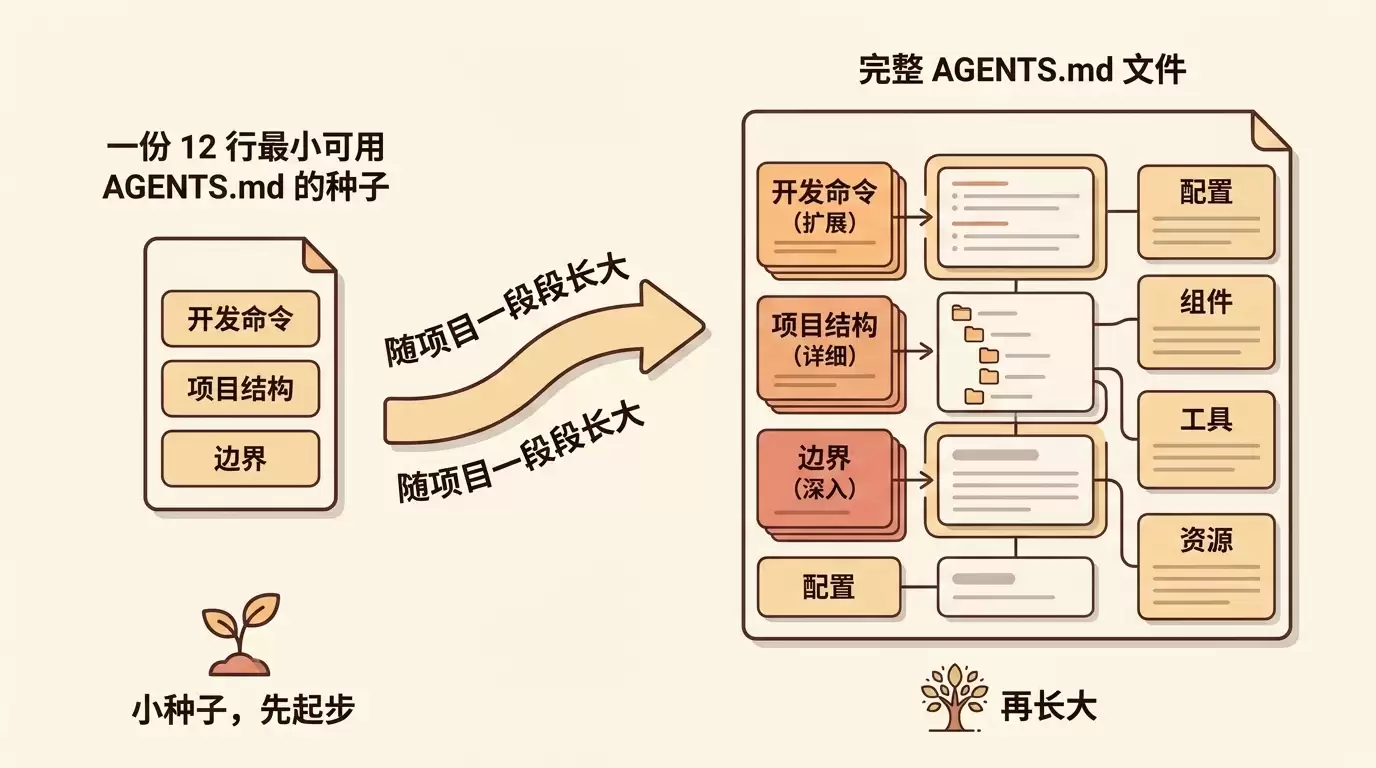
先把第一份抄走:12 行最小可用 AGENTS.md
不绕弯子,先给你一份能直接用的最小版本。在项目根目录新建文件,命名为 AGENTS.md,把下面这段贴进去,按项目把命令换成真实的:
# AGENTS.md## 开发命令- `pnpm install` — 装依赖- `pnpm test` — 跑测试(必须全过才算「干完了」)- `pnpm lint` — 检查代码## 项目结构- `src/` — 源码- `tests/` — 测试文件- `src/generated/` — 自动生成代码,永不手改## 边界- 永不:直接推送 `main` 分支、提交 `.env` 等含密钥的文件
就这 12 行。Codex(以及做了软链的 Claude Code)每次开对话会自动读它,从此至少不再犯三类最常见的错:跑错命令、改错目录、乱推 main。
这篇文章的写法,就是带你把这份 12 行的种子,一段一段长成一份完整、能扛住真实项目的 AGENTS.md——每加一段,都先告诉你它挡掉的是哪个具体的坑。你不用一次写全,照着长大的节奏走即可。
一、为什么是「自动读的文件」:先理解 Codex 的健忘
在往下长之前,先花一分钟搞懂这份文件为什么有用——这决定了你该往里写什么。
AI 编程袋里(Coding Agent)每次开新对话,对你项目的了解都从零开始。昨天告诉它的规则不在今天这轮对话的上下文窗口(context window)里,所以它记不住。这是 OpenAI Codex、Claude Code 共同的设计,有意为之:每次从头开始能避免历史错误一直跟着跑。代价是你得有一个「每次自动加载」的地方放项目规则——这就是 AGENTS.md 的全部意义。
所以判断「某条规则该不该进 AGENTS.md」只有一个标准:这条规则是不是每次开对话都要让 AI 知道。是,就写进去;只是这一次任务的临时要求,对话里说一句就行,别污染文件。
AGENTS.md 官方定义页把它讲得很干脆:
拆开三个词:简单——就是个 Markdown 文件,会写 README 就会写它;开放——一个被多家工具共同支持的格式,不是某家私有;引导——给 AI 提供项目上下文,不替代代码、不替代文档。
二、第一次长大:加「项目结构 + 三档边界」
12 行版能挡三类错,但跑一两天你会发现 AI 还是会越界——该问的不问就直接改了数据库、把自动生成的目录翻了个底朝天。这时候该补两段。
2.1 把项目结构写细一点
最小版只写了 src/ 和 tests/。真实项目里,AI 最容易踩的是「改了不该改的目录」。把重点目录、尤其是不能动的目录标出来:
