使用 Elasticsearch 和 GitHub Copilot SDK 构建 RAG 智能体
智能体构建器(Agent Builder)现已正式发布(GA)。若想快速上手体验,可从 Elastic Cloud 的试用版本开始,官方文档也已在 Agent Builder 页面同步更新。
长话短说,几个关键判断:仅需大约五行 C# 代码,即可将 Elasticsearch 与 GitHub Copilot SDK 无缝对接,让你的 RAG 智能体从真实数据中检索信息,而非依赖模型“凭空捏造”。Copilot 负责任务规划与流程编排,Elasticsearch 则负责检索你的日志、文档及专有记录。坦白说,搭建完成后的效果非常直观:智能体不会再因训练数据陈旧而产生幻觉,所有答案均基于你系统中的实际内容。接下来,我们将通过 Elastic.Extensions.AI 桥接库,完整拆解整个配置流程。
为什么 RAG 智能体缺少检索层就会产生幻觉
试想一下,如果没有检索层,AI 智能体只能依靠训练数据生成响应。这意味着,一旦涉及你的日志、文档或专有系统,它立刻就会开始“编造答案”。GitHub Copilot SDK 提供了经过生产环境验证的编排引擎;而 Elasticsearch 则为你的日志、文档及操作数据提供快速、精准的检索能力。两者一旦集成,智能体就不再需要“猜测”了。
接下来,我们将重点探讨如何通过 Elastic.Extensions.AI 桥接库建立这种连接,并提供一个完整的 .NET 代码示例,帮助你亲手创建一个可运行的 RAG 智能体——它利用 Copilot 的引擎进行规划,从 Elasticsearch 中完成检索。
核心技术栈概览:GitHub Copilot SDK 与 Elastic AI 生态系统
简而言之,GitHub Copilot SDK 负责编排与规划;Elasticsearch 负责检索与上下文提供。下面我们来看每个组件的具体分工。
GitHub Copilot SDK
GitHub Copilot SDK 是一个多平台工具集,目前仍处于技术预览阶段。它支持 Python、TypeScript、Go、.NET 和 Java。从架构上看,该 SDK 通过 JSON-RPC 与 Copilot CLI 服务器通信,并自动管理进程生命周期。简单来说,它承担了智能体行为核心工作:规划复杂任务、调用工具、管理模型交互。
Elastic AI 生态系统
在技术栈的另一端,Elastic 提供了两个主要的 AI 组件:
- Elastic AI Assistant:一款专为可观测性与安全性打造的工具,可帮助你构建查询、排查故障、进行威胁调查。
- Elastic Agent Builder:一个用于创建基于 Elasticsearch 数据的自定义智能体框架。它采用可视化聊天界面,底层技能与工具由 ES|QL 驱动。
功能划分十分清晰:在此集成方案中,GitHub Copilot 充当编排器(负责规划与决策的“大脑”),而 Elasticsearch 则是上下文提供者(存储你的日志、文档和专有数据的“记忆库”与“图书馆”)。
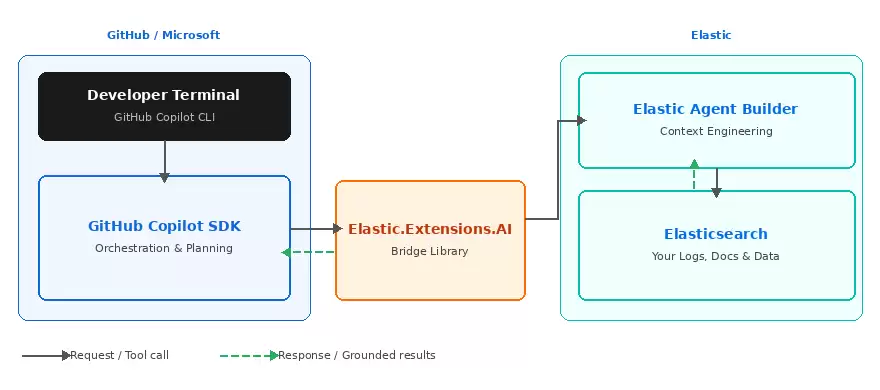
图 1:GitHub Copilot SDK 与 Elastic 组件之间的交互方式。
Elasticsearch 与 Copilot 集成的架构模式
将 Elasticsearch 与 GitHub Copilot SDK 桥接起来,主要有三种方式。下表可帮助你快速对比:
用例 |
关键协议/库 |
开发者收益 |
|---|---|---|
RAG / 混合搜索 |
Microsoft.Extensions.AI / Elastic.Extensions.AI |
以“五行代码”的简洁性,让智能体基于私有文档、日志和工单进行接地。 |
集群管理操作 |
Elasticsearch 管理 API / SDK 工具 |
通过自然语言控制集群健康状况和重新索引。(注意:ILM 复杂度较高。) |
智能体互操作性 |
Model Context Protocol (MCP) / Agent2Agent (A2A) Protocol |
无需编写新工具函数,即可原生调用预构建的 Elastic 智能体。 |
架构细节:实际操作中的现实情况
将 Elasticsearch 管理 API 作为 Copilot 工具暴露出来,确实能减少 SRE 的上下文切换。但开发者需要区分简单操作与复杂操作。像检查集群健康状况或触发重新索引这类基本任务,做起来非常直接。而通过自然语言管理 ILM 策略则困难得多——策略逻辑本身的复杂性决定了这一点。一个务实的建议是:高级架构师应先聚焦于健康和发现类工具,等积累足够经验后再去尝试完整的策略自动化。
分步指南:构建一个由 Elasticsearch 驱动的 Copilot 智能体
步骤 1:先决条件与环境设置
- GitHub Copilot 订阅:必须(除非使用 BYOK)。
- Copilot CLI:已安装且在 PATH 中可访问。
- Elasticsearch 集群:一个活跃的实例(Elasticsearch Serverless 或 Elastic Cloud)。
步骤 2:安装 SDK
该 SDK 支持 Python、TypeScript、Go、.NET 和 Java(开发中)。本文示例使用 .NET,因为 Elastic.Extensions.AI 桥接库提供了最紧密的集成。要安装 .NET 包,执行以下命令:
dotnet add package GitHub.Copilot.SDK
dotnet add package Elastic.Clients.Elasticsearch
dotnet add package Elastic.Extensions.AI步骤 3:将 Elasticsearch 注册为原生工具
