基因检测方案。如果您手头有需要检测的数据,Sentieon 的混合分析方案值得一试。
Sentieon 软件介绍
Sentieon 是一个完整的纯软件基因变异检测二级分析方案,其分析流程完全遵循 BWA、GATK、MuTect2、STAR、Minimap2、Fgbio、picard 等金标准的数学模型。在保证与开源流程分析结果一致的前提下,大幅提升全基因组测序、全外显子组测序、Panel、UMI、ctDNA、RNA 等测序数据的分析效率和检出精度,并支持目前所有第二代和第三代测序平台。
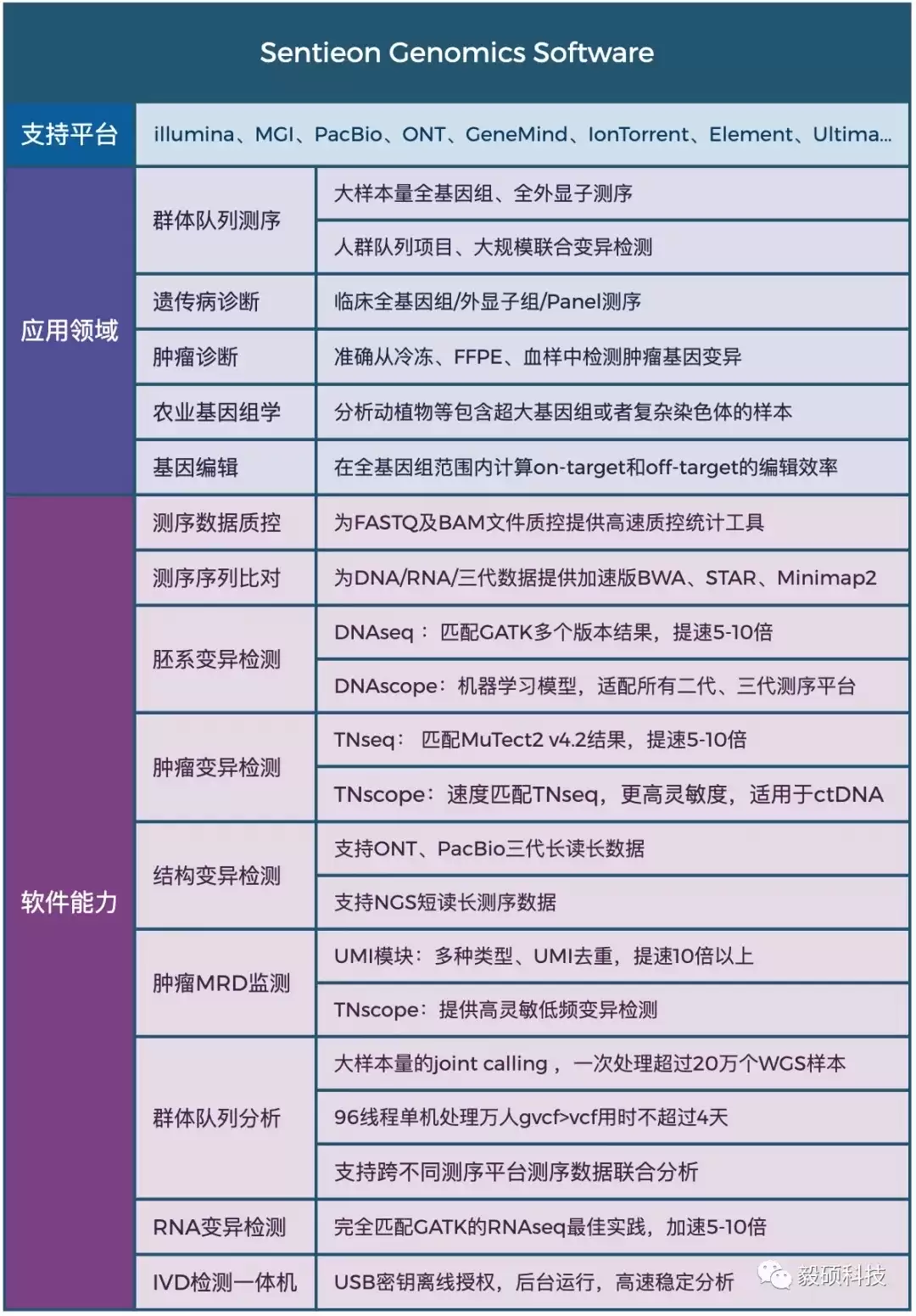
Sentieon 软件团队在软件开发及算法优化工程方面拥有丰富经验,致力于解决生物数据分析中速度与准确度的瓶颈。团队为分子诊断、药物研发、临床医疗、人群队列、动植物等多个领域的合作伙伴提供高效精准的软件解决方案,共同推动基因技术的发展。
截至 2026 年 4 月,Sentieon 已在全球范围内为 1860 多家用户提供服务,累计处理超过 7400 PB 数据。其成果被 NEJM、Cell、Nature 等世界顶级期刊广泛引用,引用次数超过 1900 篇。此外,Sentieon 连续多年在 Precision FDA、Dream Challenges 等权威评比中获奖,在业内获得了广泛认可。




