在软件工程领域,有一个客观现实:初级程序员与高级工程师之间的本质差距,并不在于敲击键盘的速度,而在于应对复杂问题时展现出的分析与破解能力。
面对那些定义模糊、缺少现成答案的疑难杂症时:
- 新手往往陷入困境,不知从何下手,甚至可能沿着错误方向越走越偏;
- 而资深工程师则能系统性地拆解问题、定位根因、设计解决方案,并一步步推进直到问题彻底解决。
这种能力背后,核心是系统化思维——将一团乱麻转化为可有序执行的方案。今天这篇文章,我们将深入探讨复杂问题的拆解方法论、攻坚策略、定位技巧与实战案例,帮助你构建完整的能力体系。
一、复杂问题的本质特征
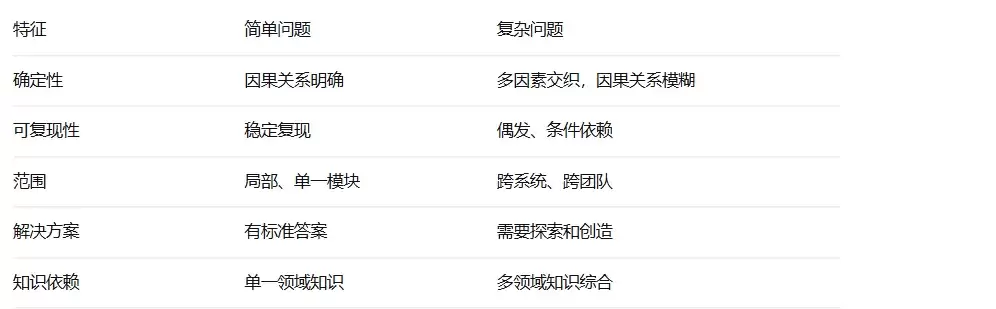
1.1 什么是复杂问题?
复杂问题与简单问题存在本质区别:
复杂问题常见的若干表现形式:
┌─────────────────────────────────────────────────────────────────┐ │ 复杂问题的典型表现 │ ├─────────────────────────────────────────────────────────────────┤ │ │ │ 1. 偶发性问题 │ │ "系统偶尔会出现超时,但无法稳定复现" │ │ │ │ 2. 跨系统问题 │ │ "订单状态不一致,但涉及订单、支付、库存三个系统" │ │ │ │ 3. 性能问题 │ │ "接口在高峰期响应时间从50ms飙升到5s" │ │ │ │ 4. 数据一致性问题 │ │ "数据库主从延迟导致用户看到旧数据" │ │ │ │ 5. 隐性依赖问题 │ │ "系统升级后另一个不相关的功能异常" │ │ │ └─────────────────────────────────────────────────────────────────┘
1.2 复杂问题解决的核心能力
要高效解决复杂问题,通常需要具备以下层次的能力:
┌─────────────────────────────────────────────────────────────────┐ │ 复杂问题解决能力模型 │ ├─────────────────────────────────────────────────────────────────┤ │ │ │ ┌─────────────────────────────────────────────────────────┐ │ │ │ 顶层:系统思维 │ │ │ │ 理解全局、识别模式、把握本质 │ │ │ └─────────────────────────────────────────────────────────┘ │ │ ▲ │ │ ┌─────────────────────────────────────────────────────────┐ │ │ │ 中层:方法体系 │ │ │ │ 问题拆解 │ 根因分析 │ 方案设计 │ 推进执行 │ │ │ └─────────────────────────────────────────────────────────┘ │ │ ▲ │ │ ┌─────────────────────────────────────────────────────────┐ │ │ │ 底层:基础技能 │ │ │ │ 逻辑推理 │ 数据验证 │ 工具使用 │ 沟通协作 │ │ │ └─────────────────────────────────────────────────────────┘ │ │ │ └─────────────────────────────────────────────────────────────────┘
二、问题拆解方法论
2.1 麦肯锡问题解决七步法
麦肯锡这套框架经过无数次验证,适用于各类复杂问题:
Step 1: 定义问题 └── 明确问题的边界和目标 Step 2: 拆解问题 └── 将大问题分解为可管理的小问题 Step 3: 提出假设 └── 基于已知信息提出可能的原因 Step 4: 制定计划 └── 设计验证假设的分析计划 Step 5: 收集分析 └── 收集数据,验证或推翻假设 Step 6: 得出结论 └── 综合发现,形成结论 Step 7: 沟通方案 └── 向相关方清晰地呈现解决方案
2.2 MECE原则:相互独立,完全穷尽
MECE(Mutually Exclusive, Collectively Exhaustive)是拆解问题时必须遵循的核心原则。举个例子,当系统响应变慢时:
class MECE原则示例:
"""
问题:系统响应慢
❌ 非MECE拆解:
- 数据库问题
- 网络问题
- 代码问题
- 其他问题("其他"不是相互独立的)
✅ MECE拆解:
按请求处理链路拆解:
- 客户端 -> 网关层
- 网关层 -> 应用层
- 应用层 -> 缓存层
- 缓存层 -> 数据库层
按问题类型拆解:
- CPU密集型问题
- IO密集型问题
- 锁竞争问题
- 内存问题
"""
def mece_decompose(problem_statement):
"""MECE拆解模板"""
# 维度1:按时间顺序拆解
timeline_dimensions = ["请求前", "请求中", "请求后"]
# 维度2:按系统组件拆解
component_dimensions = ["前端", "网关", "应用", "缓存", "数据库", "消息队列"]
# 维度3:按问题类型拆解
type_dimensions = ["功能缺陷", "性能瓶颈", "数据错误", "配置问题", "环境问题"]
# 选择最适合的维度进行拆解
return {
"dimension": "按请求处理链路",
"subproblems": [
"客户端请求延迟分析",
"网络传输延迟分析",
"网关处理延迟分析",
"应用业务处理延迟分析",
"数据库查询延迟分析",
"响应回传延迟分析"
]
}
2.3 逻辑树拆解法
逻辑树是一种直观的可视化拆解工具:
系统响应慢(根问题)
│
┌──────────────────┼──────────────────┐
│ │ │
客户端侧 服务端侧 网络侧
│ │ │
┌─────┴─────┐ ┌─────┴─────┐ ┌─────┴─────┐
│ │ │ │ │ │
DNS解析 资源加载 应用层 数据库 带宽延迟 TCP连接
渲染 逻辑慢 查询慢 丢包抖动
│ │
┌───┴───┐ ┌───┴───┐
算法 锁 索引 锁
复杂 竞争 失效 等待
class LogicTree:
"""逻辑树拆解器"""
def __init__(self, root_problem):
self.root = Node(root_problem)
def add_branch(self, parent, child_problem, relation="and"):
"""添加分支"""
pass
def analyze(self):
"""遍历逻辑树进行分析"""
pass
# 示例:响应慢问题的逻辑树
root = "API响应时间从50ms增加到5000ms"
# 第一层拆解(MECE)
branches = [
"请求处理耗时增加",
"等待时间增加",
"网络传输耗时增加"
]
# 第二层拆解:请求处理耗时增加
sub_branches_processing = [
"CPU使用率升高",
"GC频繁导致停顿",
"同步锁竞争",
"算法复杂度高"
]
# 第三层拆解:CPU使用率升高
sub_branches_cpu = [
"业务流量增长",
"死循环",
"正则表达式回溯",
"序列化/反序列化开销"
]
2.4 假设驱动法
面对复杂问题,先提出假设再逐步验证,通常效率更高:
class HypothesisDrivenProblemSolving:
"""假设驱动问题解决框架"""
def __init__(self):
self.hypotheses = []
self.validated = []
self.rejected = []
def generate_hypotheses(self, symptoms):
"""基于症状生成假设"""
hypotheses = []
# 按可能性排序的假设
hypothesis_templates = [
{
"priority": 1,
"template": "问题由{component}的{issue_type}引起",
"examples": [
"数据库连接池配置不当",
"缓存命中率下降",
"消息队列积压",
"第三方服务超时"
]
},
{
"priority": 2,
"template": "问题由{change_type}变更引入",
"examples": [
"代码部署",
"配置变更",
"依赖升级",
"流量突增"
]
},
{
"priority": 3,
"template": "问题由{resource}资源耗尽引起",
"examples": [
"CPU资源",
