企业在探讨数据泄露治理方案时,为何不能仅仅依赖 Symantec 这类安全产品?原因在于,终端、网关、邮件及文件外发仅构成风险链条的一部分,而数据库才是敏感数据最为核心的承载载体。许多团队最初是从跨平台数据库工具等需求切入数据库选型,但一旦深入讨论防数据泄露,关注点便会自然聚焦到数据库内部。

因此,企业在思考“如何防止数据泄露、如何做好敏感数据管理”时,通常不会只局限于边界侧和终端侧的能力,还会进一步关注数据库侧的识别、分级、访问控制、脱敏展示以及审计治理。这构成了一个更为完整的数据治理链路。
许多团队在提及“防数据泄露”时,第一反应往往优先考虑终端防泄露、文件外发管控、邮件与网关策略、云平台自带安全机制以及账号权限与审计。这些能力虽常见且各有适用场景。
然而,当问题深入至数据库内部时,企业还需长期面对另一类挑战:哪些表和列属于敏感数据?敏感字段是否已完成分类分级?无权限人员能否直接查看敏感列内容?新增字段出现后能否持续识别?敏感数据访问行为能否实现持续统计与跟踪?这也正是为什么在企业防数据泄露场景中,数据库侧治理会独立形成一套实践路径的原因。
先把问题拆开:防数据泄露不只是防外发
在技术社区中,许多关于“数据泄露”的讨论默认偏向终端和边界侧,例如文档能否复制、文件能否上传、邮件附件能否外发,以及某些设备能否访问内部数据。对于已将数据库审计纳入日常流程的团队而言,敏感字段识别、分级和策略执行本就应置于同一链路中。
这些问题固然重要,但如果企业的数据核心仍保存在数据库内,数据库侧就必须继续回答另外几件事:敏感数据具体落在哪些列?这些列是否已分级?谁可以查看明文、谁只能看到脱敏结果?新增数据源后是否需重新人工梳理?组织当前共有多少敏感列和多少访问记录?换言之,企业防数据泄露若只停留在终端和边界层,数据库内部的大量敏感数据治理问题并不会自动消失。
Symantec 这类产品和 NineData,本来就不在同一层面
Symantec 这类产品更常见于终端侧控制、文件与内容识别、边界或外发场景管理,以及广义的数据防泄露体系。而数据库侧这条路径,重点讨论的是数据源中的敏感列识别、敏感数据分类分级、脱敏算法配置、未授权用户的敏感列查看限制、定期扫描与持续纳管,以及敏感数据访问统计与看板。
简而言之,它们解决的根本不是同一层面的问题。
数据库侧敏感数据管理,第一步往往是先找到敏感字段
许多企业并非完全不知自身存在敏感数据,而是难以持续回答以下问题:哪些库表中包含手机号、邮箱、证件号、地址和账号信息?哪些字段属于高敏感级别?是否所有字段均已被识别?新增字段后原有规则能否继续覆盖?