## 项目结构- `src/app/` — Next.js 路由(App Router)- `src/lib/db.ts` — Prisma 客户端入口- `src/components/ui/` — shadcn/ui 组件库(改了会被覆盖,不要直接改)- `prisma/` — 数据库模型与迁移- `tests/` — 测试用例- `src/generated/` — 自动生成代码,永不手改
关键不在于把每个目录都列全,而在于标清楚哪些是地雷。src/generated/、src/components/ui/ 这种「改了白改、还会引发别的问题」的目录,是 AI 看不出来、必须你告诉它的。
2.2 三档边界:AGENTS.md 判断密度最高的一段
最小版只有一行「永不」。真正拉开效果的是把边界写成清晰的三档——必做 / 先问 / 永不做:
## 边界### 必做(Always do)- 每次提交前跑 `pnpm test` 和 `pnpm lint`- commit 信息用 Conventional Commits(feat: / fix: / docs: / chore:)### 先问(Ask first)- 增加新的 npm 包依赖- 改 `prisma/schema.prisma`、`next.config.js`、CI 配置### 永不做(Never do)- 直接推送到 `main` 分支(必须走 PR)- 提交 `.env` 或任何含密钥的文件- 改 `src/generated/` 目录
这里有个非常关键的观察:AI 对命令式语言的执行率,远高于「最好不要」「尽量」这种条件式语言。「未经审批不得修改 main 分支」比「最好别乱改老板的代码哦」清晰一个数量级。
到这一步,你的 AGENTS.md 大概 25~30 行,已经能扛住绝大多数日常翻车。
三、再长大:加「技术栈 + 代码风格」,但代码风格要克制
项目跑顺了,你会想让 AI 写出来的代码更像「自己人写的」。这时候加技术栈和代码风格——但代码风格这一段,是新手最容易写跑偏的地方。
3.1 技术栈:具体到版本号
## 技术栈- Next.js 15 + TypeScript(strict 模式)- 数据库:PostgreSQL + Prisma- 状态管理:zustand- 测试:Vitest(单元)+ Playwright(端到端)
写「React 项目」没什么用,写「React 18 + TypeScript + Vite + Tailwind」才有用。带上主要版本号,AI 才知道该用哪一代 API。
3.2 代码风格:只写「工具检不到」的规则
这里有条硬规则。HumanLayer 团队那句话值得逐字记住:
意思是:凡是 ESLint / Prettier / Ruff 这类工具能自动检查和修复的格式规则——缩进、引号、分号、import 顺序——一条都别写进 AGENTS.md。让大语言模型(LLM)去做这些事既慢又贵,还白白占掉上下文。
反例(不要这样写):
## 代码风格(反例:全是 linter 该管的)- 缩进 2 空格- 字符串用单引号- 行尾不要分号- import 顺序:第三方在前、本地在后- ……还有几十条
正例(只写有判断、和项目语境强相关的):
## 代码风格- 状态管理统一用 zustand,不要再引入 Redux(项目已统一)- 数据库操作必须走 `src/lib/db.ts` 单例,不要 `new PrismaClient()`- 业务错误用自定义 `ApiError` 类,系统错误才用 `throw`
这三条 ESLint 永远查不到——它们要求作者懂项目背景。这才是 AGENTS.md 该写的代码风格。
3.3 顺手补一段「测试约定」:告诉 AI 什么叫「干完了」
AI 编程袋里一个高频毛病是「自以为干完了」——代码写完没跑测试就交活,或者改坏了测试干脆把失败的用例删掉。补一小段测试约定能直接堵住这种操作:
## 测试约定- 测试文件命名 `*.test.ts`,紧挨源文件放- 改完代码必须跑相关测试,全过才算完成,不允许「先提交再修测试」- 端到端测试用 Playwright,配置在 `playwright.config.ts`- 永不为了让测试通过而删除或跳过失败用例(要先问我)
最后一条尤其关键。GitHub 那份 2500+ 仓库的经验里专门点了这个边界:测试袋里可以写测试,但绝不能因为某个测试失败、它又修不好,就把测试删掉。这种「破坏性偷懒」一旦发生很难察觉,写进边界提前堵死。
到这一步,你的 AGENTS.md 已经覆盖命令、结构、边界、风格、测试五个面,对单仓库项目基本够用了。下面两节是项目继续长大才会用到的形态:多目录、跨工具。
四、长到多目录:层级合并机制(Codex 怎么读多份 AGENTS.md)
项目一旦变成前后端分离、或者多个子项目共仓的单体仓库(monorepo),一份根目录 AGENTS.md 就不够用了——前端要 React 规则、后端要 Postgres 规则,混在一份里互相干扰。这时候 AGENTS.md 自然要长成「多份分布在不同目录」的形态。理解 Codex 怎么合并它们,是用好这一步的前提。
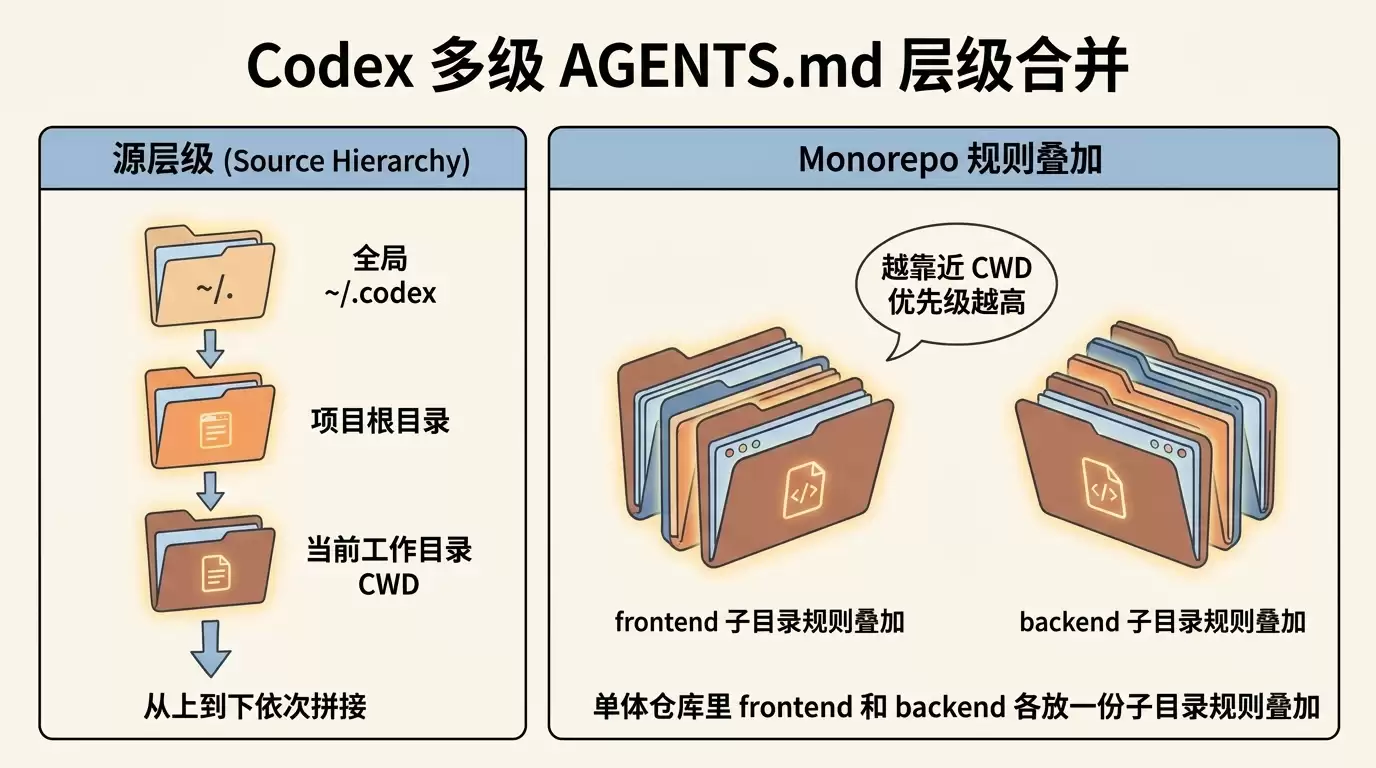
4.1 Codex 启动时的合并规则
OpenAI 官方 AGENTS.md 指南说明:Codex 每次启动会话时,会从全局到项目、从根目录到你的当前工作目录(CWD),按顺序拼接多份 AGENTS.md:
- 全局层:先看
~/.codex/(或你设的CODEX_HOME)。这一层先找AGENTS.override.md,没有再找AGENTS.md,只用第一个非空的文件。 - 项目层:从 Git 根目录一路向下走到 CWD,每一层目录依次找
AGENTS.override.md→AGENTS.md→ 配置里的回退文件名(下面 §4.4 讲),每层最多取一个。 - 拼接顺序:从根往下拼,用空行连接。越靠近 CWD 的内容排得越靠后、优先级越高——因为它出现在合并后提示词的更后面,按官方原文的说法,靠后的指令会覆盖(override)前面的。
4.2 一张图看懂
flowchart TDStart[Codex 启动] --> G["读全局 ~/.codex/AGENTS.md"]G --> R["读项目根 AGENTS.md"]R --> M[读中间目录 AGENTS.md,如有]M --> C[读 CWD 目录的 AGENTS.md,如有]C --> Merge["从根往下拼接(越近 CWD 越靠后、优先级越高)"]Merge --> Inject[注入对话上下文]classDef step fill:#1f6feb,color:#fff,stroke:#0d3a8a,stroke-width:2pxclassDef inject fill:#2da44e,color:#fff,stroke:#1a6b35,stroke-width:2pxclass G,R,M,C,Merge stepclass Inject inject
4.3 一个单体仓库的实际例子
假设你的单体仓库(monorepo)长这样:
my-saas/├── AGENTS.md← 整个仓库的通用规则├── frontend/│ └── AGENTS.md← 前端专属规则(React + Tailwind)└── backend/└── AGENTS.md← 后端专属规则(Node + Postgres)
你在 backend/ 目录里启动 Codex,它会按顺序读并拼接:
~/.codex/AGENTS.md(你的全局偏好)my-saas/AGENTS.md(仓库通用规则)my-saas/backend/AGENTS.md(后端规则,排最后、优先级最高)
注意它是三份叠加,不是只读最后一份。仓库通用规则依然生效,后端规则只是在冲突时优先。这也是分布式写法的好处:每个子项目只维护自己那一份,互不打架;你在 frontend/ 里也改不到 backend/ 的规则,文件层级天然成了权限边界。
4.4 两个进阶机制:override 和回退文件名