"内存资源",
"磁盘IO",
"网络带宽"
]
}
]
return hypotheses
def prioritize_hypotheses(self, hypotheses):
"""按影响概率和验证成本排序"""
return sorted(hypotheses,
key=lambda h: (h["probability"], -h["verification_cost"]),
reverse=True)
def design_validation(self, hypothesis):
"""设计验证方案"""
validation_methods = {
"数据库问题": "执行慢查询分析,检查数据库监控",
"缓存问题": "检查缓存命中率监控,测试缓存穿透",
"代码问题": "代码审查,添加日志,单元测试",
"配置问题": "对比配置变更历史,检查配置项",
"资源问题": "检查系统监控,分析资源使用趋势"
}
return validation_methods.get(hypothesis["type"], "添加详细日志进行验证")
2.5 5Whys根因分析法
5Whys通过连续追问“为什么”,层层深入直至找到根本原因:
class FiveWhys:
"""5Whys根因分析法"""
def __init__(self, problem):
self.problem = problem
self.analysis_chain = []
def analyze(self):
"""执行5Why分析"""
current = self.problem
for i in range(1, 6):
why_answer = self.ask_why(current, level=i)
self.analysis_chain.append({
"level": i,
"question": f"为什么 {current}?",
"answer": why_answer
})
# 检查是否到达根因
if self.is_root_cause(why_answer):
break
current = why_answer
return self.analysis_chain
def ask_why(self, statement, level):
"""追问为什么,实际使用中需要根据具体情况回答"""
# 示例逻辑
why_mapping = {
"API响应慢": "数据库查询耗时增加",
"数据库查询耗时增加": "订单表全表扫描",
"订单表全表扫描": "缺少合适的索引",
"缺少合适的索引": "索引设计时未考虑该查询",
"索引设计时未考虑该查询": "缺乏查询性能评审流程"
}
return why_mapping.get(statement, "需要进一步调查")
def is_root_cause(self, answer):
"""判断是否到达根因(可采取行动的原因)"""
root_cause_indicators = [
"缺乏流程",
"设计缺陷",
"监控缺失",
"培训不足",
"文档缺失"
]
return any(indicator in answer for indicator in root_cause_indicators)
# 使用示例
analyzer = FiveWhys("订单创建接口响应超时")
result = analyzer.analyze()
for step in result:
print(f"Level {step['level']}: {step['question']}")
print(f"Answer: {step['answer']}")
# 输出示例:
# Level 1: 为什么 订单创建接口响应超时?
# Answer: 数据库查询耗时增加
#
# Level 2: 为什么 数据库查询耗时增加?
# Answer: 订单表全表扫描
#
# Level 3: 为什么 订单表全表扫描?
# Answer: 缺少合适的索引
#
# Level 4: 为什么 缺少合适的索引?
# Answer: 索引设计时未考虑该查询
#
# Level 5: 为什么 索引设计时未考虑该查询?
# Answer: 缺乏查询性能评审流程 ← 根因
上述方法和工具并非互相孤立——实际排查问题时,往往需要综合运用。例如,先用逻辑树进行粗粒度拆解,再用假设驱动法锁定可疑方向,最后通过5Why深挖根因。将这些技巧有机结合,才能从容应对那些令人棘手的复杂工程难题。