在这一步,“先识别,再纳管”是关键思路。将数据库中的某一列或多列设置为敏感列,通过数据类型、识别规则和扫描策略自动识别敏感字段,是一项标准做法。即便平台能力延伸至智能 SQL 审核,数据库侧敏感数据管理仍需建立在分类分级与规则持续生效的前提之上。
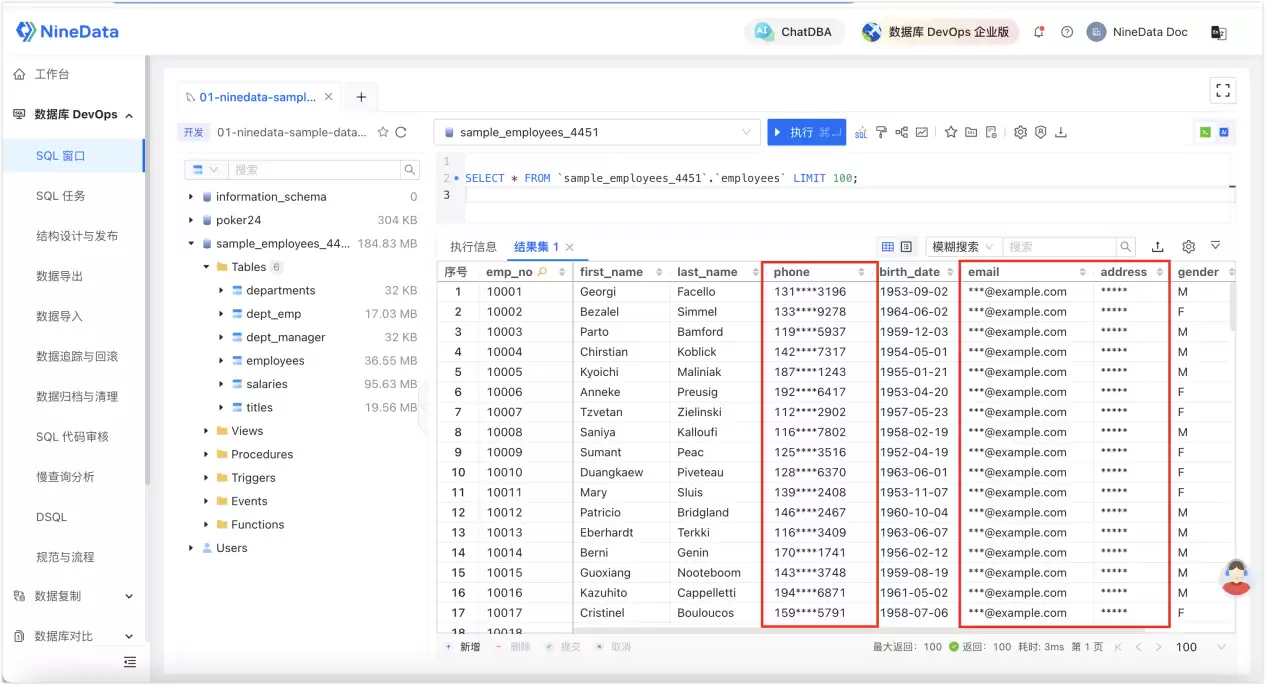
敏感数据管理不只是识别字段,还要继续做分类分级
它将敏感数据管理拆解为几个核心要素:敏感等级、数据类型、脱敏算法和识别规则。其中,敏感等级常用于区分不同级别的数据保护要求。
一种成熟的做法是预置 S0 ~ S5 共 6 个敏感数据等级,并配套相应的识别规则,实现自动识别敏感数据并完成脱敏。未经授权的用户尝试访问敏感列时,只会看到脱敏后的数据。这一机制的核心在于,它把“识别”与“执行”紧密绑定在一起。
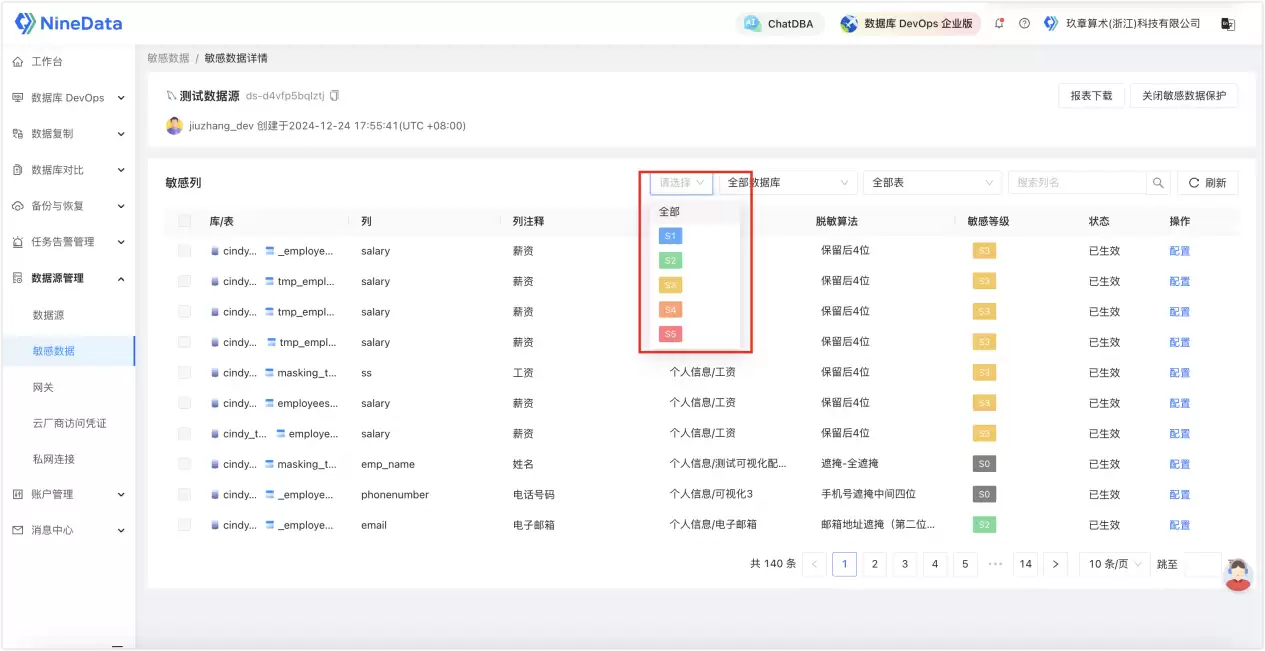
数据库侧防泄露,关键不只在识别,还在能不能看见
许多团队在做敏感数据治理时,难点往往不在于找到字段,而在于后续的访问控制。如果某个字段已被识别为敏感列,那么还需回答一个直接问题:无权限的人到底能否看到该列内容?这要求数据库侧提供敏感列保护能力:未经授权查看敏感列的用户通常无法直接看到该列内容,需发起审批流程。尤其是在多团队协作场景下,评估工具时不能仅停留在功能列表,还需考察其能否承接审批控制与访问审计。
