沙箱的本质:不是隔离墙,而是"透明窗口"——让LLM能够"看到"运行时状态,让调试过程对LLM可理解,让NLP能力在全生命周期持续可用。
一、Why:为什么沙箱是不可或缺的高级属性
1.1 AI 代码生成的根本困境
说到AI生成代码,一个被广泛忽视的现状是:这些代码其实从未真正运行过。它们就像一堆写好的计划书,但从来没人验证过这些计划在现实中是否走得通。这一下就把问题推到了桌面上——代码生成得再漂亮,如果跑不起来,一切都是空谈。
| 缺陷类型 | 表现 | 传统方案的局限 |
|---|---|---|
| 上下文缺失 | 生成的代码依赖不存在的类/方法 | 静态分析无法覆盖运行时依赖 |
| 环境假设错误 | 假设的数据源/服务在目标环境不存在 | 单元测试无法验证环境集成 |
| 状态耦合遗漏 | 忽略组件间的运行时状态依赖 | 代码审查难以发现隐式耦合 |
这里要划个重点:沙箱的真正价值,是让AI生成的代码在首次运行就直接面对真实业务环境,而不是躲在开发者的本地机器里当"乖宝宝"。
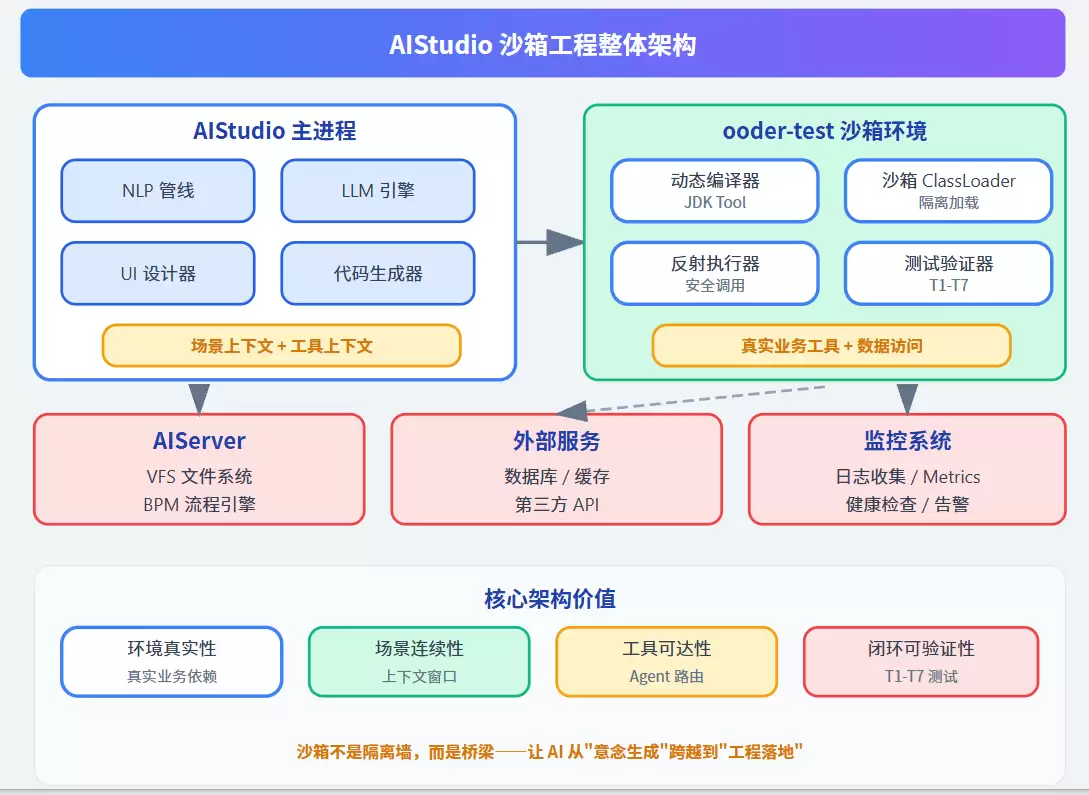
二、What:沙箱工程的本质
2.1 不是容器,是真实环境的镜像
沙箱的核心设计原则其实特别简单,但也很容易被误解:它必须与生产环境同构。注意,不是近似,不是模拟,而是同构。
ooder:cluster:registration:role: TEST_AGENTcapabilities: closed-loop-test,sandbox-compile,deploy-targettest:aiserver-url: ${AISERVER_URL:https://127.0.0.1:9004/aiserver}studio-url: ${STUDIO_URL:https://127.0.0.1:8099}
几个关键设计决策值得单独拿出来说:
- 沙箱注册为
TEST_AGENT,与aiserver(ROUTE_AGENT)和studio(END_AGENT)平级 - 沙箱能够访问 aiserver 的 VFS 文件系统和 studio 的 NLP 服务
- 沙箱不是"受限环境",而是"完整环境的测试实例"
