每次和IT同行交流数据工作,大家最常抱怨的往往不是写SQL,也不是对接接口,而是需求一变表结构就乱,口径一多报表就对不上,系统一扩展,之前埋下的问题就全暴露出来。
比如同样是客户,销售、财务、运营的口径各不相同。领导追问营收为什么下降,不同系统里却能算出好几个版本。项目刚上线时还能靠人记,过几个月新人一接手,字段从哪来、指标怎么算、数据能不能复用,谁都说不清楚。
这些问题表面看是数据不准、开发低效、协作费劲,本质上其实是缺少一套完整的数据组织框架。数据建模就是这套框架。它不只是建几张表,而是把业务、数据、系统和规则真正串起来。
今天这篇文章就从概念、类型、方法、步骤几个方面,把数据建模一次讲透,帮你建立一套完整的认知体系。
一、数据建模的概念
数据建模,简单来说,就是把现实业务中的对象、关系、规则,转换成可存储、可计算、可分析的数据结构。
比如企业里有客户、订单、商品、合同、回款、门店、员工,这些都是业务对象。客户会下订单,订单会包含商品,合同会产生回款,员工会负责客户,这些就是对象之间的关系。不同客户类型享受不同价格,不同订单状态影响收入确认,这些就是业务规则。
数据建模要做的事,就是把这些内容整理清楚,并落实到数据表、字段、主键、外键、指标、维度、事实等设计中。
很多人以为数据建模只是数据库设计,其实不止。数据库设计更偏存储层,关注表怎么建、字段怎么放、性能怎么优化。数据建模范围更大,它关心的是数据如何表达业务、如何支撑分析、如何保证口径统一、如何支持后续扩展。
一个好的数据模型,至少要解决四件事:
让业务对象清晰:知道企业到底有哪些核心对象,每个对象代表什么,边界在哪里。
让数据关系清晰:知道对象之间如何关联,哪些是一对一,哪些是一对多,哪些是多对多。
让指标口径清晰:知道销售额、收入、利润、活跃用户、复购率这些指标到底怎么计算。
让数据流向清晰:知道数据从哪个系统来,经过哪些处理,最终被哪些报表、应用、算法使用。
所以,数据建模不是技术人员自嗨,而是数据工程的地基。地基稳了,后面的开发、分析、治理、决策才不会反复返工。
二、数据建模的类型
数据建模通常可以分成几个层次。不同层次解决的问题不同,面向的人群也不同。
1.概念模型
概念模型最接近业务语言,主要用来描述企业有哪些核心业务对象,以及这些对象之间有什么关系。
它不太关心数据库怎么建,也不纠结字段类型,而是先把业务讲清楚。比如客户、订单、商品、门店之间是什么关系,客户是否可以属于多个组织,订单是否一定对应合同。
概念模型通常用于需求沟通和业务梳理,适合业务人员、产品经理、数据分析师、数据架构师一起参与。
2.逻辑模型
逻辑模型比概念模型更细,开始关注实体、属性、关系、主键、业务规则。
比如客户实体有哪些属性,客户编号、客户名称、客户等级、所属区域、创建时间分别是什么含义。订单实体和客户实体通过哪个字段关联,订单状态有哪些取值,是否允许为空。
逻辑模型不一定绑定某一种数据库,但已经能指导开发设计。
3.物理模型
物理模型面向具体数据库落地,关注表结构、字段类型、索引、分区、存储格式、性能优化。
比如订单表按日期分区,客户编号用字符串还是整数,金额字段精度是多少,哪些字段需要索引,历史数据如何归档。
物理模型是开发最熟悉的部分,但如果前面的概念模型和逻辑模型没做好,物理模型很容易变成临时堆表。
4.分析模型
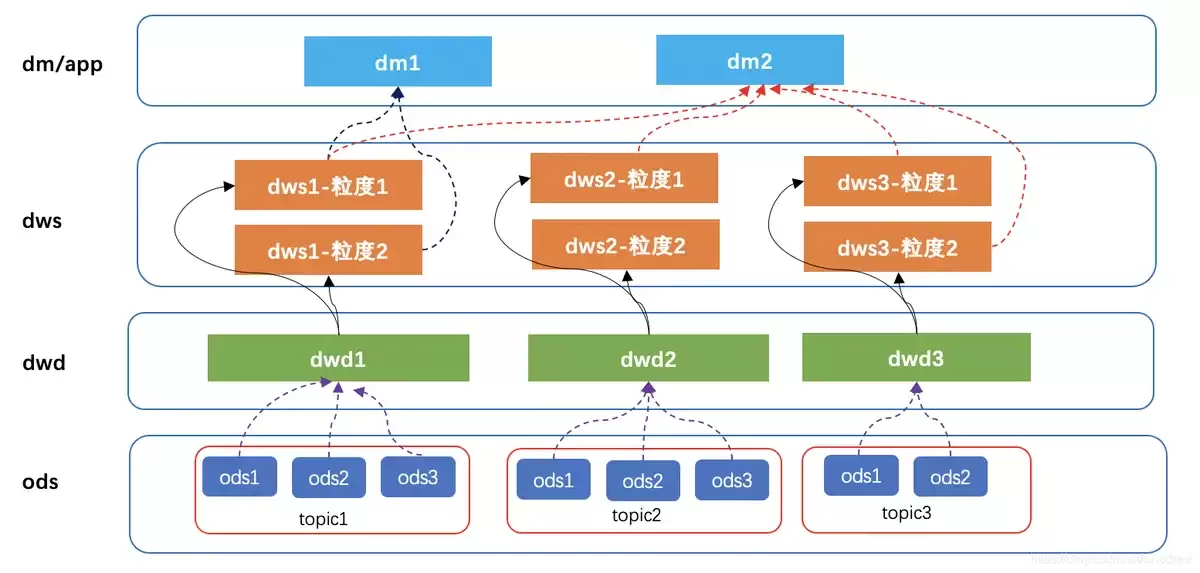