同时,敏感列还可结合脱敏算法进行展示控制,这使数据库侧治理又向前迈进一步:它不只是识别字段,也不只是标记等级,而是开始真正影响具体的查看行为。对企业而言,这一点至关重要,因为敏感数据管理若仅停留在“识别”阶段,而未能落实至“访问与展示”,其对日常使用的影响将十分有限。
持续扫描,比一次性清点更适合企业环境
如果敏感数据治理仅依赖一次性盘点,后续很容易出现这样一种情况:最初清点时尚算完整,但过一段时间便跟不上变化。更好的做法是同时提供单次扫描与周期性扫描,既支持全库扫描,也支持指定数据库扫描,这意味着可以将敏感字段识别从“一次任务”转变为“持续动作”。
数据库侧治理还需要具备可见性,而不仅仅是规则。如果敏感数据管理只停留在配置层,团队后续仍会面临一个问题:当前组织内到底有多少敏感数据?哪些库已开启保护?哪些等级占比更高?敏感访问行为多不多?一个完善的敏感数据 Dashboard 能够呈现当前组织内敏感数据的整体状况。
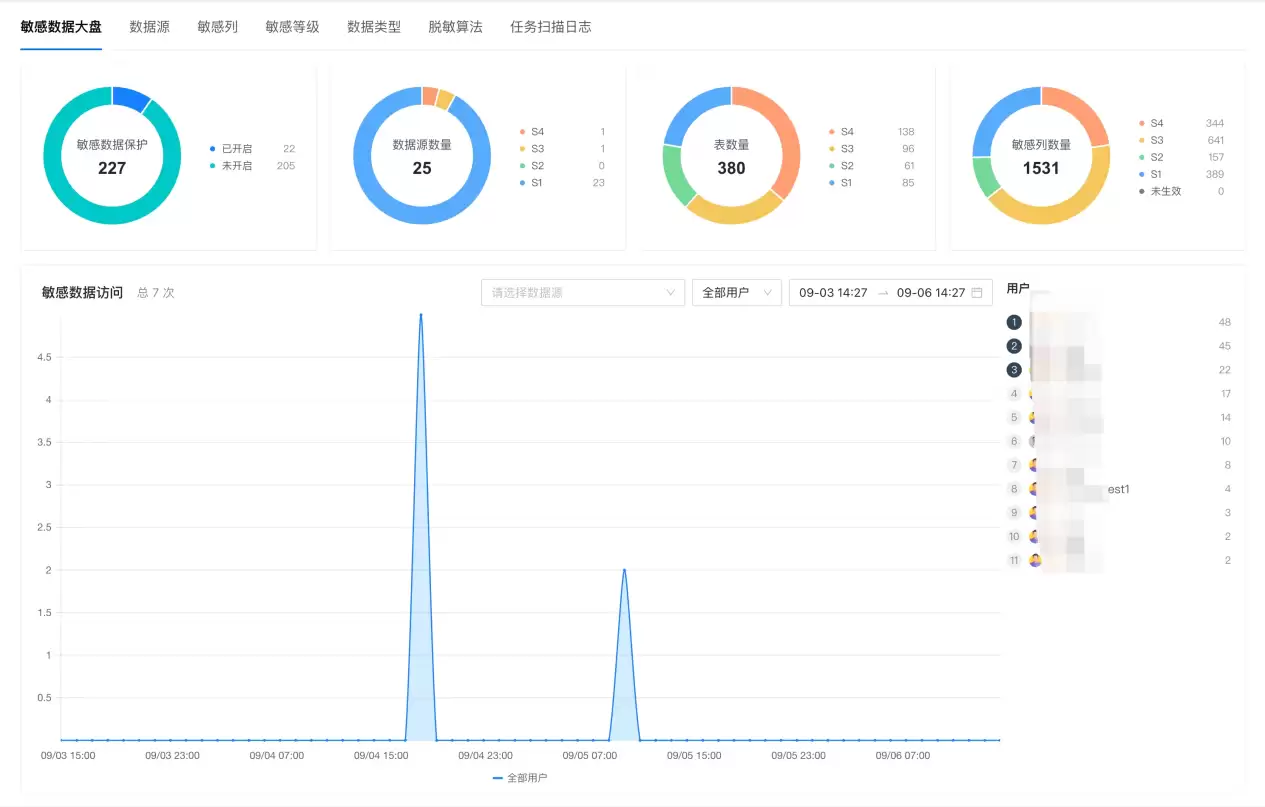
从公开能力来看,这类看板通常涵盖支持敏感数据保护的数据源数量、已启用敏感数据保护的数据源情况、涉及敏感数据的表数量、敏感列数量以及敏感数据访问次数。其作用不仅是“方便看一眼”,更是帮助团队从单个字段配置逐步走向整体数据治理视角。
为什么企业防数据泄露不能只看 Symantec
