先说个大背景。现在AI大模型火得一塌糊涂,DeepSeek R1、千问这些大家伙,训练和微调都离不开高质量数据集。但问题来了——数据都在网页里,想把它结构化地扒下来,那可真是一场硬仗。反爬、验证码、动态页面……光想想就头大。尤其对于中小企业,没那个技术团队去死磕这些,成本也扛不住。
那有没有捷径?有。市面上现在有专门干这活的工具,比如今天要聊的Web Unlocker API、Web Scraper和SERP API。它们不是普通的袋里,而是把“如何绕过防护、伪装浏览器、处理验证码”这些脏活累活全都封装好了,你只需发个请求,它就能把干净的数据吐给你。下面咱们就逐个看看怎么用。
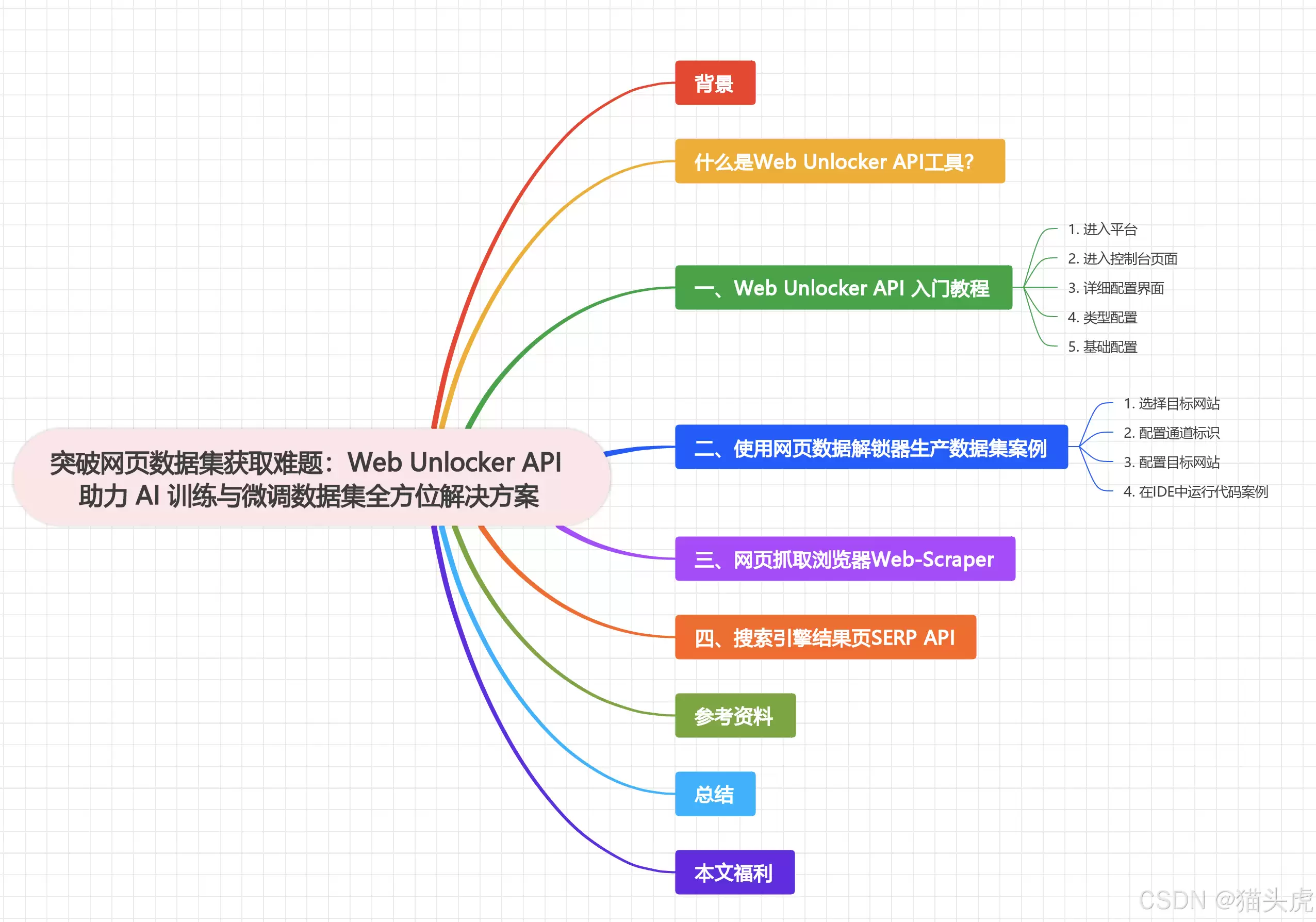
Web Unlocker API:直击高防护网站的“破冰船”
先说说这个明星产品。它背后依托Bright Data的袋里基础设施,但核心在于三个组件:请求管理、浏览器指纹伪装和内容验证。你不需要关心怎么找袋里、怎么设cookie、怎么绕过CAPTCHA——系统自动搞定。