分析模型主要服务数据仓库、BI报表、经营分析和指标体系,常见形式包括维度模型、宽表模型、指标模型。
它关注的不是业务系统如何交易,而是分析场景如何高效取数。比如按时间、区域、产品、客户类型分析销售额,就需要设计时间维度、区域维度、产品维度、客户维度,以及销售事实表。
在企业数据链路里,业务系统、数仓、报表之间往往存在大量数据同步和转换。比如从CRM、ERP、OA、数据库、接口中抽取数据,再进入数仓分层建模。
三、数据建模的方法
数据建模没有唯一标准,但常见方法有几类。实际项目中往往不是单选,而是根据场景组合使用。
1.ER建模
ER建模关注实体、属性、关系,适合业务系统数据库设计。
实体就是业务对象,比如客户、订单、商品。属性就是对象的特征,比如客户名称、联系电话、客户等级。关系就是对象之间的联系,比如客户拥有订单,订单包含商品。
ER建模的优点是表达清晰,适合梳理业务系统。缺点是如果直接用于复杂分析,可能查询链路较长,报表开发效率不高。
适用场景包括交易系统、管理系统、主数据系统、基础业务库设计。
2.维度建模
维度建模常用于数据仓库和BI分析,核心是事实表和维度表。
事实表记录业务过程中的可度量事件,比如订单明细、支付流水、库存变动、用户访问。维度表描述分析角度,比如时间、地区、商品、客户、渠道。
维度建模最典型的价值是让分析更直接。业务要看不同区域的销售额、不同渠道的转化率、不同商品的毛利,就可以围绕事实表和维度表快速展开。
适用场景包括经营分析、管理驾驶舱、指标看板、专题分析。
3.范式建模
范式建模强调减少数据冗余,保证数据一致性。常见于关系型数据库设计。
比如客户信息只维护一份,订单表只保存客户编号,不重复保存客户名称、地址、等级等大量信息。这样客户信息变更时,只需要改客户表。
它的优点是结构严谨、冗余少、更新一致性好。缺点是查询分析时可能需要多表关联,复杂报表性能压力较大。
适用场景包括核心业务系统、强事务系统、数据一致性要求高的系统。
4.宽表建模
宽表建模是把分析常用字段整合到一张大表里,减少查询时的关联成本。
比如客户销售宽表中同时包含客户信息、订单信息、商品信息、区域信息、销售人员信息和关键指标。分析人员查询时不用理解复杂表关系,直接取字段即可。
优点是使用方便、查询效率高,适合面向分析和报表。缺点是冗余较多,维护成本较高,如果源字段变化,宽表也要跟着调整。
适用场景包括高频报表、固定分析主题、自助取数、数据服务接口。
5.Data Vault建模
Data Vault更适合复杂企业级数据仓库,强调可扩展、可追溯、适应变化。
它通常把数据拆成核心业务键、关系、属性变化三类结构,便于保留历史和追踪来源。
优点是扩展性强,适合多系统、多来源、长期演进的数据平台。缺点是学习和实施成本较高,对团队成熟度有要求。
适用场景包括大型企业数仓、数据中台、强审计要求的数据平台。
四、数据建模的步骤
真正做数据建模时,不建议一上来就建表。很多模型失败,不是技术不行,而是前期没想清楚。可以按下面步骤推进。
1.明确建模目标
先弄清楚这次建模服务什么场景。是支撑业务系统上线,还是做数据仓库,还是统一指标口径,还是建设管理看板。
目标不同,模型设计就不同。业务系统更关注事务完整性,数据仓库更关注分析效率,指标体系更关注口径一致,数据服务更关注接口稳定。
这个阶段要输出清晰的问题清单。比如本次模型要支撑哪些报表,涉及哪些业务流程,数据刷新频率要求多高,历史数据保留多久,权限边界是什么。