简单来说,沙箱不是在代码周围砌墙,而是给它一个和线上几乎一模一样的练武场。
三、How:完整闭环的技术实现
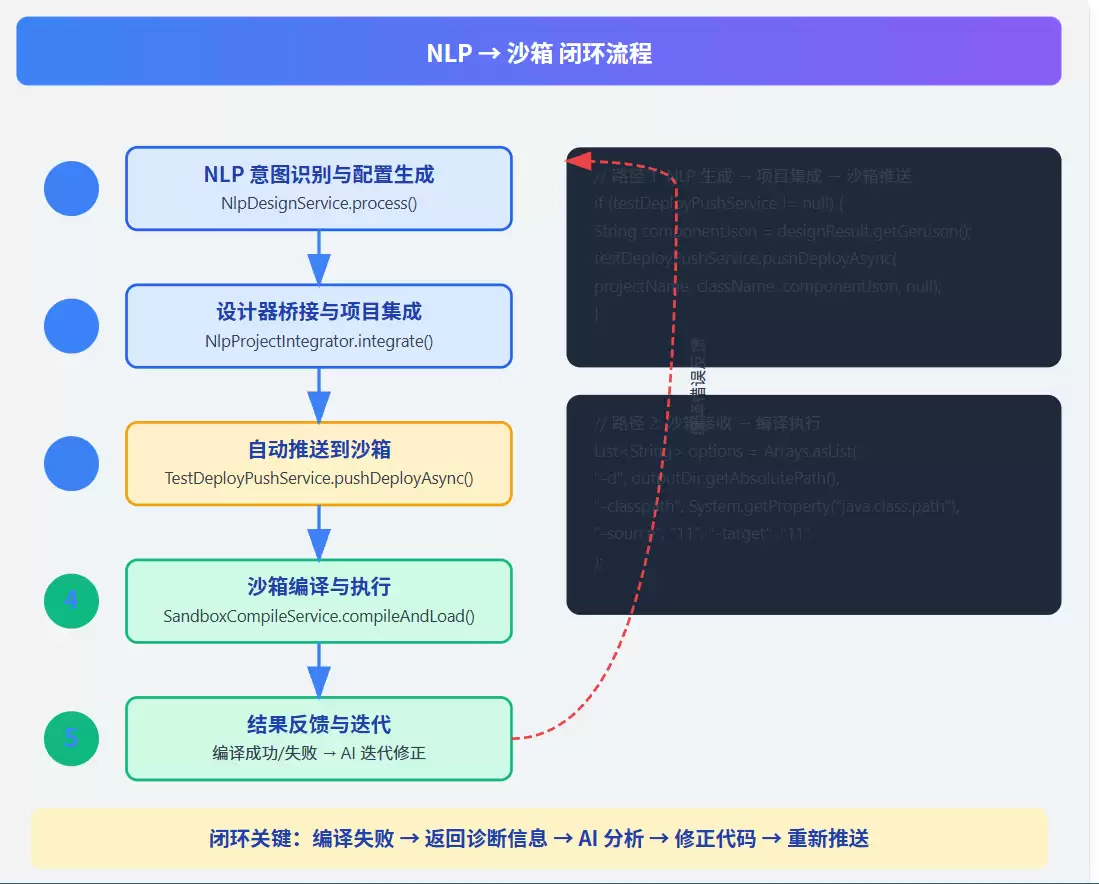
3.1 关键代码路径
路径 1:NLP 生成 → 项目集成 → 沙箱推送
// 保存模块后,自动推送到沙箱if (testDeployPushService != null) {try {String componentJson = designResult.getGenJson();testDeployPushService.pushDeployAsync(projectName, className, componentJson, null);} catch (Exception e) {log.debug("推送到ooder-test失败(非阻塞): {}", e.getMessage());}}
路径 2:沙箱接收 → 编译执行
public Map
这里有个关键洞察:-classpath 直接使用系统 classpath,也就是说沙箱编译的代码能够访问真实的业务依赖——数据库驱动、外部服务 SDK、业务领域模型等。这可不是开玩笑的,这意味着AI生成的代码从一开始就能接触到真实世界的基础设施。
四、场景管理能力:AI 的"记忆系统"
4.1 场景上下文窗口
沙箱的价值不仅在于编译执行,更在于它承载了场景上下文。
public class SceneConversationManager {// 场景上下文窗口:维护当前场景的完整状态private final Map
| 状态字段 | 作用 | 示例 |
|---|---|---|
| currentIntent | 当前意图 | BUILD_COMPONENT / MODIFY / QUERY |
| currentComponentType | 当前组件类型 | FORM / TABLE / CHART |
| currentModuleName | 当前模块名 | view.UserManagement |
| currentFields | 当前字段映射 | [{name:"userName", type:"INPUT"}] |
