引言
先说一个核心判断:当数据量从百万级跃迁到亿级,传统物化视图依赖"全量重算"的刷新机制,在准实时分析场景中已经逐渐显露疲态,难以满足高效响应的需求。
此前,我们在《告别临场加工,揭秘PolarDB物化视图如何将查询性能提升百倍》一文中,已系统介绍了云原生数据库PolarDB MySQL版全量物化视图的核心优势——通过预计算并持久化查询结果,结合计算卸载至IMCI列存节点与行列混存架构,实现复杂分析查询的百倍加速。自该功能发布以来,已在众多客户的HTAP场景中得到广泛应用。
但问题也随之显现:当表数据量达到数亿行,而每次变更仅涉及少量记录时,全量刷新“重算整个视图”的代价过高——刷新耗时长、数据新鲜度差,难以满足准实时分析对时效性的要求。
为此,PolarDB MySQL版正式推出增量物化视图(Incremental Materialized View):其核心思路十分简洁——仅处理自上次刷新以来的变更数据。在TPC-H 100G基准测试中,相比全量刷新,实现了数倍至数十倍的性能提升(4表混合JOIN加速32倍、单表聚合加速近11倍)。
增量物化视图的核心价值
极致效率:秒级增量,开销降低90%
仅处理基表(即物化视图所依赖的原始业务表)自上次刷新以来的INSERT/UPDATE/DELETE变更,刷新开销降低90%以上,4表JOIN场景从74秒缩短至2.3秒;支持最短1秒的自动刷新间隔,让数据始终保持“秒级新鲜”。
业务零干扰:基于Redo日志,无需触发器
基于Redo日志在IMCI列存节点回放时自动捕获变更,无需依赖触发器或Binlog解析,不在业务表附加任何额外开销,刷新期间也不锁定基表,在线事务完全不受影响。
运维零负担:增量表全生命周期自动管理
系统根据视图定义自动推导并创建列存增量表,随基表自动创建与回收,全生命周期对用户透明,无需DBA手动维护日志表。
弹性可扩展:存算分离,按需弹升
基于存算分离架构,IMCI计算节点无状态,增量数据存储于共享存储;增量刷新可在多节点间负载均衡,支持秒级弹升与横向扩展。
典型应用场景
场景一:电商实时订单看板
以实际场景为例。某电商平台订单表每秒新增数千条记录,运营团队需要实时查看按用户、品类、区域汇总的统计数据。增量物化视图将每秒新增和变更的订单“叠加”到已有结果上,无需重扫数亿条历史订单——参考Q1的10.8倍加速效果,原本数秒的全量刷新压缩至亚秒级,看板始终展示最新数据。
场景二:供应链多表关联报表
某制造企业供应链系统涉及供应商、订单、物料、区域等多张核心业务表,管理层每天需多次查看跨表关联报表。增量物化视图将多表预关联为一张“宽表”,仅用变更行去关联其他表,避免了多表全量重算——参考Q10的31.8倍加速效果,原本一分多钟的刷新压缩至2秒,报表更新频率从每小时提升至每分钟。
场景三:数据分层的准实时ETL
在数据仓库分层架构(ODS → DWS → ADS)中,逐层计算是常规操作。通过嵌套增量物化视图构建轻量级ETL流水线,每一层仅处理上游传递的增量变化,计算成本大幅降低。结合最短1秒的刷新间隔,完全可以在数据库内部搭建一套准实时的数据加工流水线,减少对外部ETL工具的依赖。
技术亮点
架构上,增量物化视图沿用了“计算卸载到IMCI列存节点”的设计思路,并围绕“增量”打通了一条对业务完全透明的端到端链路。