因为企业面临的并非单一维度的数据流动问题,而是多层次的数据治理问题。如果只关注终端、文件、外发和边界控制,那么数据库内部这条链路还需要持续补齐:哪些列是敏感数据?是否已做分类分级?未授权用户是否仍能查看?是否有脱敏展示?能否持续扫描新增字段?能否看到组织层面的敏感数据状态?
哪些团队更适合将数据库侧这条路径纳入考量?如果团队已拥有边界侧或终端侧的数据安全体系,但数据库侧仍存在多个数据库实例分散在不同团队、难以持续梳理敏感列、新增字段后缺少自动识别能力、仅做了账号权限但未实现敏感列细粒度治理、数据库内敏感数据访问情况缺乏统一视图,并且希望在数据库侧补齐分类分级、脱敏和访问控制,那么这就是一个值得深入探讨的方向。
FAQ
企业防数据泄露为什么不只看 Symantec?因为在企业数据治理场景里,数据库侧始终是敏感数据的重要承载位置。
如果只将注意力放在终端、网关和文件流转,许多数据库内部的问题仍需单独回答:哪些字段是敏感数据?谁能看?怎么看?如何持续识别?怎样做分级和脱敏?因此,即使入口需求来自数据对比,最终仍要回到数据库内部的敏感数据链路是否被长期管住这一问题。
这里讨论的不是更广义的边界防护,而是数据库侧这条治理路径:敏感数据识别、分类分级、脱敏展示、查看限制和持续扫描。
对于希望将数据库里的敏感数据纳入统一治理的团队而言,这种方式更容易进入方案比较的视野。




