东南大学D4Lab新方案LoPT免全模型反传更省更快
时间:2026-06-07 16:43
为什么要重新思考大模型后训练? 如今的大语言模型在完成预训练后,通常还需要经过SFT(监督微调)、DPO(直接偏好优化)、RLHF(基于人类反馈的强化学习)、GRPO(组相对策略优化)等后训练流程,才能真正成为可用的系统。这些方法的监督信号各不相同、优化目标各异、训练流程也彼此有别,但它们往往共享一
为什么要重新思考大模型后训练?
如今的大语言模型在完成预训练后,通常还需要经过SFT(监督微调)、DPO(直接偏好优化)、RLHF(基于人类反馈的强化学习)、GRPO(组相对策略优化)等后训练流程,才能真正成为可用的系统。这些方法的监督信号各不相同、优化目标各异、训练流程也彼此有别,但它们往往共享一个默认设定:任务损失会端到端地反向传播,穿过整个Transformer结构。
这种设定自然且通用,但在后训练阶段却未必总是最优。原因很简单:预训练数据覆盖广泛,而后训练数据往往集中在很窄的领域。一个后训练数据集可能只强调某种回答格式、某类指令遵循风格、某个数学任务族、某种奖励信号或某类对齐偏好。如果这些狭窄任务的梯度一路反向传播到模型底层,就可能导致三个问题:显存占用更高、反向依赖链条更长、更容易扰动预训练学到的表示。
完整反向传播意味着需要保存更多的跨层激活值,反向计算图覆盖整个Transformer堆栈;任务目标需要穿越完整的模型深度进行信用分配,优化路径更长;而低层和中层表示通常承载了大量通用能力,如果窄任务梯度直接重塑这些表示,模型在那些后训练数据未重点覆盖的能力上可能出现退化。因此,LoPT提出的问题不是“再换一个损失函数吗”,也不是“再加一个适配器吗”,而是:任务梯度究竟应该传播多远?
方法:在模型中间插入梯度边界
LoPT的结构可以直接从下图看出:
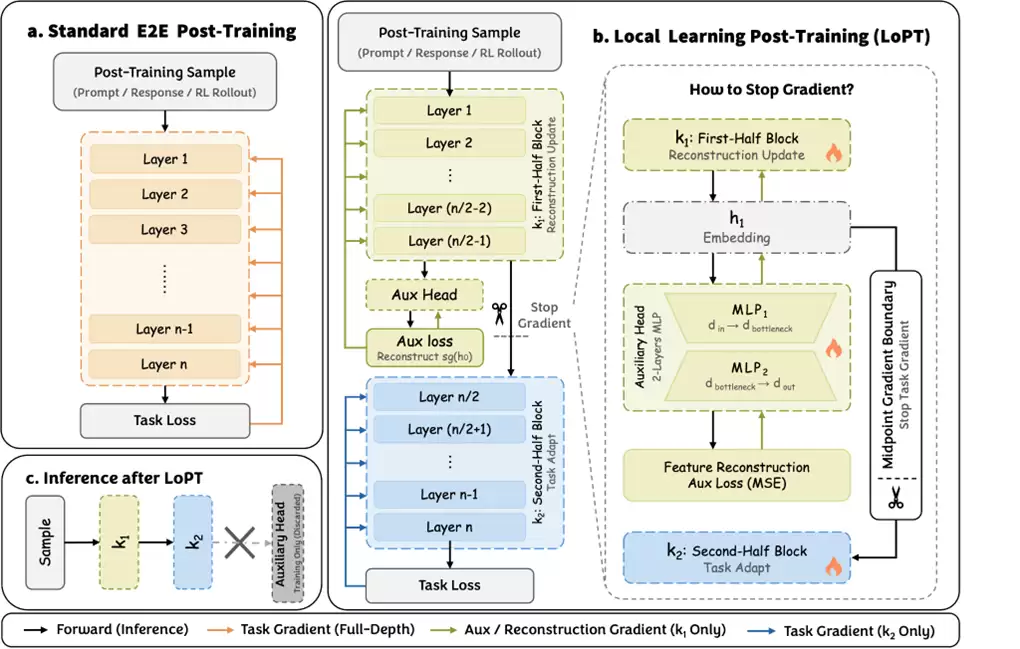
图:LoPT方法概览。中点stop-gradient boundary将任务梯度限制在后半模型,同时前半模型通过局部特征重建保持可训练。
核心机制非常简单:Transformer被划分为前半部分k₁和后半部分k₂;k₂接收标准任务损失(例如SFT损失或GRPO损失);k₁不直接接收任务损失的梯度;在中点通过detach() / stop-gradient截断任务梯度;k₁仍然通过轻量级的特征重建目标保持可训练;辅助头在训练后被移除,推理路径与普通因果语言模型一致。
这意味着LoPT并非简单冻结前半模型。如果只是冻结,前半模型就完全停止了更新;而LoPT的前半模型仍然会通过局部重建目标继续学习,维持一个稳定、可用且与后半模型兼容的表示接口。真正做的改动是:任务梯度不再全深度反向传播,但前半模型仍通过局部目标维护稳定的接口。
实验结果:不仅节省显存,LoPT还能带来更稳定的表现
我们不会把所有表格都展示出来,只挑选几个最具代表性的结果。
1. SFT:后训练数据较窄时,LoPT能有效缓解能力退化
在Alpaca-52K → Llama-3.1-8B-Instruct这个设置下,标准端到端SFT在部分评测能力上出现了明显下降。这其实很符合直觉:Alpaca-52K是一个通用指令数据集,并不会充分覆盖数学推理、严格指令遵循等所有能力。如果任务梯度一路反向传播到模型底层,就可能把预训练中习得的一些通用能力“冲刷掉”。
LoPT的表现更加稳定。它不让任务梯度直接进入前半模型,而是让前半模型通过局部重建维持表示接口,因此能够减少这种后训练带来的能力退化。
| Metric | E2E SFT | LoPT SFT | Gain |
|--------|---------|----------|------|
| GSM8K | 46.62 | 72.10 | +25.48 pp |