这就像给AI装上一个工作台,上面铺满了它之前做过的所有活儿、用过的所有工具,而不是每次都从空白的记事本开始重新摸索。
五、工具上下文:让 AI 接触真实业务环境
5.1 工具执行上下文
public class ToolContext {private String sessionId;// 会话标识private String userId; // 用户标识private Map
关键设计:ToolContext 是有状态的,它允许 AI 在多次交互中积累业务上下文。你可以把它看作是AI的"工作日志"和"工具箱"二合一。
六、远程调试:弥合开发-测试鸿沟
| 调试场景 | 传统模式 | 沙箱模式 |
|---|---|---|
| 编译错误 | 本地查看日志 → 推测原因 | 沙箱返回完整诊断信息 → AI 直接分析 |
| 运行时异常 | 人工复现 → 断点调试 | 沙箱捕获异常 → AI 分析堆栈 → 自动修正 |
| 集成问题 | 多环境切换 → 手动排查 | 沙箱内闭环验证 → 即时反馈 |
这相当于把"写完代码扔给测试"的传统流程,变成了"边写边测、写测一体"的即时反馈环路。AI不再是"甩手掌柜",而是"全程盯梢"。
七、为什么不用容器沙箱:JVM 级隔离的优势

7.1 对比分析
| 维度 | JVM 级沙箱 (ooder-test) | 容器沙箱 (Docker in Docker) |
|---|---|---|
| 启动延迟 | 50ms (ms级) | 2-10s (秒级) |
| 类加载隔离 | 精确到类级别 | 容器级粗粒度 |
| 资源占用 | 极低 (MB级) | 高 (GB级) |
| 场景上下文 | 原生支持,零拷贝 | 需序列化传递 |
| OS 隔离 | 弱 (依赖 JVM 安全策略) | 强 (内核级) |
从这张表可以看得很清楚:容器沙箱虽然提供了更强的OS隔离,但在我们关注的场景上下文、启动延迟、资源占用这些维度上,JVM级沙箱的优势几乎是碾压级的。
八、资源隔离与安全策略
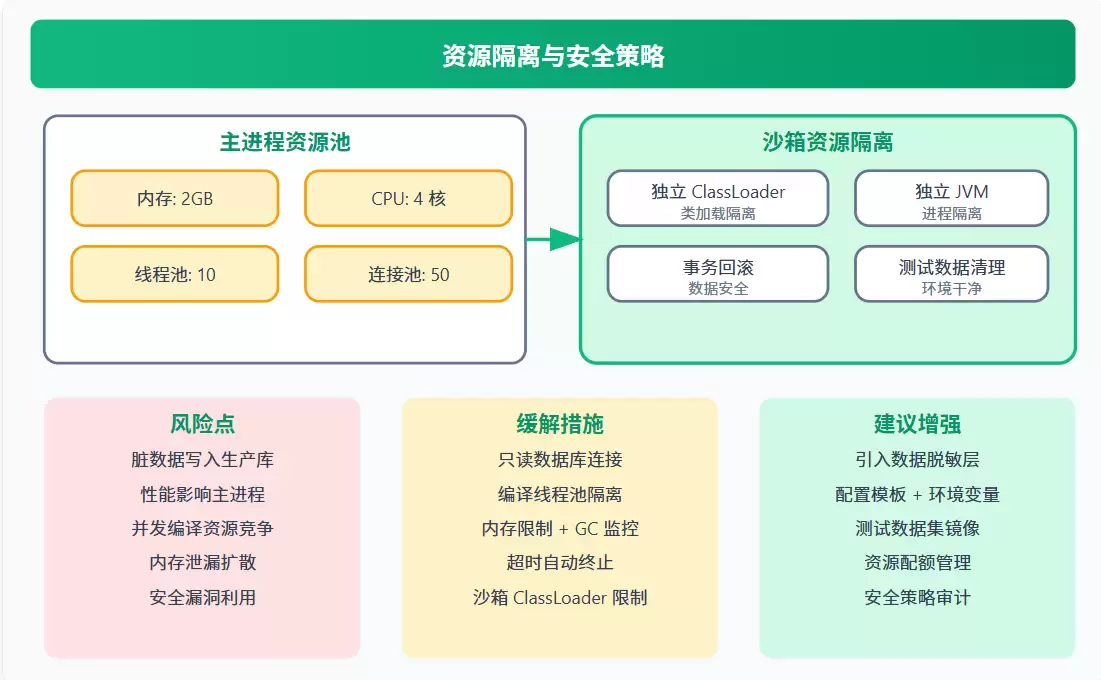
8.1 风险识别
| 风险点 | 影响 | 缓解措施 |