整个集成通过 Elastic.Extensions.AI 桥接库运行,该库由 Elastic 前 .NET 客户端维护者 Martijn Laarman 编写,用于连接 Elastic Agent Builder 和 GitHub Copilot SDK。其核心模式包含四个步骤,大约 20 行 C# 代码,可归结为五个逻辑操作:
// 1. 初始化 Elasticsearch 客户端
var client = new ElasticsearchClient(
new Uri(Environment.GetEnvironmentVariable("ES_URL")!),
new ApiKey(Environment.GetEnvironmentVariable("ES_API_KEY")!));
// 2. 将搜索方法装饰为 Copilot 工具
[Description("Search Elasticsearch for documents relevant to the query")]
async Task SearchAsync(
[Description("Natural-language search query")] string query)
{
// 3. 定义 schema:让 LLM 通过 SearchAsync 驱动查询 DSL
var response = await client.SearchAsync(s => s
.Index("your-index")
.Query(q => q
.Match(m => m
.Field("content")
.Query(query))));
return JsonSerializer.Serialize(response.Documents.Take(5));
}
// 4. 通过 Elastic.Extensions.AI 桥接库注册工具并运行
var agent = CopilotAgent.Create(new CopilotAgentOptions());
agent.AddTool(AIFunctionFactory.Create(SearchAsync));
await agent.StartAsync(); 步骤 4:实施安全防护与隐私保护
Copilot SDK 内置了安全模型:用户必须确认工具的使用(除非使用了 --allow-all-tools 标志)。
关于数据隐私,需要明确一点:Elastic 不会将客户数据(包括提示、查询或事件数据)用于模型训练。对于需要零配置 AI 的团队,可通过 Elastic Inference Service (EIS) 使用 Elastic 管理的 LLM,这提供了对生成式功能的即时访问。不过要注意,这些服务会根据 Elastic Cloud 定价产生额外费用。如果你使用 EIS,数据将由你选择的第三方 LLM 提供商处理。
入门:使用 GitHub Copilot SDK 构建你的 Elasticsearch RAG 智能体
利用你自己的数据进行“接地”(Grounding),是解决幻觉问题的根本手段。通过 Elastic.Extensions.AI 桥接库将 Elasticsearch 与 GitHub Copilot SDK 连接起来,你就能以最少的样板代码让智能体访问到真实数据。Copilot 负责规划与编排;Elasticsearch 负责快速、准确的检索。最终成果是一个基于你系统中实际内容进行推理的智能体,而不是依赖几个月前的训练数据应付了事。
后续步骤:设置你的 Elasticsearch RAG 智能体
- 探索源代码:查看
elastic-ingest-dotnet仓库,获取Elastic.Extensions.AI桥接库。 - 查阅手册:参考 GitHub Copilot SDK Cookbook,那里提供了多语言示例。
- 实施提醒:从简单的工具开始,比如集群健康检查(Cluster Health)。ILM 管理要复杂得多,在智能体工作流中务必谨慎处理。
技术提示:GitHub Copilot SDK 目前仍处于技术预览阶段。在正式发布之前,可能会有一些潜在的变更。
附加资源:如果你想了解更多如何将 Elasticsearch 与 Microsoft Agent Framework 结合使用的内容,也可以在这篇博客中找到更详细的说明。
常见问题
对 AI 智能体而言,“接地”意味着什么?
“接地”(Grounding)指的是智能体在生成响应之前,会从像 Elasticsearch 这样的来源检索真实数据,而不是仅依赖 LLM 的训练数据。这能有效防止幻觉,并确保答案反映你的实际环境——即基于你的日志、文档和专有记录。
Elastic 是否使用我的查询或数据来训练 AI 模型?
不会。Elastic 不会使用客户数据(包括提示、查询或事件数据)来训练模型。如果你采用 BYOK(自带密钥),数据会保留在你自己的环境中。如果你使用第三方 LLM 提供商,其数据政策需要单独确认。
MCP 互操作性如何与 Elastic Agent Builder 协同工作?
Elastic Agent Builder 智能体会暴露一个 MCP 服务器端点,GitHub Copilot SDK 可以直接连接上去。这意味着现有的 Elastic 智能体可以从 Copilot 原生调用,无需重写工具函数。
我可以使用 GitHub Copilot 来管理 Elasticsearch 集群操作吗?
基本操作,比如检查集群健康状况或触发重新索引,作为 Copilot 工具运行得很好。但复杂操作,例如 ILM 策略管理,通过自然语言自动化较难安全实现,在智能体工作流中要谨慎对待。
GitHub Copilot SDK 支持哪些语言进行 Elasticsearch 集成?
截至撰写本文时,该 SDK 支持 Python、TypeScript、Go 和 .NET,Java 正在开发中。对于 Elasticsearch 集成,Python 和 .NET 提供了最直接的路径。由于这两种语言都与 Microsoft Agent Framework 深度集成,开发者可以使用现有的桥接库(如 Elastic.Extensions.AI)无缝连接 Copilot 与 Elasticsearch。