| IFEval | 30.50 | 46.03 | +15.53 pp |
| Seven-benchmark a vg | - | - | +7.22 pp |
| Peak memory | 60.6 GB | 38.9 GB | ↓36% |
| Training speed | 14,483 tok/s | 14,882 tok/s | ↑3% |
也就是说,在这个配置下,LoPT不仅降低了显存占用,还成功挽回了端到端SFT中最明显的能力下降。
2. GRPO:主任务性能不降,策略更新成本更低
GRPO的训练成本中,策略更新阶段非常关键。LoPT在这个阶段的收益非常直接:更新时更省显存,速度也更快。在GSM8K GRPO → Qwen2.5-7B-Instruct上,LoPT保持主任务表现与端到端接近,同时在部分留出指标上表现更稳定。
| Metric | E2E-GRPO | LoPT-GRPO | Gain |
|--------|----------|-----------|------|
| GSM8K | 88.70 | 89.09 | +0.39 pp |
| IFEval | 56.01 | 59.70 | +3.69 pp |
| Peak memory | 75.39 GB | 59.66 GB | ↓21% |
| Step time | 1.71 s/step | 1.56 s/step | ↓9% |
这里的关键不是LoPT在GRPO上大幅提升了主任务指标,而是:在保持GRPO适配能力的同时,LoPT让策略更新更经济。对于强化学习风格的后训练来说,这个优势非常实用。
3. LoRA:LoPT可以与参数高效微调叠加使用
LoRA控制的是参数化方式,LoPT控制的是任务梯度传播范围。两者并不冲突。在Qwen2.5-7B → MetaMathQA 100K → LoRA rank=32的SFT设置中,LoPT结合LoRA相比纯端到端LoRA继续带来收益。
| Metric | E2E LoRA | LoPT LoRA | Gain |
|--------|----------|-----------|------|
| IFEval | 53.05 | 55.45 | +2.40 pp |
| GSM8K | 84.49 | 85.13 | +0.64 pp |
| Wins | - | 7/7 | - |
| A verage | - | - | +0.67 pp |
| Peak memory | 68.37 GB | 43.88 GB | ↓36% |
| Throughput | 28,794 tok/s | 30,524 tok/s | ↑6% |
这表明LoPT并非LoRA的替代品,而是可以与之叠加使用:LoRA负责低秩更新,LoPT负责控制任务梯度的传播深度。
4. DeepSpeed-ZeRO3:即便系统优化已开启,LoPT依然有效
DeepSpeed-ZeRO3已经是非常常用的系统级显存优化技术。LoPT在此基础上仍能从梯度路由的角度进一步节省开销。在Qwen2.5-7B × 8×A100 × bs=4 × seq=1024 × ZeRO3设置中:
| Metric | E2E ZeRO3 | LoPT ZeRO3 | Gain |
|--------|-----------|------------|------|
| Peak memory | 25.18 GB | 20.42 GB | ↓19% |
| Throughput | 21,066 tok/s | 22,413 tok/s | ↑6% |
这组结果非常关键,说明LoPT并非只在普通训练栈中有效。即使已经使用了ZeRO3这样的系统级优化,LoPT仍然可以从任务梯度传播路径这个维度带来额外的收益。
我们究竟测试了哪些场景?