你只需要发一个API请求,它就把干净的HTML或JSON返给你。对于亚马逊这类防护极高的网站,这玩意儿简直就是神器。
一、入门教程:三步上手
用起来很简单,逻辑就是:进入平台→创建通道→调用API。具体操作我们一步步看。
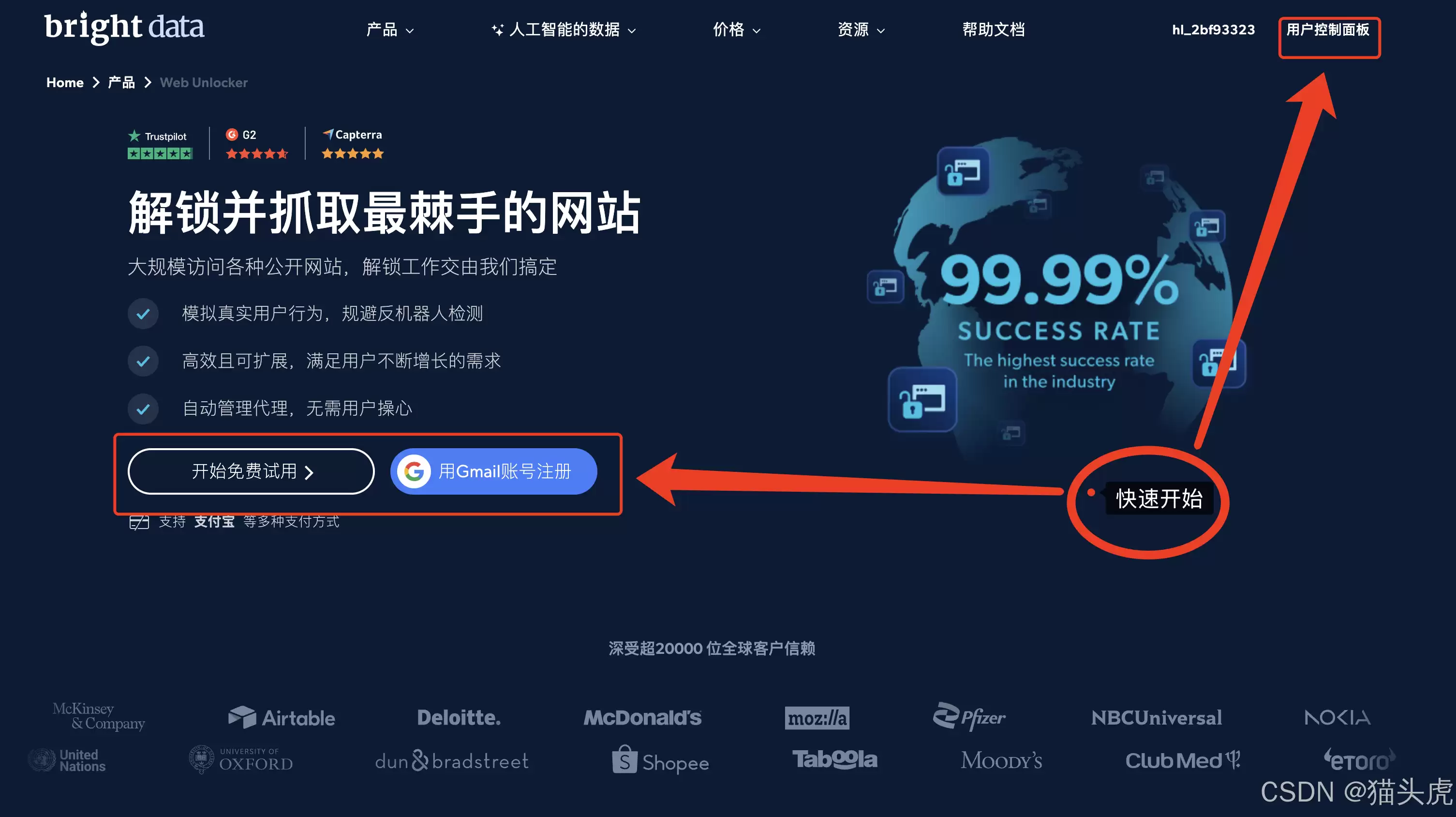
1. 进入平台
通过两个入口可以快速进入控制台:
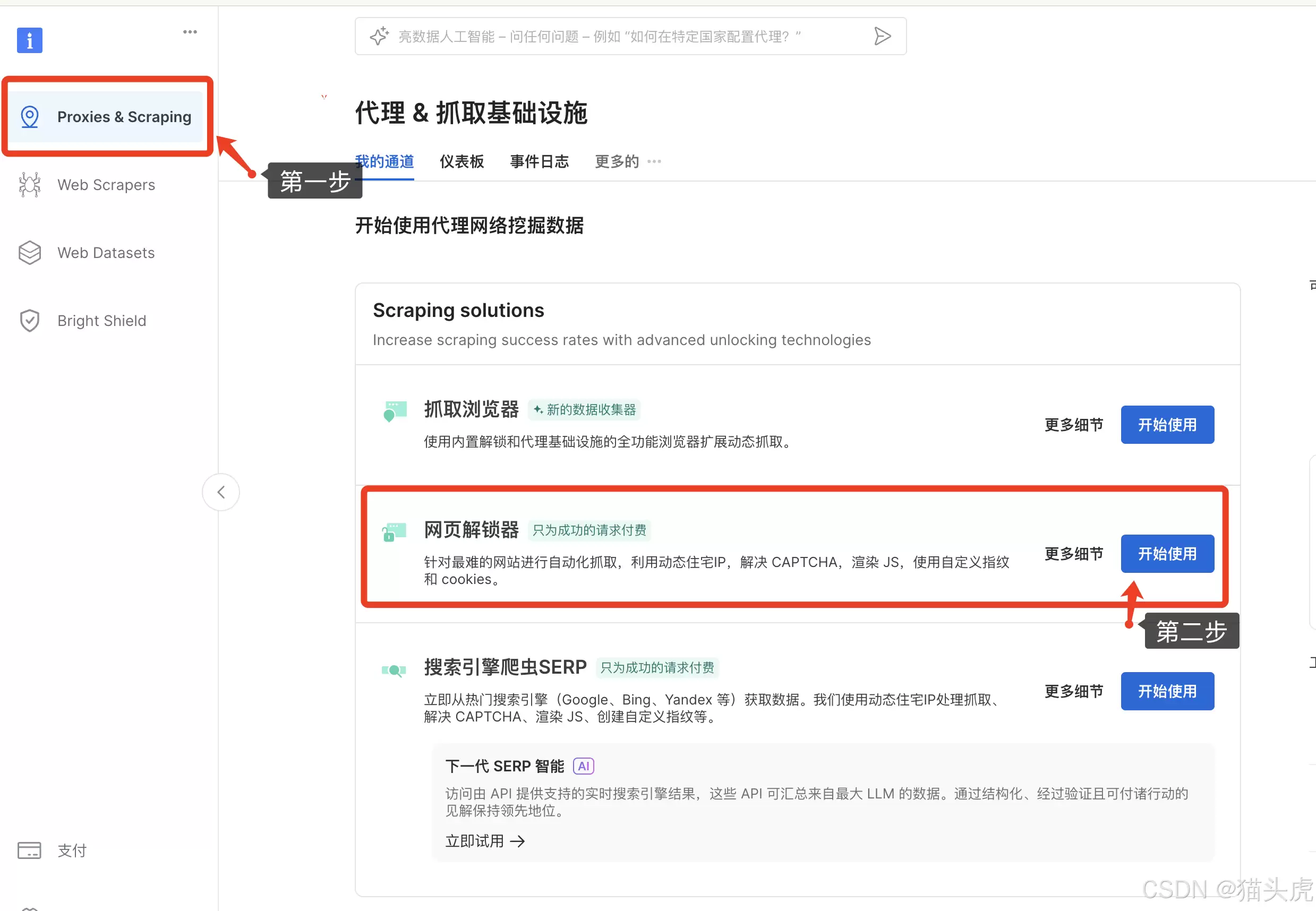
2. 打开控制台
