或许你难以相信,内容创作团队最常见的瓶颈,往往不是“人手不足”,而是“彼此之间对各自工作进展一无所知”。
试想一下,当你打开一份选题会的产出文档,发现十几个待办事项散落各处——有的正在撰写初稿,有的等待审核,有的在素材环节已经停滞数日——你很可能需要在聊天记录、在线文档、共享网盘以及一张过期的进度表之间反复切换,才能勉强拼凑出“当前究竟进展如何”。
这绝非工具不够用的问题,而是任务分配环节本身就隐藏着一个结构性缺陷。
一、为什么内容创作需要重新思考任务分配
内容创作的工作流具有独特特点:依赖链条较长(文案需要等待设计,设计需要等待反馈,反馈需要等待决策),状态变化迅速(一篇推文可能在两小时内从“撰写中”变为“已定稿”再变为“待重写”),信息密度较高(每项任务附带的素材、评论、版本记录远多于一般事务性工作)。
传统的任务分配方式——无论是聊天群内的指令、电子表格中的静态列表,还是简单的待办清单——都难以同时满足三个核心需求:让团队全员清晰掌握全局,让每位成员精准聚焦自身任务,让管理者快速识别瓶颈环节。
一个典型场景是:主编将五个选题分配给三位创作者,大家各自认领并独立推进。三天后复盘发现,其中两篇同时卡在了设计环节,而设计师事先毫不知情。问题的根源并非设计师效率低下,而是任务分配层面没有将“创作完成”与“设计等待”之间的依赖关系可视化出来。
二、基于卡片排布的内容创作任务分配逻辑
要解决这个问题,核心思路是:将任务从“线性列表”中解放出来,置于一个可自由排布的空间中。每张任务卡片代表一个创作单元——可能是一篇文章、一条视频脚本或一组海报——通过它们在二维空间内的位置关系,直观呈现任务的状态、归属和依赖关系。
