2026-05-28:今天来聊一道有趣的树上算法题。给定一棵无向树(n 个节点,n-1 条边)和三个互不相同的目标节点 x、y、z,需要统计树上所有“特殊节点”的数量——所谓特殊节点,就是指它到 x、y、z 的三个距离,从小到大排序后满足勾股定理 a² + b² = c²。题目来自力扣 3820,数据规模 n 最大 10 万,采用线性时间算法即可高效求解。
树上勾股距离节点解题步骤详解
第一步:构建无向树的邻接表存储结构
树是由节点和边构成的无环连通图。要高效处理它,首先需要将输入的边信息转换为计算机能快速遍历的邻接表存储结构。
- 已知共有 n 个节点(编号 0 到 n-1),先创建一个长度为 n 的列表,每个位置对应一个节点,用于存储它的所有邻居。
- 遍历输入的 n-1 条边,每一条边连接两个节点 v 和 w:将 w 添加到 v 的邻居列表中,同时将 v 添加到 w 的邻居列表中——因为树是无向的,边是双向的。
- 构建完成后,后续所有距离计算均基于该邻接表进行。
第二步:实现「单源最短距离计算」功能
树的独特性质使得距离计算变得简单——任意两点之间仅有一条唯一路径,因此从起点出发,通过一次深度优先搜索(DFS)即可计算出所有节点的距离。
- 创建一个长度为 n 的距离数组,初始值全为 0(下标对应节点编号,值对应距离)。
- 从起点开始进行深度优先遍历(DFS),规则非常清晰:
- 记录当前节点及其父节点(防止回溯);
- 遍历当前节点的所有邻居,跳过父节点;
- 邻居节点的距离 = 当前节点距离 + 1;
- 递归继续遍历该邻居节点。
- 遍历结束后,距离数组存储了起点到每个节点的最短距离。
第三步:分别计算三个目标节点到全节点的距离
题目给出了三个固定节点 x、y、z,需要分别以它们为起点,调用第二步的函数,得到三组距离数据:
- 以 x 为起点,得到数组 dx:dx[i] 表示节点 i 到 x 的距离;
- 以 y 为起点,得到 dy;
- 以 z 为起点,得到 dz。
这样每个节点都对应三个距离值,便于后续判断。
第四步:遍历所有节点,判断是否为「特殊节点」
逐一检查树上的每个节点 i(从 0 到 n-1),判断规则严格遵循题目要求:
- 取出节点 i 的三个距离:dx[i]、dy[i]、dz[i];
- 对这三个数从小到大排序,得到 a、b、c(a ≤ b ≤ c);
- 验证勾股定理:a² + b² 是否等于 c²;
- 若成立则计数加 1,否则跳过。
第五步:返回最终统计结果
遍历完所有节点后,统计得到的数量即为答案。
时间复杂度分析
拆解每一步的复杂度(n 为节点总数):
- 构建邻接表:遍历 n-1 条边,时间复杂度为 O(n);
- 三次距离计算:每次 DFS 访问所有节点和边,单次 O(n),三次总计 O(3n) = O(n);
- 节点判断与计数:遍历 n 个节点,每个节点进行常数时间的排序(3 个数排序为 O(1))和公式验证,总耗时 O(n)。
总时间复杂度:O(n)(线性时间,应对 10 万级别数据毫无压力)
空间复杂度分析
评估额外占用的空间:
- 邻接表:存储 n 个节点和 n-1 条边,空间为 O(n);
- 距离数组:三个长度为 n 的数组,空间为 O(3n) = O(n);