|---|---|---|
| 脏数据写入生产库 | 数据污染 | 只读数据库连接 事务回滚 |
| 性能影响主进程 | 主进程卡顿 | 编译线程池隔离 资源限制 |
| 并发编译资源竞争 | 编译失败 | 单线程执行器 队列管理 |
| 内存泄漏扩散 | 主进程 OOM | 独立 JVM GC 监控 |
实话实说,任何沙箱方案都不可能完全消除风险,但对于这些最典型的风险点,上面的缓解措施组合还是比较成熟的套路。
九、环境一致性保障
9.1 配置同步策略
沙箱强调"与生产同构",但配置同步才是真正的硬骨头。
推荐方案:
- 配置模板化:将数据库连接串、服务发现地址等抽象为模板
- 环境变量注入:通过
${ENV_VAR}方式注入,避免硬编码 - 测试数据集镜像:维护与生产结构一致但数据脱敏的测试数据集
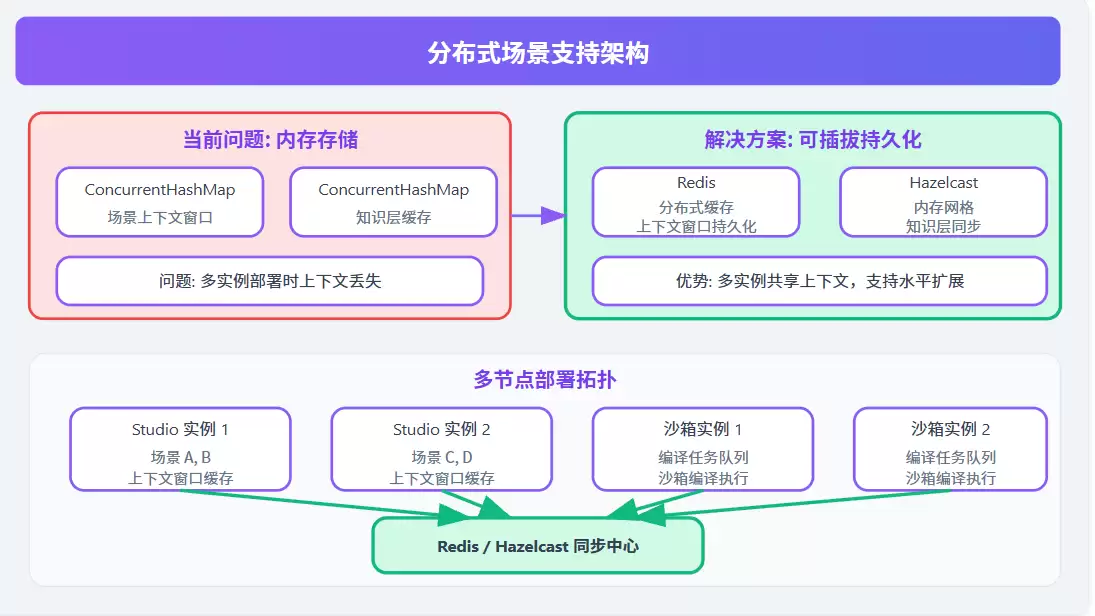
九、分布式场景支持
9.1 当前限制
SceneContextWindow 存储在内存中的 ConcurrentHashMap,多实例部署时会丢失上下文。这算是一个已知的短板,不是不能解决,但暂时还不够优雅。
9.2 架构原则:会话亲和优先,分布式缓存兜底
| 方案 | 优势 | 适用场景 |
|---|---|---|
| 会话亲和 | 简单、无外部依赖 | 单实例部署、开发环境 |
| Redis | 高性能、分布式 | 多实例部署、高并发 |
| Hazelcast | 内存网格、低延迟 | 需要强一致性的场景 |
注意:如果不打算实现分布式上下文共享,那就必须定义 SceneContextWindow 的序列化格式,这是跨实例传递一致性的最低要求。
9.3 反模式:上下文丢失导致对话断裂
触发条件:多实例部署时,用户请求被路由到不同实例
后果:场景上下文丢失,对话无法继续
预防措施:优先使用会话亲和,兜底使用分布式缓存,定义上下文序列化契约
十、失败处理与可观测性
10.1 基础设施层面
| 失败场景 | 恢复策略 | 监控指标 |
|---|---|---|
| 推送失败 (网络异常) | 重试队列 (3次) | 推送成功率 |