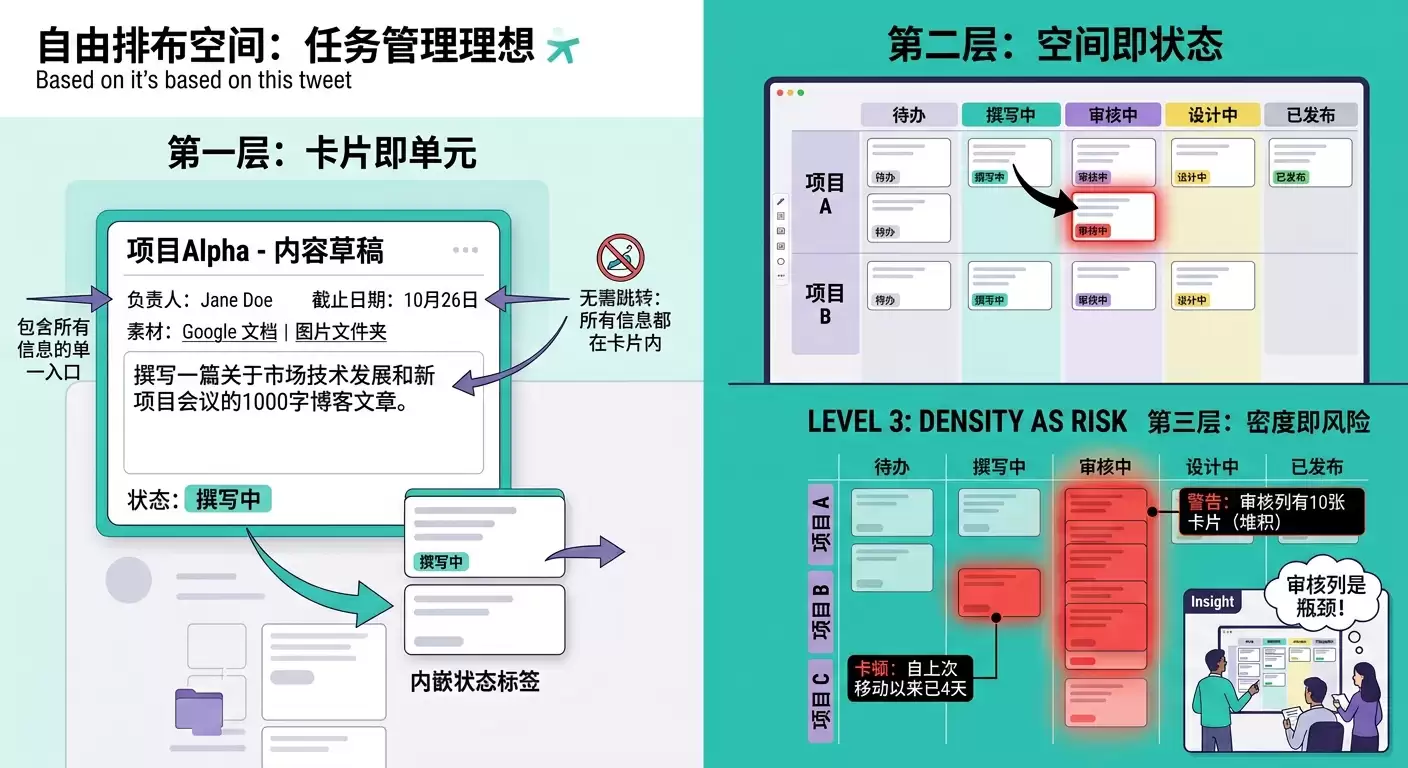
这套逻辑分为三层:
第一层,卡片即单元。每个创作任务被封装为一张独立卡片,卡片上承载的信息应足以让执行者无需跳转其他工具即可开展工作:包括标题、负责人、截止时间、依赖素材链接以及当前状态标签。卡片本身成为统一的信息入口。
第二层,空间即状态。卡片的排布位置直接映射任务状态。横向可划分出“待认领—撰写中—审核中—设计中—已发布”等阶段列,纵向可按项目、优先级或创作者分组。一张卡片从左侧拖动到右侧,即代表一次状态变更,无需任何额外操作。
第三层,密度即风险。当某个阶段列中卡片堆积过多,或某张卡片长时间停滞在相同位置,肉眼即可察觉。团队在晨会上仅需三秒钟就能发现“审核列积压了五篇”或“那篇初稿已停滞四天”等异常情况。
三、技术实现示例:卡片权重与排布建议
在具体实现中,系统需要为每张卡片计算一个“关注优先级”,以辅助在阵列中的位置排布。下面提供一个简化版的Ja vaScript实现:
四、工具选型的关键考量
在选择内容创作任务分配工具时,建议从以下几个维度进行评估:
空间自由度方面:卡片是否能在不同状态列之间自由拖拽?是否支持按项目、负责人、截止时间等多种维度快速重组视图?
信息密度控制方面:卡片上展示的字段是否可自定义?是否能在概览模式下只显示关键信息,点击后才查看全貌?
依赖关系表达方面:是否支持卡片间的关联(例如“等待A卡完成”),并能将这种依赖关系在阵列中可视化呈现?
轻量级自动化方面:是否具备简单的触发规则(例如“当所有子任务完成后,自动将父卡片移动到下一列”)?