AGENTS.override.md:本层取代,不是整链覆盖。这是个容易被误解的点。同一层目录里如果有 AGENTS.override.md,Codex 在这一层只读它、不读同层的 AGENTS.md。但上级目录的 AGENTS.md 照常被读取并拼接——它不会把整条指令链都顶掉。
举例:my-saas/infra/AGENTS.override.md 只让 Codex 在 infra/ 这层不读 infra/AGENTS.md,而 my-saas/AGENTS.md(仓库通用)和 ~/.codex/AGENTS.md(全局)依然在合并链里。它的典型用途是「这个子目录的本层规则要换一套」(比如 infra/ 用 Terraform 不用 TypeScript),不是「这个子目录要无视所有上级规则」。
实操约定:
| 文件 | 是否进 git | 用途 |
|---|---|---|
AGENTS.md |
✅ 进 | 团队共享的项目规则 |
AGENTS.override.md |
❌ 不进(加进 .gitignore) |
个人临时调整,不污染团队配置 |
回退文件名——旧仓库零改名接入。 如果项目已经用了别的指令文件名(比如 TEAM_GUIDE.md),不想改名,在 ~/.codex/config.toml 里配一行:
project_doc_fallback_filenames = ["TEAM_GUIDE.md", ".agents.md"]
之后 Codex 在每层目录的查找顺序就变成:AGENTS.override.md → AGENTS.md → TEAM_GUIDE.md → .agents.md。旧仓库一行配置接入,不必动现有文件。
4.5 大小上限:32 KiB,但你几乎碰不到
Codex 对合并后的总内容有大小上限,由 project_doc_max_bytes 控制,官方默认值是 32 KiB(即 32768 字节),超过的部分会被静默丢弃。
新手几乎碰不到这个上限——几十行的 AGENTS.md 只占几 KB。真要在多级仓库里触顶,可以在 ~/.codex/config.toml 里调大:
project_doc_max_bytes = 65536# 调到 64 KiB
五、长到跨工具:AGENTS.md、CLAUDE.md、README.md 怎么分工
到这一步,你可能同时在用 Codex 和 Claude Code,或者团队里有人用 Cursor。一个高频困惑冒出来:我到底写 AGENTS.md 还是 CLAUDE.md?和 README 又是什么关系?
5.1 三个文件,三种读者
| 文件 | 写给谁看 | 内容侧重 | 谁定义 |
|---|---|---|---|
