在文档解析领域,市面上虽然已经涌现出不少工具,但能同时兼顾识别精度、处理效率和数据安全的解决方案并不多见。今天我们要介绍的这款PDF Extract API,或许就是一个值得关注的选项——它基于Python与自然语言处理技术,专为PDF及图像中的文本提取与解析而设计。那么,它究竟凭借什么表现出众?
核心功能
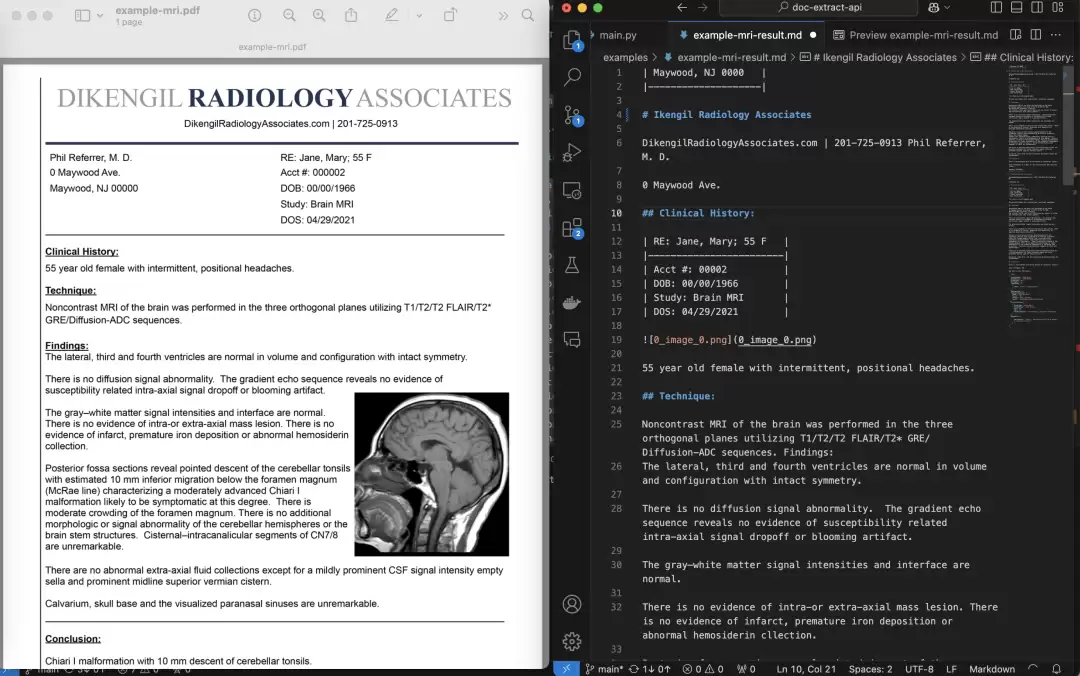
1、高精度文档提取
谈及文本提取,最令人担心的莫过于识别错误,尤其是面对排版复杂、内容繁杂的资料时。PDF Extract API采用了先进的OCR(光学字符识别)技术,能够精准地将PDF或图像中的文字信息“读取”出来。更值得关注的是,即便文档中夹杂着复杂的表格、数字甚至数学公式,它也能条理清晰地进行梳理,确保信息在转化过程中几乎不丢失、不出错。
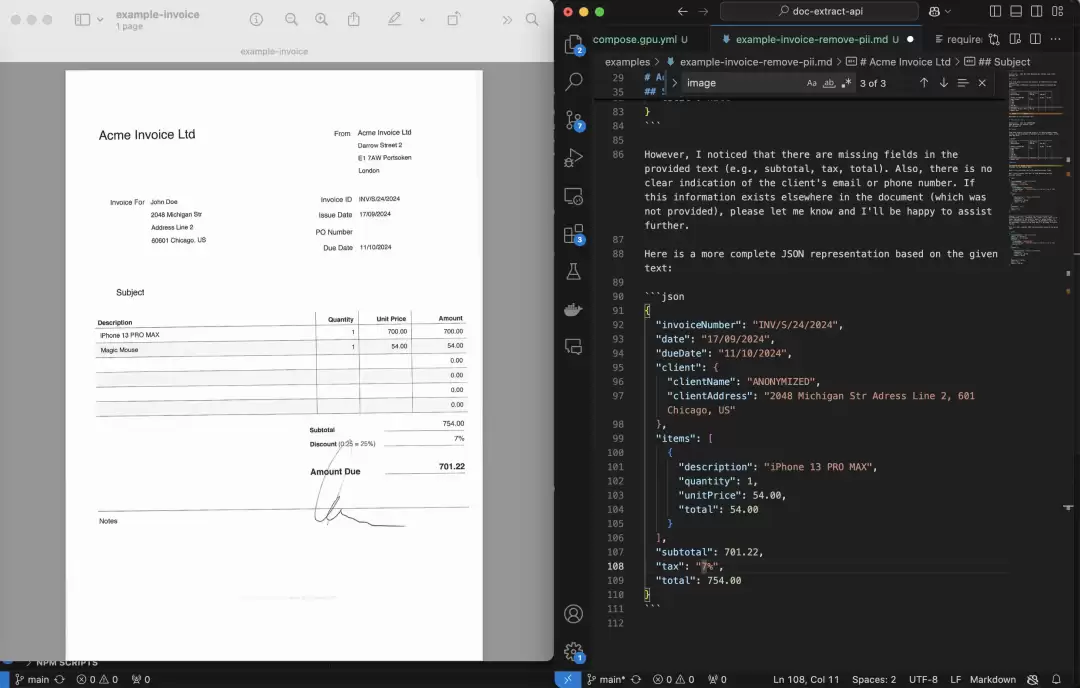
2、个人识别信息(PII)匿名化
隐私保护如今已受到广泛重视。该API内置了一项隐藏技能——自动移除文档中的个人识别信息(PII)。也就是说,当你需要处理敏感数据时,比如合同、病历、身份证照片等,它可以自动擦除涉及隐私的部分,全程无需人工干预。这样一来,既能放心地分享文件,也更易于满足各类隐私合规要求。
3、结构化输出
提取出的内容以何种形式呈现同样至关重要。PDF Extract API支持直接将内容转换为JSON或Markdown格式。前者适合后续的数据分析与系统集成,后者则更适用于生成网页或快速排版的文档。简单来说,它两头兼顾——既能供机器读取,也能供人直接查看。
4、高效的后台处理
在技术架构上,该API以FastAPI为基础构建,后台集成了Celery用于异步任务调度。这意味着,即使面对大量请求的突增,系统也能从容应对——排队、执行、返回一气呵成。再加上Redis对OCR结果进行缓存,进一步提升了响应速度:无需漫长等待,就能快速获得理想的结果。
结语
PDF Extract API是一套使用起来相当“顺手”的文档提取与解析方案。从精准的OCR识别、智能的PII匿名化,到双格式的结构化输出以及强大的后台处理能力,每一个环节都围绕着一个目标:让文档管理更高效、更安全。可以说,它不仅仅是一个工具,更像是一位能够帮你打理“文档杂事”的得力助手。