2.梳理业务对象和流程
接着要把业务对象和流程梳理出来。
可以从业务流程入手。比如销售流程包含线索、客户、商机、报价、合同、订单、回款、售后。每个环节都会产生数据,每个数据都要找到归属对象。
这个阶段不要急着讨论字段类型,而要先统一业务理解。客户和联系人是不是一回事,订单和合同是否一一对应,退款是否冲减销售额,赠品是否计入销量,这些问题必须先确认。
3.识别实体、属性和关系
业务对象明确后,就要转换为模型结构。实体通常对应表或主题对象。属性通常对应字段。关系决定表之间如何连接。
这里要重点关注主键和业务键。主键用于系统唯一识别记录,业务键用于表达业务上的唯一性。比如客户ID是主键,统一社会信用代码可能是业务键。订单ID是主键,订单编号可能是业务键。
如果主键设计混乱,后面数据关联、去重、追溯都会很痛苦。
4.设计指标和口径
如果模型用于分析,就必须设计指标口径。指标不是简单字段相加,而要明确统计范围、计算公式、时间口径、过滤条件、数据来源、更新频率。
比如销售额要不要包含退款,要不要含税,是否包含未审核订单,按下单时间算还是按支付时间算。活跃用户是登录算活跃,还是下单算活跃,还是访问关键页面算活跃。
指标口径最好沉淀成统一文档或指标平台,避免每个报表各算各的。
5.分层设计数据模型
在数据仓库场景里,通常会做分层设计。源数据层保留原始数据,尽量少加工,方便追溯。明细层清洗标准字段,统一编码、时间、状态、主键。汇总层按主题沉淀可复用数据,比如客户主题、订单主题、商品主题。应用层面向具体报表、看板、接口、算法场景。
分层的价值是降低耦合。源系统变化时,不至于所有报表都跟着改。新需求出现时,也可以优先复用已有主题模型。
6.落地开发与数据集成
模型设计完成后,下一步就是把设计真正变成可运行的数据链路。这一步看起来像开发执行,实际上很考验建模质量。因为模型一旦进入落地阶段,问题就不只是表怎么建,还包括数据从哪里来、怎么清洗、怎么汇总、怎么稳定输出。
这一环节通常要处理这几类问题:
多源数据接入、数据清洗与标准化、转换与分层加工、调度与依赖管理。
所以从本质上说,落地开发与数据集成,不只是把数据搬过来,而是把模型规则持续、稳定地执行出来。在实际项目里,这一步最容易从设计问题变成维护问题。前期数据源少、链路短,手写脚本也能完成。但一旦数据来源增多、加工层次变深、调度关系变复杂,后续维护成本就会明显上升。
7.校验数据质量
模型上线前一定要做数据校验。校验内容包括记录数是否一致,金额是否平衡,主键是否重复,关联是否缺失,枚举值是否异常,指标是否和历史报表对齐。
不要只测几条样例数据。数据模型的问题往往出现在边界场景,比如退款、作废、补录、跨月、拆单、合单、历史迁移。
8.持续维护和迭代
数据建模不是一次性工作。业务会变化,组织会调整,系统会上新,指标会新增,模型也要持续迭代。
但迭代不等于随便改。每次修改都要评估影响范围,记录变更原因,保留必要历史,通知下游使用方。否则模型会越改越乱,最后没人敢动。
五、总结
数据建模的核心,是把业务世界转换成清晰、稳定、可复用的数据结构。
对IT工程师来说,数据建模不是额外负担,而是减少返工的关键手段。没有模型,数据工作只能靠经验和临时处理。
建议大家处理数据工作时,不要一上来就写SQL、建宽表、堆脚本。先问清楚业务对象是什么,关系是什么,指标口径是什么,数据从哪来到哪去。再根据场景选择合适的建模方法,并配合稳定的数据集成、调度和治理机制。