| README.md | 主要给人看,AI 也会读 | 项目是什么 / 为什么存在 / 怎么贡献 | 通用 Markdown 惯例 |
| AGENTS.md | 给 AI 编程袋里看 | 怎么跑命令 / 代码风格 / 不能动哪里 | agents.md 开放格式(Codex、Cursor、Gemini CLI、GitHub Copilot 等共同支持) |
| CLAUDE.md | 给 Anthropic 的 Claude Code 看 | 同 AGENTS.md,但 Claude Code 专读这个名字 | Anthropic 私有 |
一句话分工:README 给来访的人看项目门面,AGENTS.md 给 AI 看工作守则,CLAUDE.md 是 Claude Code 专用的那个文件名。三者可以共存——README 写愿景和贡献指南,AGENTS.md 写命令和边界,两边别互相重复。
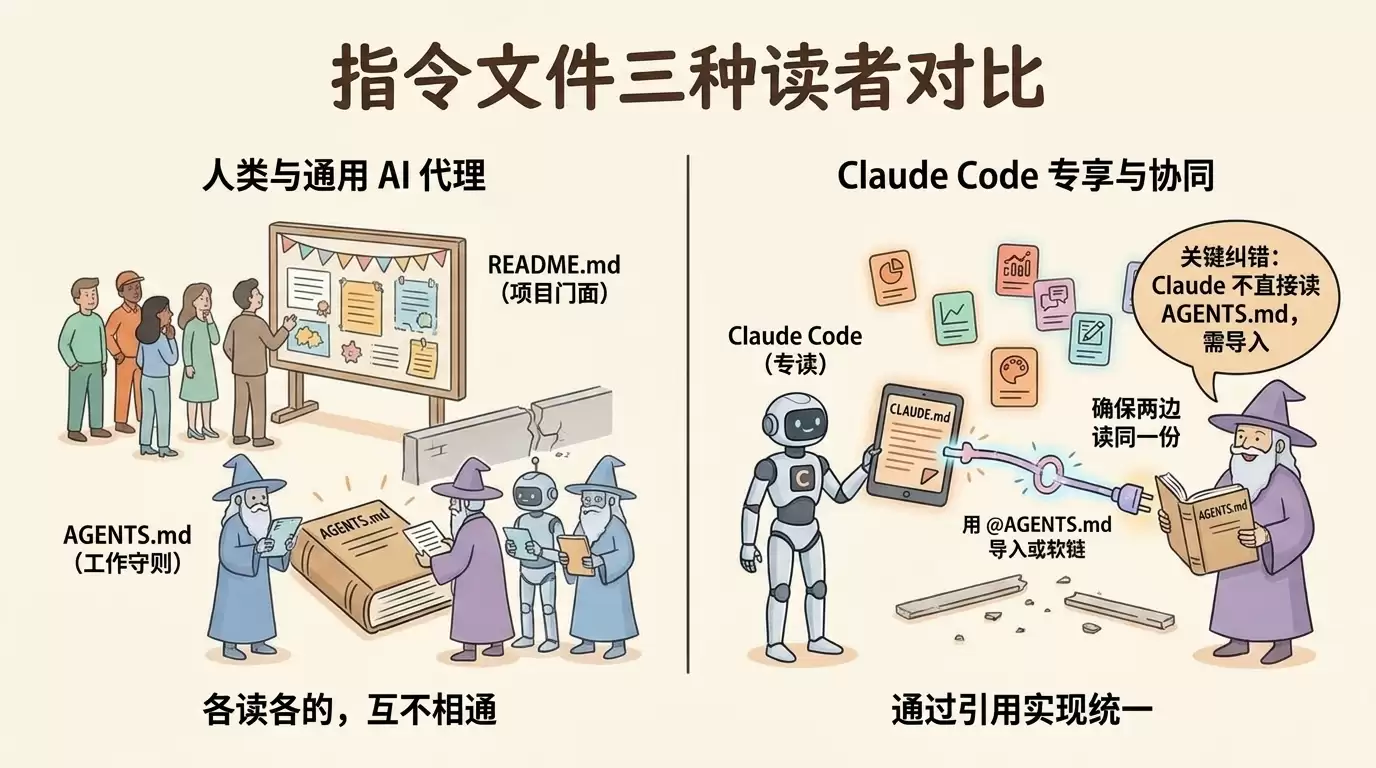
5.2 关键纠错:Claude Code 不读 AGENTS.md
这一点几乎所有新手都搞错,连不少教程都写错,必须讲清楚。
Claude Code 不会自动读 AGENTS.md。 Anthropic 官方文档原文是:
也就是说,AGENTS.md 不是 Claude Code「找不到 CLAUDE.md 时的回退」——它根本不在 Claude Code 的查找路径里。这也对得上 agents.md 官方支持列表:上面列了 Codex、Cursor、Gemini CLI、GitHub Copilot 的编程袋里、Jules、Amp 等一长串工具,但没有 Claude Code。
那同时用 Codex 和 Claude Code 怎么办?官方给了两种做法,都是「让两个工具读同一份内容」:
做法一(官方推荐):在 CLAUDE.md 里引入 AGENTS.md。 建一份 CLAUDE.md,用 Claude Code 的 @ 导入语法把 AGENTS.md 引进来,还能在下面补 Claude 专属指令:
@AGENTS.md## Claude Code 专属- 改 `src/billing/` 下的代码时先进 plan mode。
做法二:直接做软链。 如果不需要给 Claude 加专属内容,让 CLAUDE.md 软链到 AGENTS.md 即可:
ln -s AGENTS.md CLAUDE.md
这样磁盘上只有一份真实内容(AGENTS.md),CLAUDE.md 是指向它的软链,Codex 和 Claude Code 各读各的文件名、内容零漂移。
5.3 那 README 已经写全了,还要 AGENTS.md 吗?