为了验证LoPT不是单一技巧,我们在多个模型、多个后训练任务、多个数据集和多个系统栈组合上进行了测试。模型包括Qwen3-4B、Qwen2.5-7B-Instruct、Llama-3.1-8B-Instruct,以及Qwen2.5-32B-Instruct的合理性验证;后训练任务包括SFT和GRPO;SFT数据集包括Alpaca-52K、Tulu-3 SFT Mix 100K、Magpie-Pro 100K、MetaMathQA 100K;GRPO数据集包括GSM8K-train和NuminaMath;评测覆盖MMLU、IFEval、ARC-Challenge、GSM8K、HellaSwag、TruthfulQA、Winogrande;系统栈组合覆盖梯度检查点、LoRA、DeepSpeed-ZeRO1/2/3、流水线并行。
整体结论是:LoPT在SFT和GRPO中都能降低训练成本;在LoRA、ZeRO、梯度检查点、流水线并行等常见训练栈下也可以叠加使用。
LoPT的定位:不是另一种PEFT,而是一种梯度路由策略
LoPT最值得关注的地方,不仅在于节省显存、也不仅在于训练速度更快。它真正提出了一个新的后训练视角:后训练优化的对象不只是损失函数、参数量和系统栈,还包括任务梯度的传播范围。
过去大家经常讨论LoRA是否更节省参数、ZeRO / DeepSpeed是否更节省显存、梯度检查点是否更适合当前配置、流水线并行如何扩展批大小和序列长度。LoPT补充了另一个维度:任务梯度应该传播多远,本身就是一个可以设计的变量。
因此,LoPT既不是另一个适配器,也不是单纯的显存技巧。它更像是一种面向大模型后训练的梯度路由策略。
哪些场景最适合使用LoPT?
LoPT尤其适用于以下四类场景:
第一,后训练数据范围较窄(例如某类指令数据、某类数学推理数据、某种奖励信号、或某个任务族的定向微调),这类数据更容易让全深度任务梯度扰动预训练能力。
第二,训练显存资源敏感,LoPT通过截断任务损失的全深度反向图,可以减少激活值存储和反向计算量。
第三,希望保留留出能力,尤其是指令遵循、常识推理、真实性、留出推理能力等。
第四,已经在使用LoRA / ZeRO / 梯度检查点 / 流水线并行,LoPT可以与这些系统栈叠加,无需推翻已有的训练流程。
总结
LoPT做了一件简单但重要的事:在大模型后训练时,任务梯度不一定非要一路传播到最底层。通过在Transformer中间点插入stop-gradient边界,LoPT将模型自然地拆分为两种角色:后半部分负责任务适配,前半部分负责表示保持。
最核心的结果可以概括为:在SFT上,Alpaca-52K → Llama-3.1-8B中GSM8K提升25.48个百分点、IFEval提升15.53个百分点、显存下降36%;在GRPO上,GSM8K → Qwen2.5-7B中GSM8K提升0.39个百分点、IFEval提升3.69个百分点、策略更新显存下降21%;在LoRA上,LoPT结合LoRA的SFT七项全胜,平均提升0.67个百分点、显存下降36%;在DeepSpeed-ZeRO3上,继续节省19%显存,并提升6%吞吐量。
参考文献
[1] Rethinking Local Learning: A Cheaper and Faster Recipe for LLM Post-Training

(本文参与腾讯云自媒体同步曝光计划,原始发表:2026-05-26。如有侵权请联系cloudcommunity@tencent.com 删除)




