在开发者社区中,有一个老生常谈却又极其令人困扰的问题:同一款模型,输入内容相差无几,线上表现却忽高忽低。最棘手的是,它往往不会直接抛出错误,而是以一种“薛定谔的状态”若隐若现。
- 复杂任务的输出结果深度不稳定,时而令人惊艳,时而表现拉胯;
- 回答的结构完整性如同开盲盒,步骤可能突然缺失,推理理由也变得肤浅;
- 延迟与重试行为毫无规律可循,呈现出明显的时段性抖动。
面对这类问题,团队的第一反应通常是调整Prompt或排查业务代码。这无可厚非,但在多中转、多链路的生产环境下,另一个常见根因是:模型一致性与路由一致性没有被持续验证。
本文不输出情绪,直接提供一套可复用的工程排查路径,按步骤执行即可:
- 首先判断是否存在来源或路由方面的风险;
- 然后精准定位到具体的风险来源;
- 通过隔离对照实验,确认问题是否源于链路一致性;
- 最后通过复检与恢复,形成完整的闭环处置。
一、先定义问题边界:不是“模型真假”,而是“执行一致性”
在生产环境中,讨论“模型是否被偷偷替换”很容易陷入无休止的扯皮。从工程视角来看,一个更可执行、更客观的表述是:
- 每一次请求,是否都能稳定地落到同一个能力路径上?
- 路由规则及相关检查状态,是否长期保持稳定?
- 关键的性能与质量指标,是否未超出可接受的波动范围?
换句话说,我们优先验证的是“执行一致性”,而非做出主观定性判断。
这样定义有两个明显好处:
- 结论可以基于数据证据,团队内部沟通时不存在歧义;
- 后续的处置动作可以模板化,便于复盘和自动化处理。
二、为什么“同模型名”仍会出现显著差异
在多中转、多入口的复杂环境中,“标签一致”与“路径一致”完全是两码事。常见的差异来源主要集中在以下几点:
- 来源对象不同:不同的账号映射、不同的API凭证绑定,可能指向完全不同的后端服务集群。
- 路由策略漂移:根据时段或系统负载,智能路由可能将请求导向不同的处理路径,从而导致表现差异。
- 检查状态过期:部分安全检查或状态验证长时间未刷新(stale checks),导致有风险的对象未被及时复核。
- 异常重试分叉:不同的入口或客户端,其重试策略(例如间隔、次数、降级逻辑)各不相同,会显著放大最终结果的波动。
因此,看到前端传入的模型名一模一样时,千万别想当然地认为能力路径是恒定的。
三、第一步:全局健康总览,先证明确有风险信号

图1:来源健康总览(Overall source health)
排查第一步,建议先查看总览层的数据,而不是直接埋头捞日志。一个合格的总览看板至少应包含:
- 整体健康分数;
- 健康来源数量,以及待复核来源的数量;
- 最近24小时内出现的风险类型(例如路由漂移、检查过期等);
- 最新一次检查的时间点。
如果总览看板上已经显示“待复核来源 > 0”,或者健康分持续偏低,那么基本可以说明问题可能不仅出在Prompt层,应该立即转向来源级排查。
这一步的核心价值在于:将团队主观的“体感变差”,转化为系统已经观察到的风险信号。
四、第二步:来源级下钻,锁定高风险对象
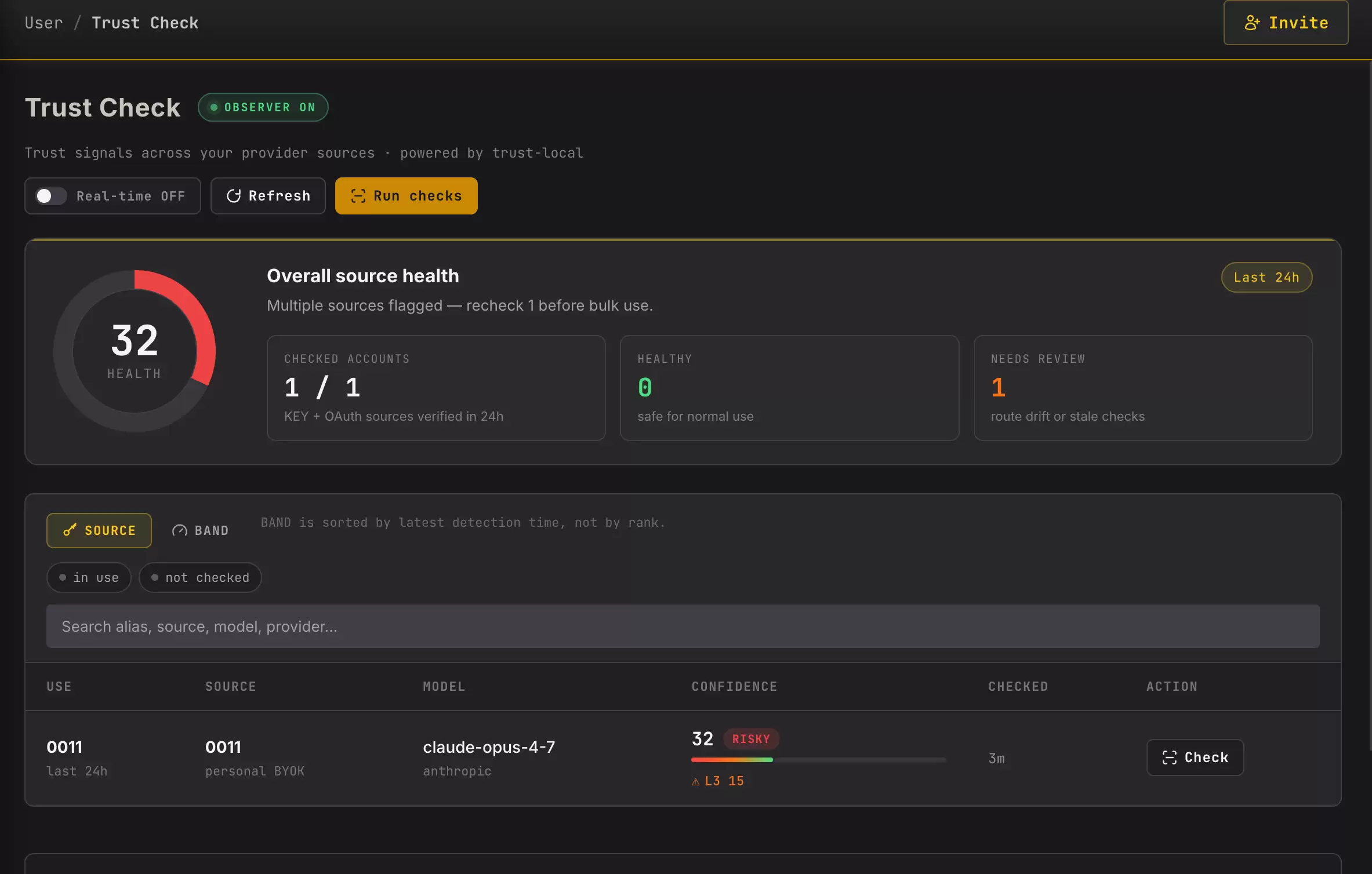
图2:来源明细(risk/confidence/check)
进入来源明细后,优先关注这三类信号:
risk_level:是否被标记为有风险(risky);confidence_score:是否长期处于低位;checked_at:检查时间是否已经过期,或者在短周期内(如几小时内)震荡不安。
如果能找到一个来源,同时满足“风险等级高”、“置信度低”、“检查状态异常”这三个条件,那么它就是优先隔离对象。