在左侧菜单找到“Proxies & Scraping”,右侧就能看到“网页解锁器”,点它开始配置。
3. 详细配置
配置界面分为三个区域:袋里/抓取类型、基本配置、高级设置。
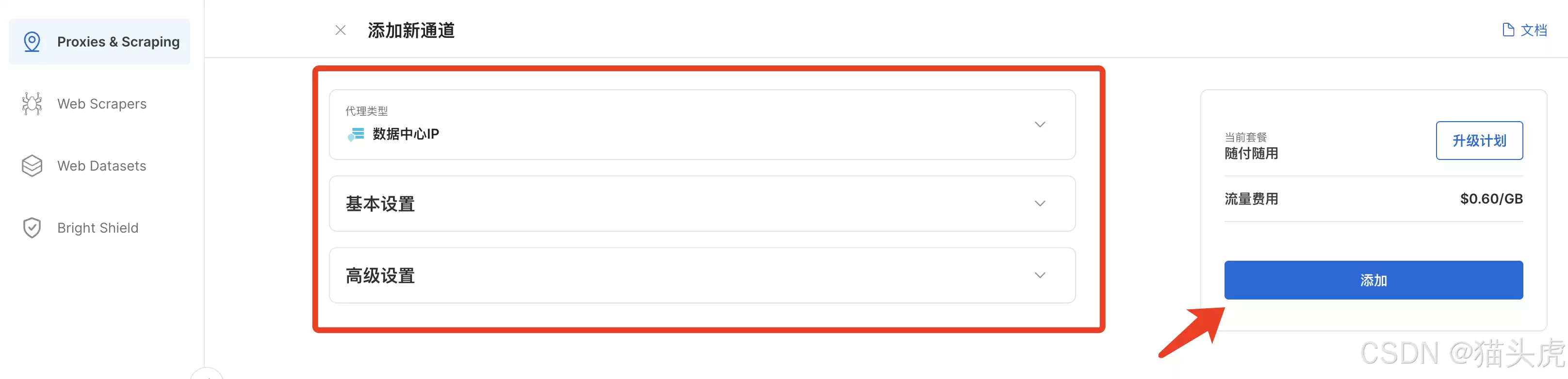
4. 选择类型
在“袋里/抓取类型”下拉里,选“网页解锁器”。
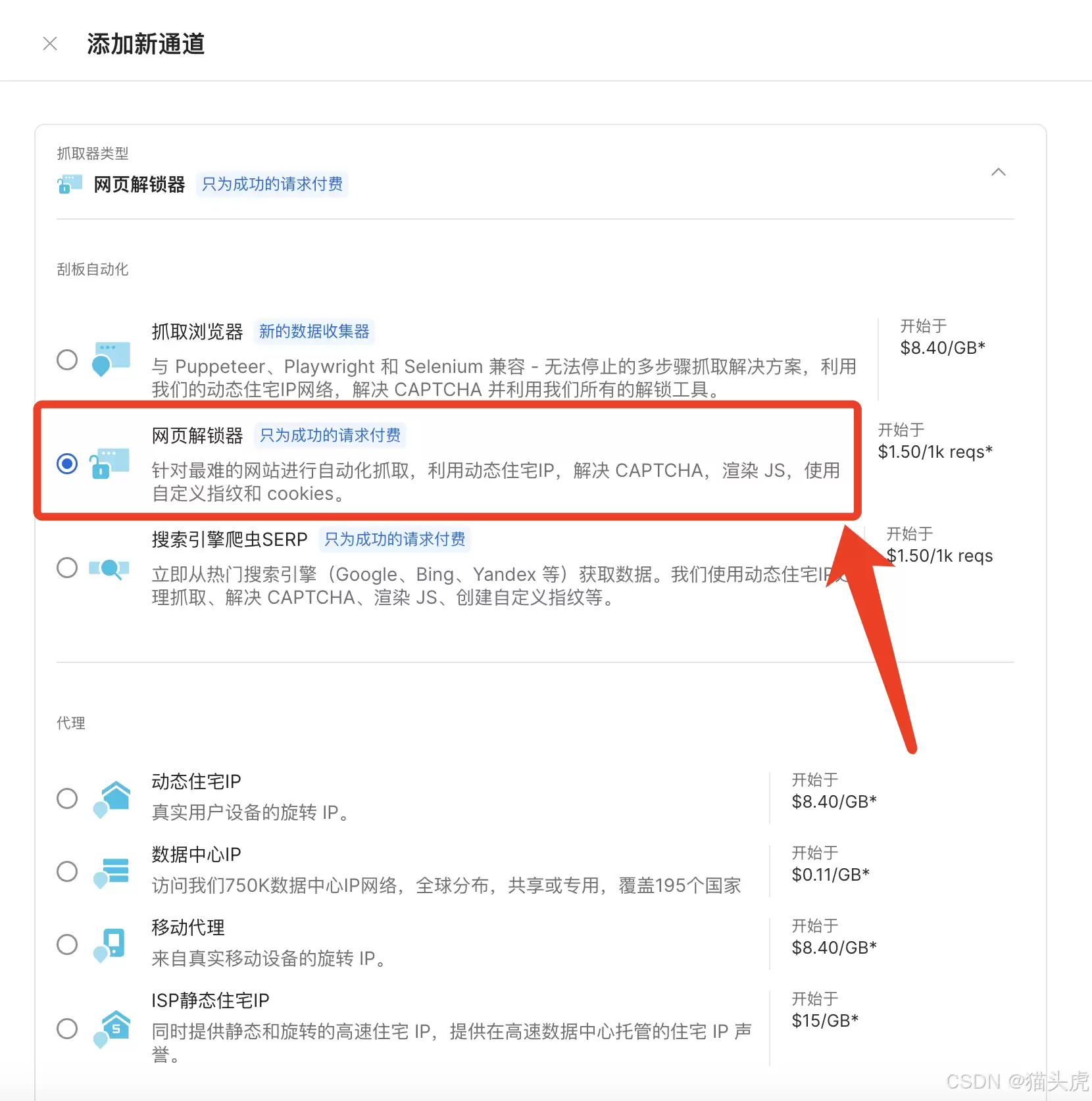
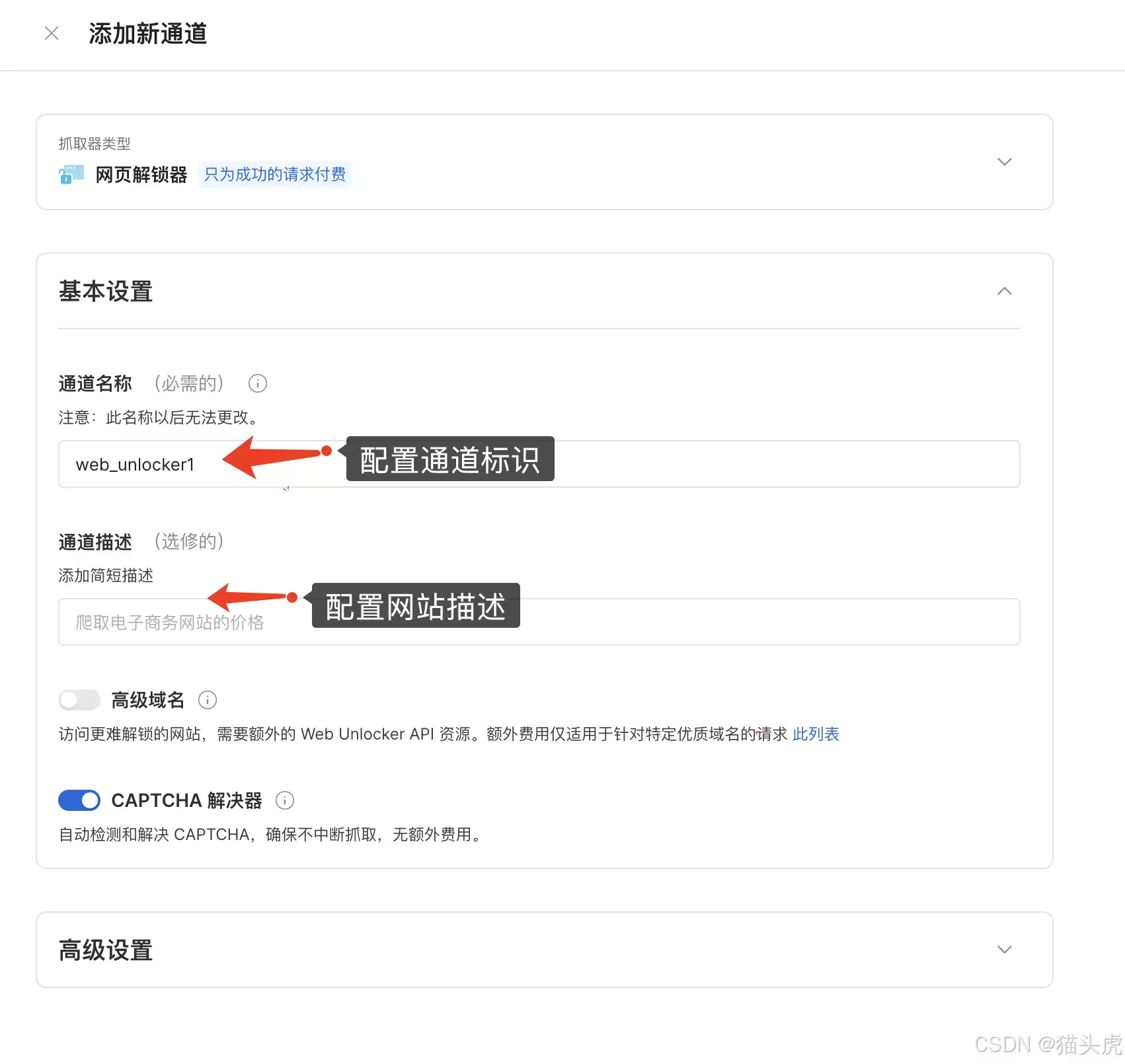
5. 基础配置