- DFS 递归栈:最坏情况树呈链状,深度为 n,栈空间 O(n);
- 其他变量(计数、临时数组)均为常数空间 O(1)。
总空间复杂度:O(n),内存友好。
总结
- 核心流程:建邻接表 → 三次 DFS 计算距离 → 遍历节点验证勾股定理 → 统计结果;
- 时间复杂度:O(n)(线性时间,高效处理十万级节点);
- 空间复杂度:O(n)(线性空间,满足题目内存要求)。
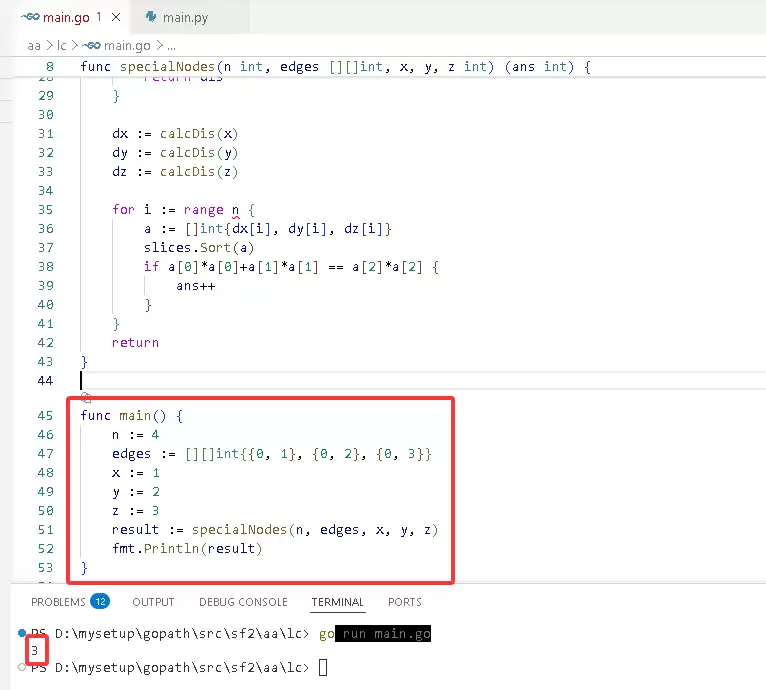
Go 完整代码如下:
package main
import (
"fmt"
"slices"
)
func specialNodes(n int, edges [][]int, x, y, z int) (ans int) {
g := make([][]int, n)
for _, e := range edges {
v, w := e[0], e[1]
g[v] = append(g[v], w)
g[w] = append(g[w], v)
}
calcDis := func(start int) []int {
dis := make([]int, n)
var dfs func(int, int)
dfs = func(v, fa int) {
for _, w := range g[v] {
if w != fa {
dis[w] = dis[v] + 1
dfs(w, v)
}
}
}
dfs(start, -1)
return dis
}
dx := calcDis(x)
dy := calcDis(y)
dz := calcDis(z)
for i := range n {
a := []int{dx[i], dy[i], dz[i]}
slices.Sort(a)
if a[0]*a[0]+a[1]*a[1] == a[2]*a[2] {
ans++
}
}
return
}
func main() {
n := 4
edges := [][]int{{0, 1}, {0, 2}, {0, 3}}
x := 1
y := 2
z := 3
result := specialNodes(n, edges, x, y, z)
fmt.Println(result)
}
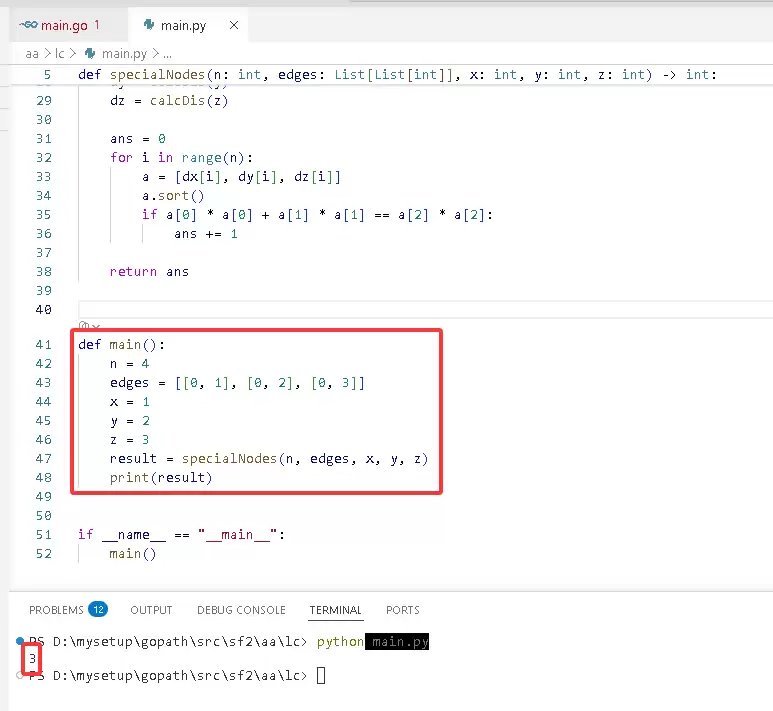
Python 完整代码如下:
# -*-coding:utf-8-*-
from typing import List
def specialNodes(n: int, edges: List[List[int]], x: int, y: int, z: int) -> int:
# 构建邻接表
g = [[] for _ in range(n)]
for v, w in edges:
g[v].append(w)
g[w].append(v)
# 计算从 start 出发到所有节点的距离
def calcDis(start: int) -> List[int]:
dis = [0] * n
visited = [False] * n
def dfs(v: int):
