今天是2024年12月4日,星期三,北京,天气晴。说起来,距离ChatGPT发布整整两年了。两年间,大模型从一个实验室里的新鲜词,变成如今几乎无处不在的基础设施。借着这个时间节点,我们今天来做个回顾,顺便梳理一下基于大模型来做Text2SQL的技术方案索引。当然,核心还是四个字:多思、多练。
一、ChatGPT两周年历程回顾
ChatGPT的诞生并非一蹴而就,而是一段清晰的技术演进史。时间倒回到2018年,OpenAI发布了最早一代大型模型GPT-1;次年,GPT-2问世,参数量一举跃升至15亿;而到了2020年,GPT-3带着1750亿个参数横空出世,训练规模是前代的10倍以上。

关键的转折发生在2022年。1月,OpenAI在GPT-3基础上用监督式训练进行微调,最终发布了InstructGPT。而同年11月30日,ChatGPT正式发布——它其实是InstructGPT的姐妹模型,本质上是对GPT-3的对话式升级,算下来是3.5版本。从那天起,全世界开始用ChatGPT聊天、写代码、做方案。
2023年3月15日,GPT-4问世,支持多模态。再到2024年,节奏明显加快:5月14日推出旗舰模型GPT-4o,9月13日又发布o1系列——包括预览版o1-preview以及后续的o1和o1-mini。短短两年,从单纯对话到复杂推理,AI的进化速度远超大多数人的预期。
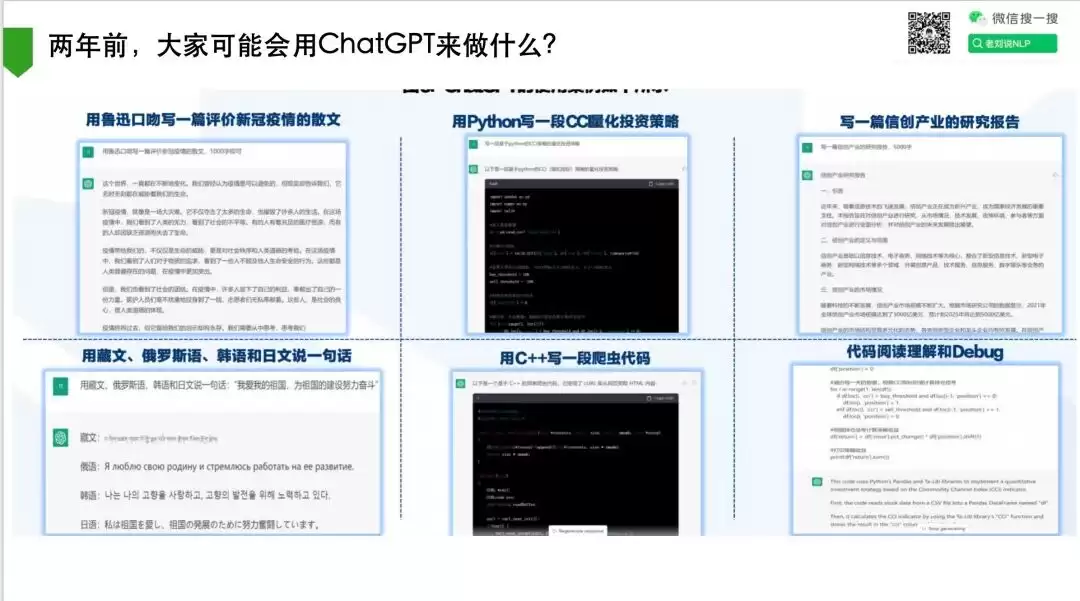
两年后的今天,我们已经很难想象一个没有AI辅助的工作场景。以AIGC为驱动的各类工具层出不穷,渗透到写作、编程、数据分析等几乎所有环节。
二、大模型Text2SQL方案索引
接下来聊第二个问题:基于大模型做Text2SQL,典型的方案长什么样?先看流程。
这里引用Spider数据集中的一个例子:用户提问“哪些卡通片是Joseph Kuhr编写的?”。LLM拿到问题和对应的数据库schema作为输入,输出一条标准的SQL查询。这条查询再交给数据库执行,最终返回“蝙蝠侠系列”作为答案。整个过程看起来很接近自然语言交互的理想形态。
对于这个方向,最近一篇综述《Next-Generation Database Interfaces: A Survey of LLM-based Text-to-SQL》做了非常系统的梳理。它先介绍了文本到SQL任务的背景和固有挑战,然后回溯了从传统方法到深度学习,再到预训练模型和LLM的演进过程。文章还对评估数据集、指标以及最新进展做了详细分析。
具体的技术全景,可以看下面这些图:
首先是Text2SQL的整体技术演变进展:
其次是基于LLM的Text-to-SQL技术方案层级分类树:
然后是Text-to-SQL的流行数据集:
以及基于ICL示例学习的方案代表工作:
最后是基于SFT微调的方案代表工作:
技术路线的选择,说到底还是看场景和资源。有了这些索引,后续无论是调研还是实际落地,都可以按图索骥,找到适合自己的那条路。