要。README 是叙事性的、写给人读的,AI 需要的是机器可读、命令式、明确的指令。最佳实践是:先有 README 讲清项目是什么,再单写一份精简的 AGENTS.md 讲清 AI 怎么干活,两者各司其职。
六、长成完整后长什么样:一份可整段抄走的版本
把前面一段段加上去的内容拼起来,一个典型单仓库项目长成后的 AGENTS.md 大概是这样。你可以整段复制,按方括号里的提示填成自己项目的真实内容,用不到的段直接删:
# AGENTS.md> 给 AI 编程袋里(OpenAI Codex / Claude Code 等)的项目指令文件。## 项目简介[Next.js + TypeScript + Prisma + Postgres] 的 SaaS 站点,主要功能:[一句话]。## 开发命令- `pnpm install` — 装依赖(首选 pnpm,不要用 npm / yarn)- `pnpm dev` — 起开发服务器(端口 3000)- `pnpm test` — 跑单元测试(全过才算「干完了」)- `pnpm lint` — 跑 ESLint + Prettier- `pnpm build` — 构建生产版本## 项目结构- `src/app/` — Next.js 路由(App Router)- `src/lib/db.ts` — Prisma 客户端入口- `src/components/ui/` — shadcn/ui 组件(改了会被覆盖,不要直接改)- `prisma/` — 数据库模型与迁移- `src/generated/` — 自动生成代码,永不手改## 技术栈- Next.js 15 + TypeScript(strict)/ PostgreSQL + Prisma / zustand / Vitest + Playwright## 代码风格- 状态管理统一用 zustand,不引入 Redux(项目已统一)- 数据库操作走 `src/lib/db.ts` 单例,不要 `new PrismaClient()`- 业务错误用自定义 `ApiError`,系统错误才 `throw`## 测试约定- 测试文件命名 `*.test.ts`,紧挨源文件- 改完代码必须跑相关测试,全过才算完成- 永不为了让测试通过而删除失败用例(先问我)## 边界### 必做- 提交前跑 `pnpm test` 和 `pnpm lint`- commit 用 Conventional Commits(feat: / fix: / docs:)### 先问- 增加新依赖、改 `prisma/schema.prisma` / `next.config.js` / CI 配置### 永不做- 直接推 `main`(必须走 PR)、提交 `.env` 或含密钥的文件、改 `src/generated/`## 引用- 详细架构 → `docs/ARCHITECTURE.md`- API 文档 → `docs/API.md`
注意最后的「引用」段:AGENTS.md 自己要短,详细的架构、API 文档放在别的文件里,用一行指针指过去就行——AI 需要时会自己去读,不必把全文塞进来占上下文。
这份大约 50 行,已经是「完整」的形态了。它不是你第一天该有的样子,是跑过一两周、踩过几次坑之后自然长成的样子。别一上来照抄整份,从前面那 12 行开始,缺哪段补哪段。
七、长期维护:把 AGENTS.md 当活文档
到这里你的 AGENTS.md 已经从 12 行长到了几十上百行,覆盖命令、结构、边界、风格、可能还跨了多目录和多工具。还有一件大多数人忽略的事:它不是写完归档的文件,是要持续裁剪的活文档。
两个明确的改动信号:
| 信号 | 动作 |
|---|---|
| AI 反复犯同一个错(≥ 2 次) | 加一条规则进 AGENTS.md,下次自动避开 |
| 某条规则项目里已经不适用了 | 删掉它,否则 AI 还按旧的做 |
| 加了规则 AI 还是忽略 | 把它挪进「永不做」段更显眼,或拆成更短的单句 |
关于「该写多短」,几个有出处的参照点,按你的场景取:
- HumanLayer 团队公开他们自己的根级 CLAUDE.md 不到 60 行,并主张「指令越少越好,理想情况只留对任务普遍适用的那些」。
- Anthropic 对 CLAUDE.md 的官方建议是「目标控制在每份文件 200 行以内,更长会消耗更多上下文、降低遵循度」。
两个数字都指向同一个方向:短的永远比长的好。所以维护的核心动作是「删」,不是「加」——每加一条都问一句「这条是不是每次开对话都要让 AI 知道」,答案是「不一定」的,就别留。
八、把 AI 当起草工,别当拍板编辑
单独拎出来讲,因为这是新手最纠结的问题:能不能让 AI 自己生成 AGENTS.md?