填好目标网址、地域偏好等基本信息,基本就齐活了。
二、实战案例:从目标网站生产数据集
光说理论不行,我们拿一个真实站点——Alignment Forum(一个AI安全研究社区)来演示。
1. 选定目标
目标网址:https://www.alignmentforum.org
2. 创建通道
在左侧配置好基本参数,点击右侧“添加通道”。创建成功后,系统会提供多语言的代码示例。这里我选Python。
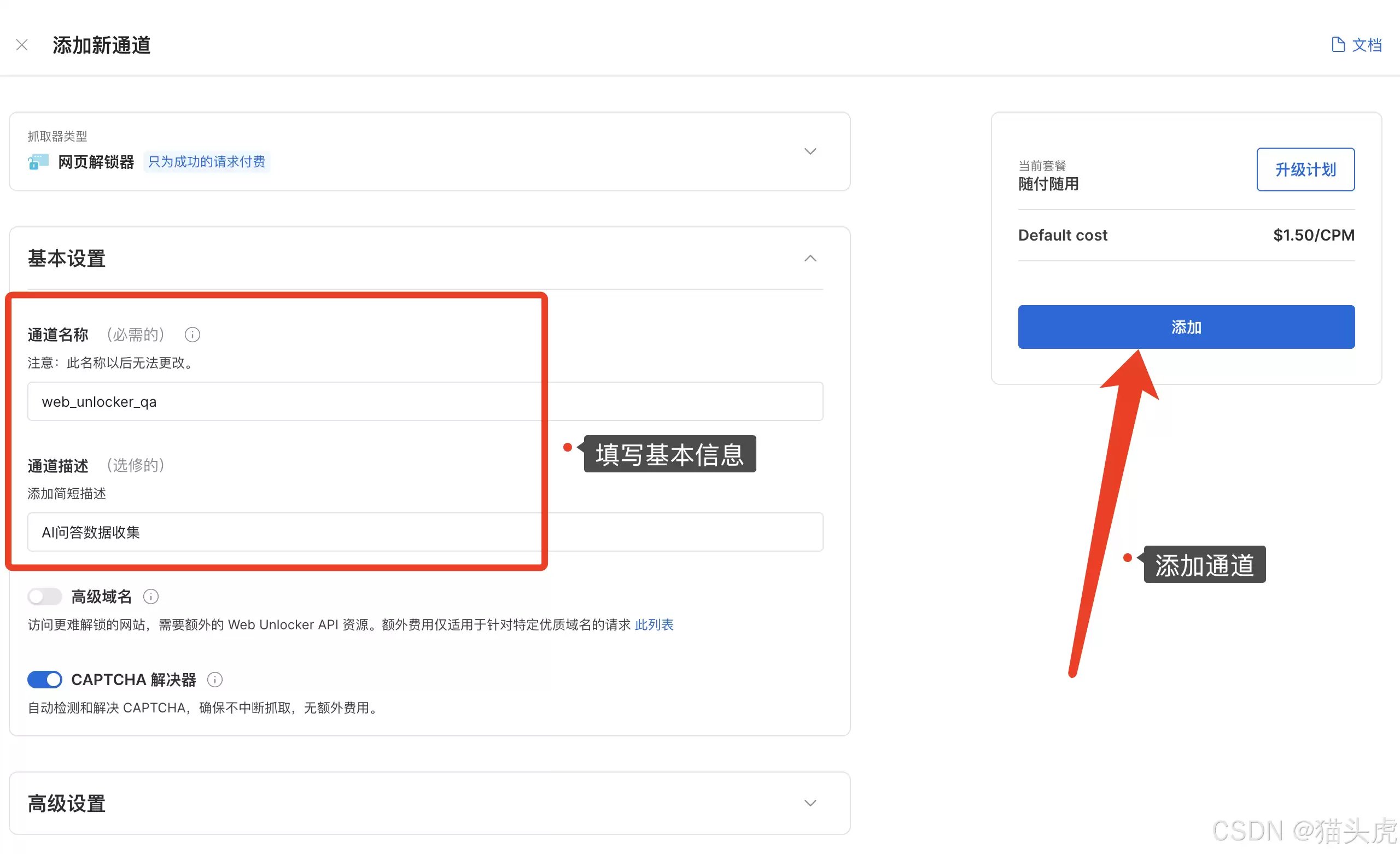
3. 配置目标