这一步要求输出可执行的结论,而不是一句模糊的“感觉这路不太对”。例如,结论可以写成:
“来源 A 在最近一个观察窗口内检测到路由漂移风险,置信度已低于预设阈值,建议将其纳入隔离观察队列。”
五、第三步:隔离对照验证,避免误判
识别出某个来源存在风险后,先别急着定性。先做一个最小化的对照实验:
- 临时将高风险来源隔离开来;
- 使用完全相同的任务和评估标准,将请求切到一个健康来源上;
- 对比两组实验的以下关键指标:成功率、响应延迟、输出结构完整性、重试放大率。
如果切换后,所有关键指标都得到显著改善,那么“链路一致性异常”这个判断的置信度就会非常高。
这一步,是防止因误判而采取错误动作的核心环节:先验证问题的可复现性,再来讨论归因。
六、第四步:复检恢复,把处理从“临时动作”变成“标准流程”
许多团队的问题不是“查不到”,而是“查到之后如何恢复”缺乏标准流程。
建议恢复操作前,必须满足三个条件:
- 复检通过(来源状态已恢复正常);
- 在连续观察窗口内,没有新的风险信号出现;
- 关键业务指标已回到基线区间。
恢复动作一定要留痕,至少应记录:
- 谁执行了恢复操作?
- 基于什么证据做出的恢复决策?
- 恢复后观察了多久才确认正常?
这样,下次再出现类似问题,团队就可以直接复用这套历史处置模板,效率会大幅提升。
七、最小指标集:把“体验问题”变成“运维对象”
为了让整个流程可衡量,建议至少维护以下指标:
- 来源健康占比(健康/待复核/有风险的比例);
- 路由漂移频次(按小时或日粒度统计);
- 检查新鲜度(过期的检查项占总数的比例);
- 重试放大率(计算方式:重试请求数 / 首次请求数);
- 隔离处置成功率;
- 复检恢复的一次通过率。
指标不求多,但必须能支撑起“发现—定位—处置—恢复”的完整闭环。
八、常见误区与改进建议
这里总结几个最易踩坑的点:
误区 1:只看总量,不看来源维度
每天只盯着总请求量或总成本,根本看不出来源层的风险。建议至少保留来源维度的数据,并且时间粒度要细化到分钟级。
误区 2:只告警,不联动处置
告警体系再花哨,如果没有配套的隔离、降级、复检流程,问题依然会反复出现,告警最终会变成“狼来了”。
误区 3:只改Prompt,不查链路
优化Prompt确实能改善结果,但当根因是路由一致性问题时,改一万遍Prompt收益也十分有限,且结果极其不稳定。
九、实践落地建议
对于中小规模团队,不必一开始就搭建大而全的平台。建议优先完成一个最小闭环:
- 先搭建一个来源健康的总览看板;
- 设置规则,让高风险来源能够被自动标记并进入review状态;
- 对核心业务任务,配置策略优先使用健康来源;
- 将隔离-复检-恢复的流程固化下来,形成文档或工具;
- 每周花一点时间复盘风险事件和处置效果。
这套方法的价值,不在于让系统“永不波动”,而在于当波动出现时,团队能够快速收敛问题范围,并且有据可查地进行追溯和恢复。
十、结语
“同样标注为Claude,效果却差异明显”,这在多链路生产环境中,真的不是什么稀奇事。
与其陷入“是不是被偷偷替换了”这种主观争论,不如先将问题转化为可验证的执行一致性排查流程:
- 先看总览信号;
- 再做来源下钻;
- 然后隔离对照;
- 最后复检恢复。
等这条链路跑通了,你就会发现,很多过去觉得“说不清道不明”的质量波动,都能被精准定位、高效处置和系统复盘。
这也是生产稳定性治理中最重要的一点:把不确定的体验,变成可证据、可执行、可复用的工程流程。