Claude Code 有 /init 命令,能扫一遍项目、自动生成一份 CLAUDE.md(已有 AGENTS.md 时还会把它的内容并进来)。让它出草稿完全可以——但出来的东西你必须自己过一遍,原因有二:
- 命令可能是「猜」的。 自动生成会写出看起来合理、但和项目真实命令对不上的步骤。这种错最坑,因为它看着对。
- 容易堆套路话。 自动生成倾向于把「可能有用」的东西都塞上,信息密度低,反而稀释你真正想强调的规则。
所以正确姿势是:让 AI 起草当骨架,你来核对和裁剪——保留它对的部分(项目结构、能扫出来的命令),删掉空话,补上只有你知道的真实约束(哪个目录是地雷、哪条业务规则不能破)。把 AI 当起草工,最终拍板的编辑是你。
九、新手坑速查(一次看全)
前面分散在各节的坑,集中放这里方便回查:
| 坑 | 后果 | 怎么避 |
|---|---|---|
| 憋着写「大而全」迟迟不动笔 | 永远写不出第一份 | 先上 12 行能跑的,再随项目长 |
| 边界写成模糊提醒 | AI 没法执行 | 每条都能验证:跑什么命令 / 碰什么文件 / 要不要先问 |
| 把 ESLint 能管的格式规则堆进去 | 文件臃肿、AI 分心 | 格式交给 linter,AGENTS.md 只写有判断的规则 |
触顶就调大 project_doc_max_bytes |
治标,AI 准确度反降 | 先裁剪、再把专属规则下沉子目录 |
| 以为 Claude Code 会读 AGENTS.md | 规则根本没生效 | 用 @AGENTS.md 导入或软链,让 CLAUDE.md 读它 |
| 软链建反方向 / Windows 直接软链 | 内容没接上 / 权限报错 | 新手先建 AGENTS.md 再软链;Windows 用 @AGENTS.md 导入 |
| 把 override 当整链覆盖 | 误删上级通用规则 | override 只取代本层,上级照常合并 |
| AI 生成后原样提交 | 命令对不上、套路话多 | 当草稿核对裁剪,自己拍板 |
| 写完归档不再维护 | 规则慢慢失效 | 当活文档,反复犯错就加、不适用就删 |
| 从陌生仓库直接抄 AGENTS.md | 可能中隐形字符注入 | 先看内容、扫隐形字符,变更走 PR |
最后一条单独说一句:安全公司 Pillar Security 在 2025 年披露了一类「规则文件后门」(Rules File Backdoor,原始报告)——攻击者在这类指令文件里塞 Unicode 隐形字符注入隐藏指令。因为 AGENTS.md 的内容会进入 AI 的指令上下文,从不可信仓库复制前一定先看一遍,并把 AGENTS.md 当代码一样走 PR 评审。
十、写完先自检
照着第一份长到这一步,发布前对自己问一遍:
- [ ] 开发命令写清了吗(装依赖、跑测试、构建)?
- [ ] 项目结构里标出地雷目录了吗(哪些自动生成、不能改)?
- [ ] 有清晰的「永不做」硬约束吗(不推 main、不提交密钥)?
- [ ] ESLint / Prettier 能做的格式规则剔除了吗?
- [ ] 跨工具用时,CLAUDE.md 是用
@AGENTS.md导入或软链读到同一份吗? - [ ] AI 生成的草稿我自己核对裁剪过了吗?
- [ ] 我打算定期回顾、把过时规则删掉吗?
- [ ] 它当代码 commit 进 git 了吗?
任何一题答「没」,回去看对应章节。
一句话收官
AGENTS.md 不用一次写全。先上 12 行能跑的,再随项目一段一段长大——加项目结构挡改错目录,加三档边界挡越权,加代码风格让 AI 写得像自己人,长到多目录就分层、长到跨工具就用导入或软链让 CLAUDE.md 读同一份。
记住三件事就够:先起步、把格式交给 linter、当活文档定期删。AI 老犯错到 AI 越用越准,差的就是这一份会长大的文件。