首先,变更捕获基于数据库内核的Redo日志流,在IMCI节点回放日志的同时实时识别基表变更,无需触发器、无需Binlog解析,同步延迟控制在毫秒级。
其次,系统根据视图定义自动推导并隐式创建列存增量表,基于全局事务位点自动回收过期数据,全生命周期对DBA透明、免运维。
然后,过滤、聚合、JOIN等增量算子全部下沉至列存节点以SIMD向量化执行,并根据查询模式自动选择最优增量策略——聚合直接“叠加”、JOIN仅用变更行关联——彻底避免全表重算。
最后,刷新阶段由PDML让IMCI与RW节点以Pipeline协同,Insert/Update/Delete多线程并发回写,写入吞吐随并发度线性扩展。四项能力相互配合,共同支撑了“秒级新鲜、业务零感知”的刷新体验。
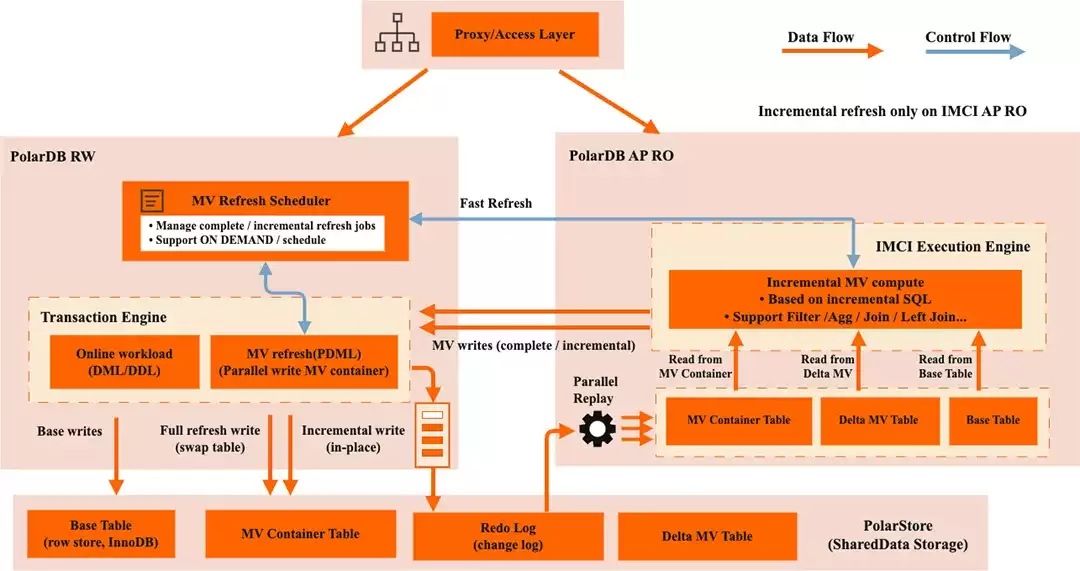
图:增量物化视图整体架构图
支持场景与能力矩阵
目前,PolarDB增量物化视图已覆盖多种主流分析类应用场景,且正在持续扩展中:

性能实测:TPC-H 100G基准测试
测试基于PolarDB MySQL 8.0.2(32核CPU / 256GB内存)和TPC-H 100G数据集(lineitem表约6亿行),覆盖单表聚合、多表JOIN、LEFT JOIN等典型场景。每场景每轮约1000行变更,取5轮平均值。
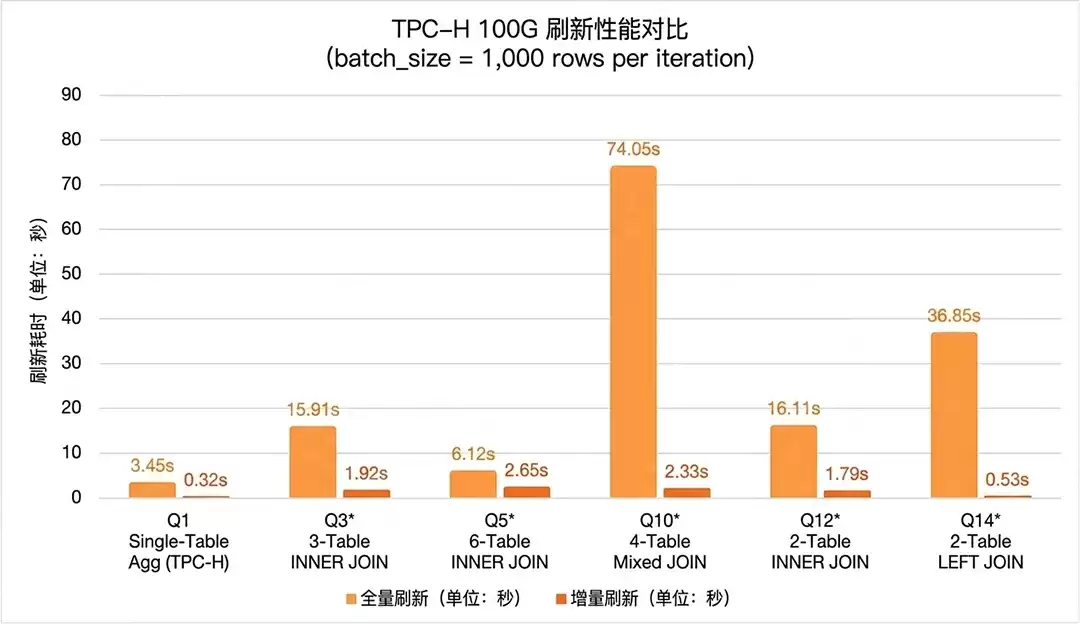
*注:Q1为原生TPC-H SQL;其余带*号的查询基于TPC-H原始SQL,针对增量刷新当前支持的算子场景做了适配改造(如去除子查询、CTE、ORDER BY/LIMIT等暂不支持的语法),保留核心的表关联与过滤逻辑。
核心结论十分明确:全量刷新耗时由基表总数据量决定,而增量刷新仅与变更行数相关——数据量越大、变更比例越小,增量刷新的优势就越突出。最具代表性的4表混合JOIN场景(Q10)下,全量需扫描并关联4张大表耗时74秒,增量仅处理1000行变更耗时2.3秒,加速31.8倍;原生TPC-H Q1单表聚合场景中,6亿行lineitem分组聚合从3.45秒降至0.32秒。即便在最复杂的6表INNER JOIN(Q5)场景,增量仍保持2.3倍以上的提速,且在不同变更粒度(100~10000行)下耗时仅略有上升,稳定性显著优于全量。
选型建议
全量刷新和增量刷新并非替代关系,而是互补的两种策略,可在同一系统中协同使用:
▶︎ 选择增量刷新:基表数据量大且变更频繁(每次变更仅占总数据的小比例)、对数据新鲜度要求高(分钟级甚至秒级)、查询逻辑在增量支持范围内(过滤、聚合、JOIN、LEFT JOIN等)。
▶︎ 选择全量刷新:查询逻辑包含窗口函数、HAVING、ORDER BY等增量暂不支持的语法、数据变更不频繁(每天刷新一次即可)、或需要从零重建视图数据时。
未来展望
在已支持的能力基础上,我们将持续扩展多表聚合(JOIN GROUP BY)、UNION ALL、MIN/MAX等更广泛的SQL算子和能力;同时即将推出ON COMMIT实时刷新与透明查询改写功能,使物化视图从“秒级按需刷新”演进到“事务级实时同步”,并由优化器自动匹配视图加速业务查询,进一步降低使用门槛。
增量物化视图是PolarDB从“查询加速”迈向“数据保鲜”的关键一步:基于Redo日志的智能增量维护机制,让物化视图成为与业务数据同步跳动的“活”数据源。




