深度学习激活函数详解:从Sigmoid到ReLU及其变体演进
在深度学习中,激活函数是一个绕不开的核心问题。很多初学者习惯直接背诵公式,但要真正理解“为什么需要激活函数”,往往需要从“线性变换的局限性”这个起点入手。
一、神经网络与线性变换的局限性
典型的神经网络由输入层、隐藏层和输出层构成。每一层的基本操作,实质上是一个加权求和——也就是线性变换:
y = wx + b那么,如果把多个线性层堆叠起来,会发生什么?
我们来算一笔账。假设两个线性层叠加:
y = w₂(w₁x + b₁) + b₂ = (w₂w₁)x + (w₂b₁ + b₂)结果发现,绕了一大圈,最终仍然是一个线性函数。没错,这意味着无论网络层数多深,其表达能力都被限制在拟合线性数据的范围内。面对曲线边界、螺旋分布等非线性模式,它完全无能为力。
二、激活函数的核心作用
如何打破这个困局?方法是在每一层线性变换之后,引入一个非线性映射。这,正是激活函数的关键价值。
通俗地说:原本线性层输出一个 y,现在用一个非线性函数 f 对它进行“加工”——f(y) 才是真正的输出。这一操作,让神经网络从“直线思维”进化为“曲线思维”,从而能够学习并表达复杂的数据模式。
三、常见激活函数及其特性
3.1 Sigmoid 激活函数
公式:
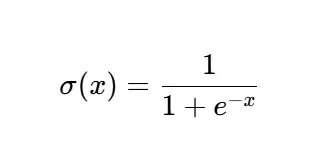
特性:输出范围在 (0,1) 之间,平滑且单调递增。其导数也很容易计算:σ′(x)=σ(x)(1−σ(x))。
优势:输出范围有限,数值稳定,不易溢出。更重要的是,输出值介于 0 到 1 之间,天然适合作为二分类任务的输出层——可以直接理解为概率,直观易懂。
缺点:但它的明显短板是梯度消失问题。Sigmoid 的导数最大值仅为 0.25,这意味着在深层网络反向传播时,梯度经过多层 Sigmoid 会迅速衰减,最终几乎为零。结果就是前面的网络层几乎无法学习,训练陷入停滞。
3.2 ReLU ⚡——深度学习的标配
公式:
ReLU(x) = max(0, x)特性:输入为正时输出本身,为负时输出 0,简单直接。
优势:首先,当 x>0 时导数为 1,梯度可以无损反向传播,极大支持深层网络的训练。其次,没有复杂的指数运算,计算效率极高,训练速度显著提升。再者,输入为负时输出 0,恰好模拟了人脑神经元的稀疏激活模式——通常只有 1% 到 4% 的神经元同时激活。这种特性减少了特征冗余,帮助网络聚焦于关键特征。
缺点:但 ReLU 也有一个令人头疼的问题——神经元死亡。一旦某个神经元的权重更新后,其线性输出持续为负,ReLU 输出恒为 0,导数也恒为 0。此后该神经元再也无法被激活,参数彻底“冻结”,成为死神经元。
3.3 ReLU 的改进变体
针对神经元死亡问题,研究者提出了多种改进方案:
1. Leaky ReLU
公式:
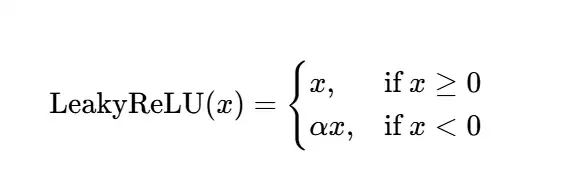
其中 α 是一个很小的正常数(如 0.01)。
特性:在 x<0 时不再直接置零,而是赋予一个微小的斜率 α。这样一来,负区间也有梯度流动,参数在训练中仍有更新机会。虽然更新幅度很小,但至少保留了恢复的可能性,相比 ReLU 的“一刀切”更为温和。
2. GELU —— Transformer 家族的新宠
公式:

特性:GELU 将输入值 x 与其概率 P(X≤x) 结合。可以理解为:它根据输入大小,以概率方式对输入进行缩放——x 为正时输出接近 x,为负时输出接近 0,但整个过程平滑且非线性。这种概率平滑性使 GELU 在 Transformer 模型(如 BERT、GPT)中大放异彩,尤其在自然语言处理任务中,通常比 ReLU 及其变体表现更优。
四、总结
回顾激活函数的发展历程,从经典的 Sigmoid 到主流的 ReLU,再到 Leaky ReLU 和 GELU 等改进版本,每一次演进都是在非线性表达能力、梯度传播效率和计算成本之间寻找更优的平衡。激活函数是神经网络能够成为“通用函数逼近器”的核心要素。在实际项目中,根据任务类型和数据特性选择合适的激活函数,往往是模型能否成功落地的关键环节。