visited[v] = True
for w in g[v]:
if not visited[w]:
dis[w] = dis[v] + 1
dfs(w)
dfs(start)
return dis
dx = calcDis(x)
dy = calcDis(y)
dz = calcDis(z)
ans = 0
for i in range(n):
a = [dx[i], dy[i], dz[i]]
a.sort()
if a[0] * a[0] + a[1] * a[1] == a[2] * a[2]:
ans += 1
return ans
def main():
n = 4
edges = [[0, 1], [0, 2], [0, 3]]
x = 1
y = 2
z = 3
result = specialNodes(n, edges, x, y, z)
print(result)
if __name__ == "__main__":
main()
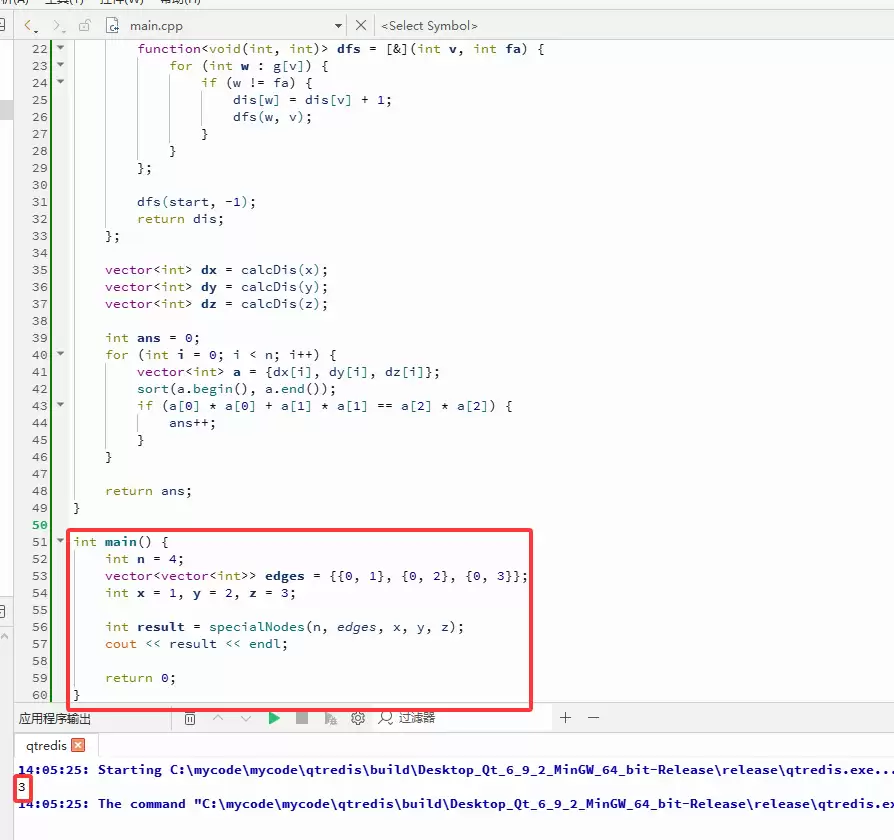
C++ 完整代码如下:
#include
#include
#include
#include
using namespace std;
int specialNodes(int n, vector>& edges, int x, int y, int z) {
// 构建邻接表
vector> g(n);
for (auto& e : edges) {
int v = e[0], w = e[1];
g[v].push_back(w);
g[w].push_back(v);
}
// 计算从 start 出发到所有节点的距离
auto calcDis = [&](int start) -> vector {
vector dis(n, 0);
// DFS 函数声明
function dfs = [&](int v, int fa) {
for (int w : g[v]) {
if (w != fa) {
dis[w] = dis[v] + 1;
dfs(w, v);
}
}
};
dfs(start, -1);
return dis;
};
vector dx = calcDis(x);
vector dy = calcDis(y);
vector dz = calcDis(z);
int ans = 0;
for (int i = 0; i < n; i++) {
vector a = {dx[i], dy[i], dz[i]};
sort(a.begin(), a.end());
if (a[0] * a[0] + a[1] * a[1] == a[2] * a[2]) {
ans++;
}
}
return ans;
}
int main() {
int n = 4;
vector> edges = {{0, 1}, {0, 2}, {0, 3}};
int x = 1, y = 2, z = 3;
int result = specialNodes(n, edges, x, y, z);
cout << result << endl;
return 0;
}