| 编译超时 (>30s) | 熔断器 超时终止 | 编译耗时 P99 |
| 沙箱宕机 (OOM) | 健康检查 自动重启 | 沙箱可用性 |
10.2 AI 行为可解释性
而且说实话,当前的可观测性方案有个明显的缺口——只盯着基础设施指标,对AI行为本身的关注几乎为零。
| 指标 | 作用 | 代码位置 |
|---|---|---|
| LLM 降级触发率 | 衡量模板生成的质量 | LlmCompileContext.totalLlmFallback |
| 编译重试次数 | 衡量 LLM 生成代码的质量 | LlmCompileContext.totalCompileRetries |
| 失败原因分类 | 区分环境缺失 vs 代码错误 | DiagnoseSkill.doCollect() |
| 诊断信息有效性 | 衡量诊断信息对 LLM 的帮助 | CompileLoopWithLlmFallback.executeCompileLoop() |
10.3 反模式:LLM 降级死循环
触发条件:编译持续失败,LLM 降级重试次数用尽
后果:资源浪费,用户等待时间过长
预防措施:设置最大重试次数(当前为 3 次),引入熔断器防止故障扩散,监控 LLM 降级触发率及时发现质量问题
十一、架构价值总结
11.1 核心架构价值
| 价值维度 | 具体体现 | 架构意义 |
|---|---|---|
| 环境真实性 | 访问真实数据库、文件系统、外部服务 | AI 生成的代码在首次运行就面对真实约束 |
| 场景连续性 | 场景上下文窗口 知识注入 | AI 在调试过程中保持对业务语义的理解 |
| 工具可达性 | ToolContext Agent 路由 | AI 能够自主选择和使用业务工具 |
| 闭环可验证性 | T1-T7 测试维度 | 从生成到验证的完整质量保障 |
| 调试可达性 | 远程调试 诊断信息返回 | AI 能够分析和修复运行时问题 |
一句话总结:oodproject 沙箱工程的本质是——为 AI 提供一个与生产环境同构的"真实业务接口",让 AI 生成的代码从"意念交付"升级为"工程交付",在场景上下文和工具可达性的支撑下,实现从生成到调试到验证的完整闭环。