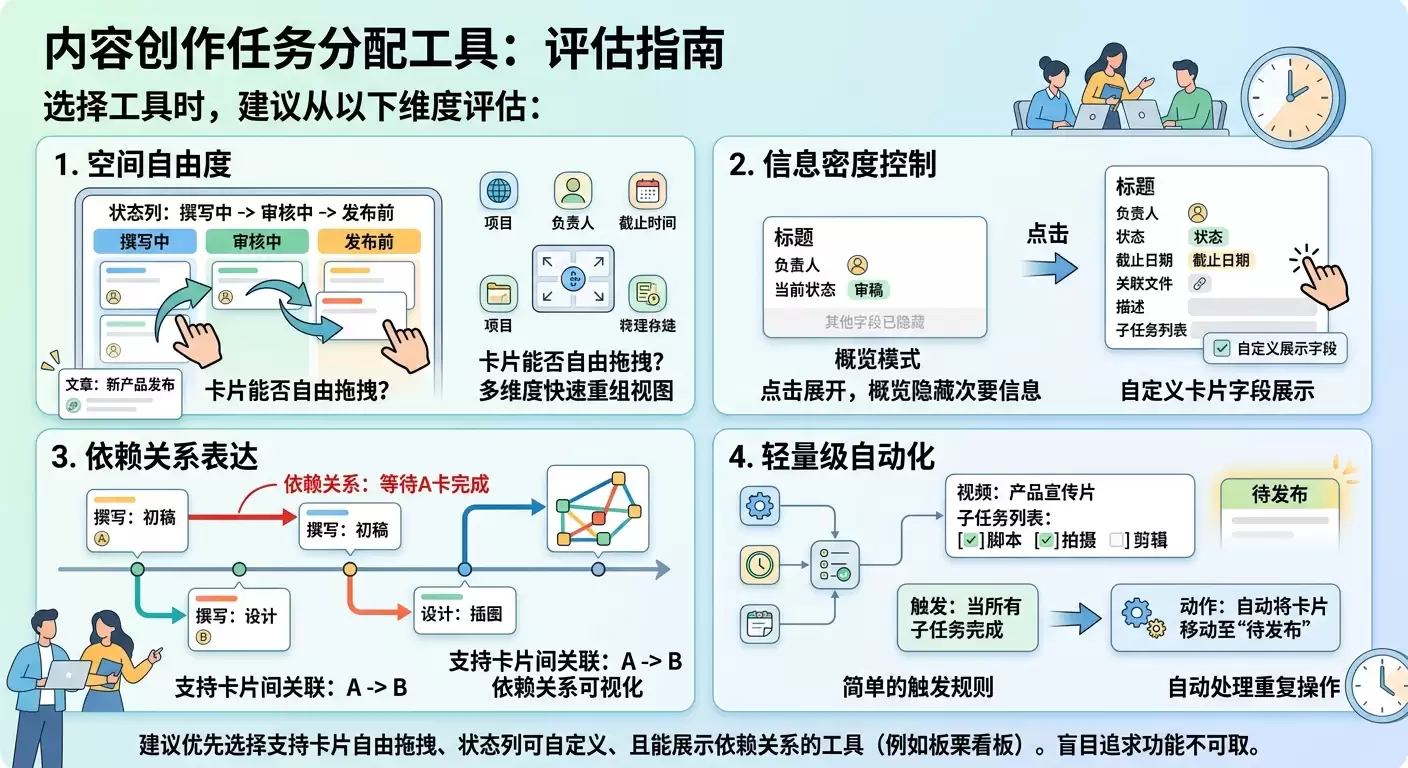
目前市面上许多主流工具在这些方面各有侧重。对于内容创作团队常见的“文案—设计—审核—发布”多角色流转场景,建议优先选择支持卡片自由拖拽、状态列可自定义、且能在卡片层面展示依赖关系的工具。具体选型还需考虑团队规模、预算和现有技术栈,不必追求功能最全的工具。
五、落地建议与风险控制
引入基于卡片排布的任务分配方式后,需留意三个常见问题:
首先,避免卡片泛滥。一个阵列中同时展示超过50张卡片会导致视觉拥挤。建议按周归档已完成卡片,或按项目分板管理。
其次,保持位置语义一致。团队内部需对“每一列代表什么状态”达成共识,避免A理解的“审核中”与B理解的“终审中”产生歧义。这一共识应在团队层面明确并可视化展示在板子顶部。
最后,定期清理僵尸卡片。超过两周没有任何进展的卡片应及时标记或移出主阵列,否则将持续消耗团队的注意力。
六、结语
内容创作的核心产出是创意与文字。但要确保创意稳定、高效地转化为交付成果,离不开一套清晰的任务分配与进度可视化体系。选择合适的内容创作任务分配工具,已不再是“用什么软件记一下”这种轻量级辅助决策,而是直接影响团队交付节奏的关键基础设施。当每个任务以卡片形式被清晰排布,每一处瓶颈都能在三秒内被发现时,创作团队才能真正将精力从“对齐进度”转向“做好内容”。