按图示填写目标URL即可:
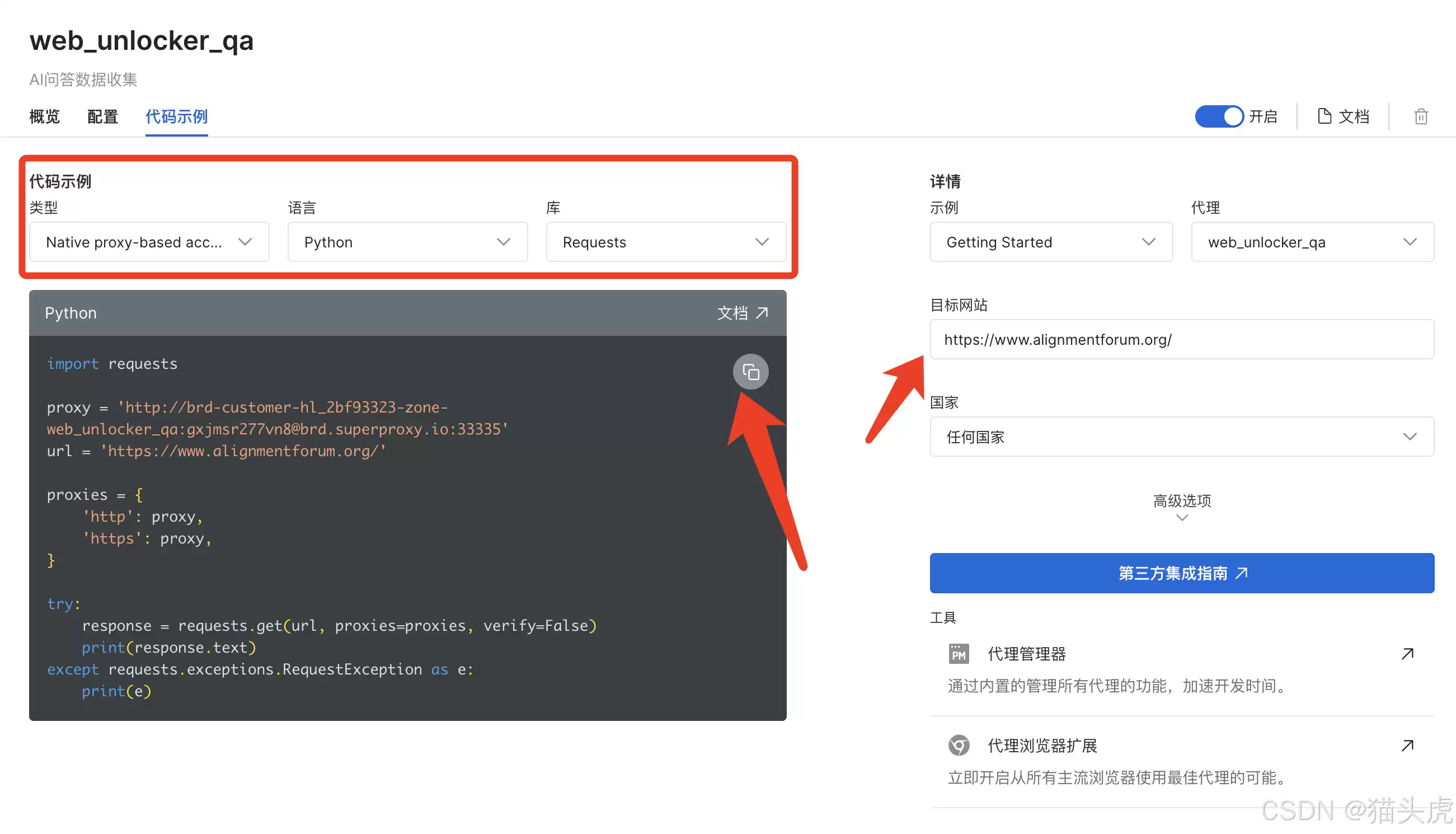
4. 跑通代码
把官方给的示例代码复制到IDE里运行,效果如下:
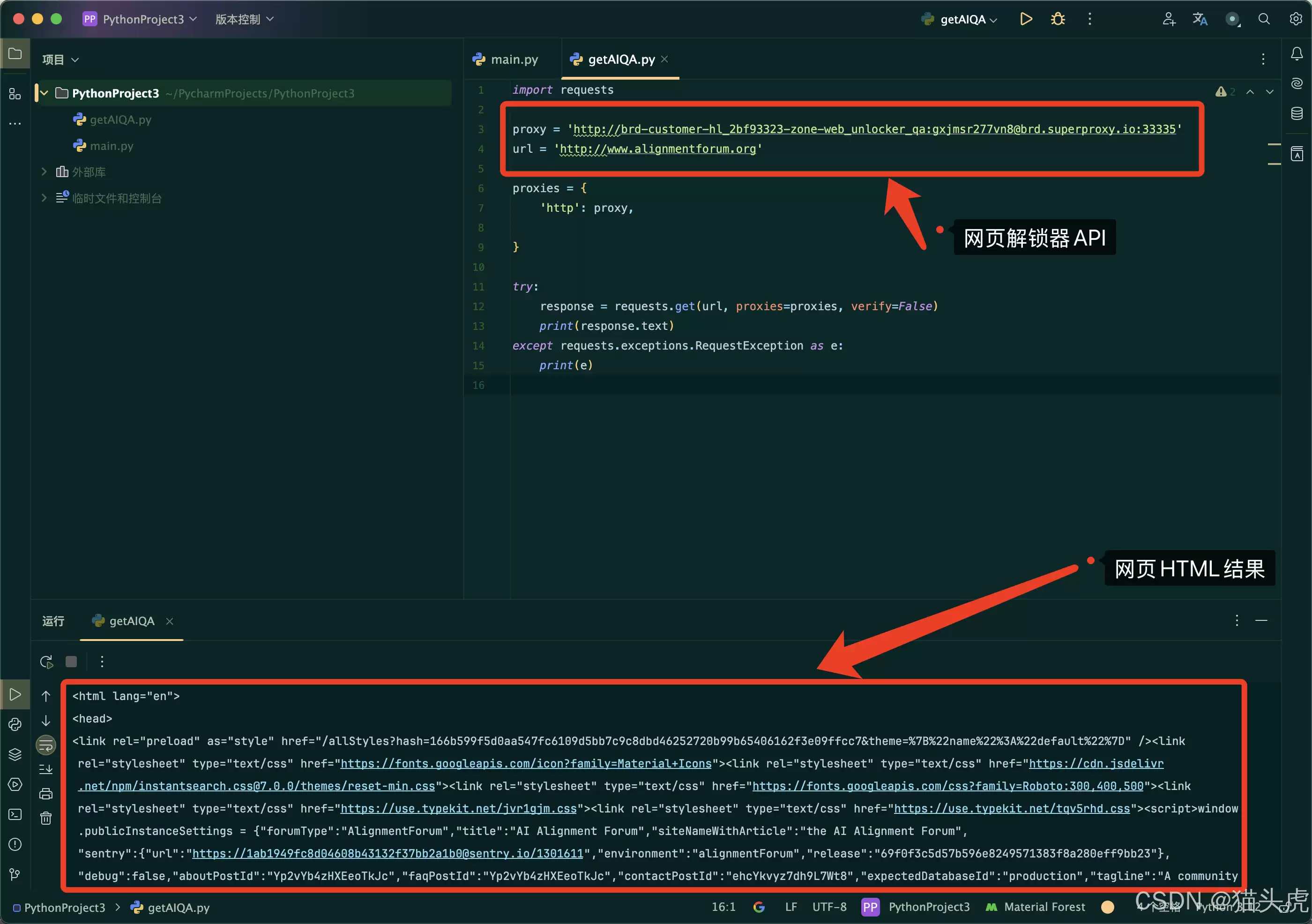
示例代码偏基础,实际生产环境还需要做细粒度清洗。我稍微做了字段提取,效果如下:
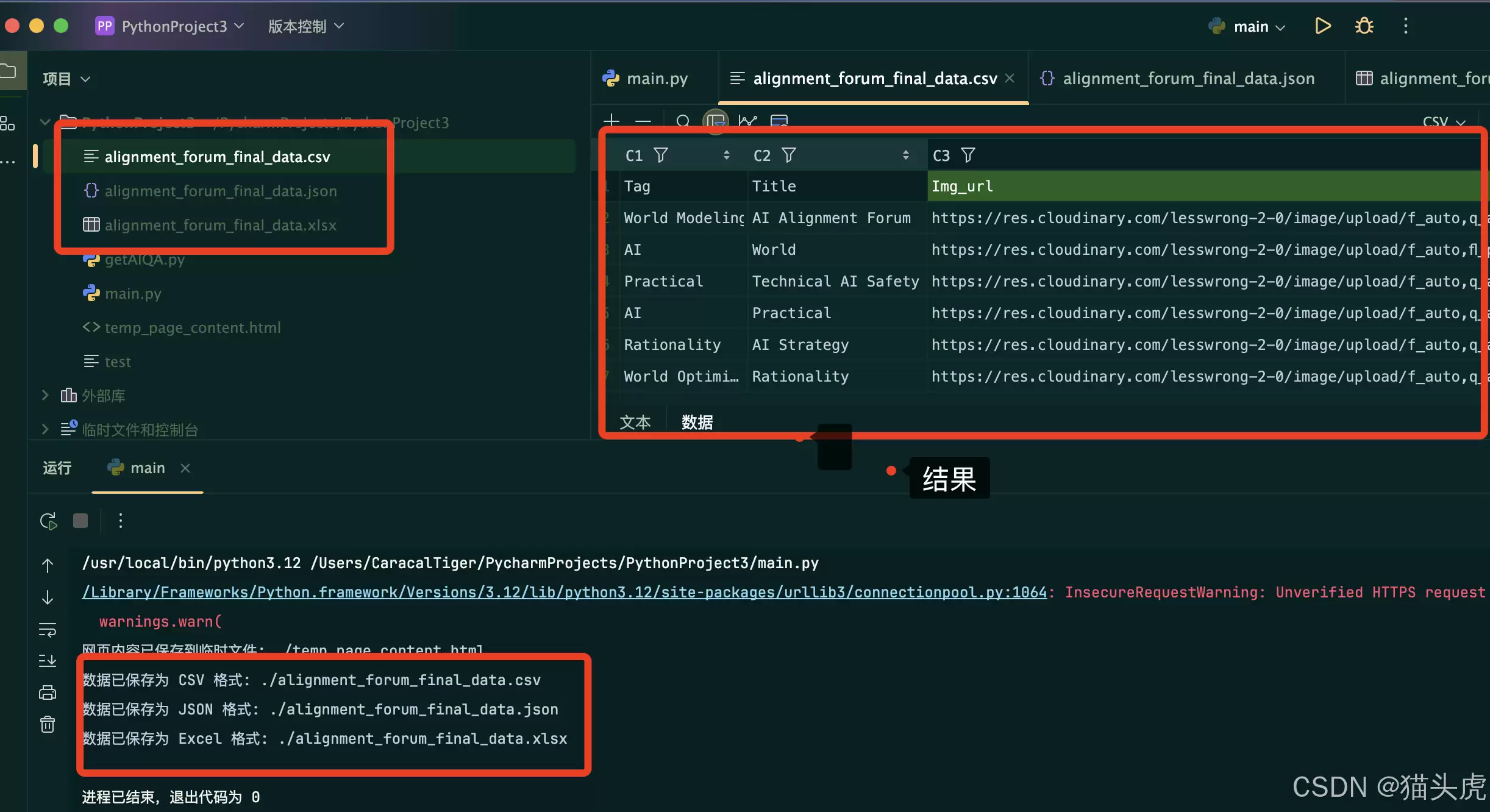
这是部分提取代码(用于提取类别、标题、坐标、图片URL):
for category in categories:
category_section = soup.find('div', {'class': category})
if category_section:
tag = category_section.get('data-tag', '')
title = category_section.find('h2').text if category_section.find('h2') else ''
coords = category_section.get('data-coords', '')
img_url = category_section.find('img')['src'] if category_section.find('img') else ''
dataset.append({'Tag': tag, 'Title': title, 'Coords': coords, 'Image URL': img_url})三、Web Scraper:全能型网页抓取浏览器
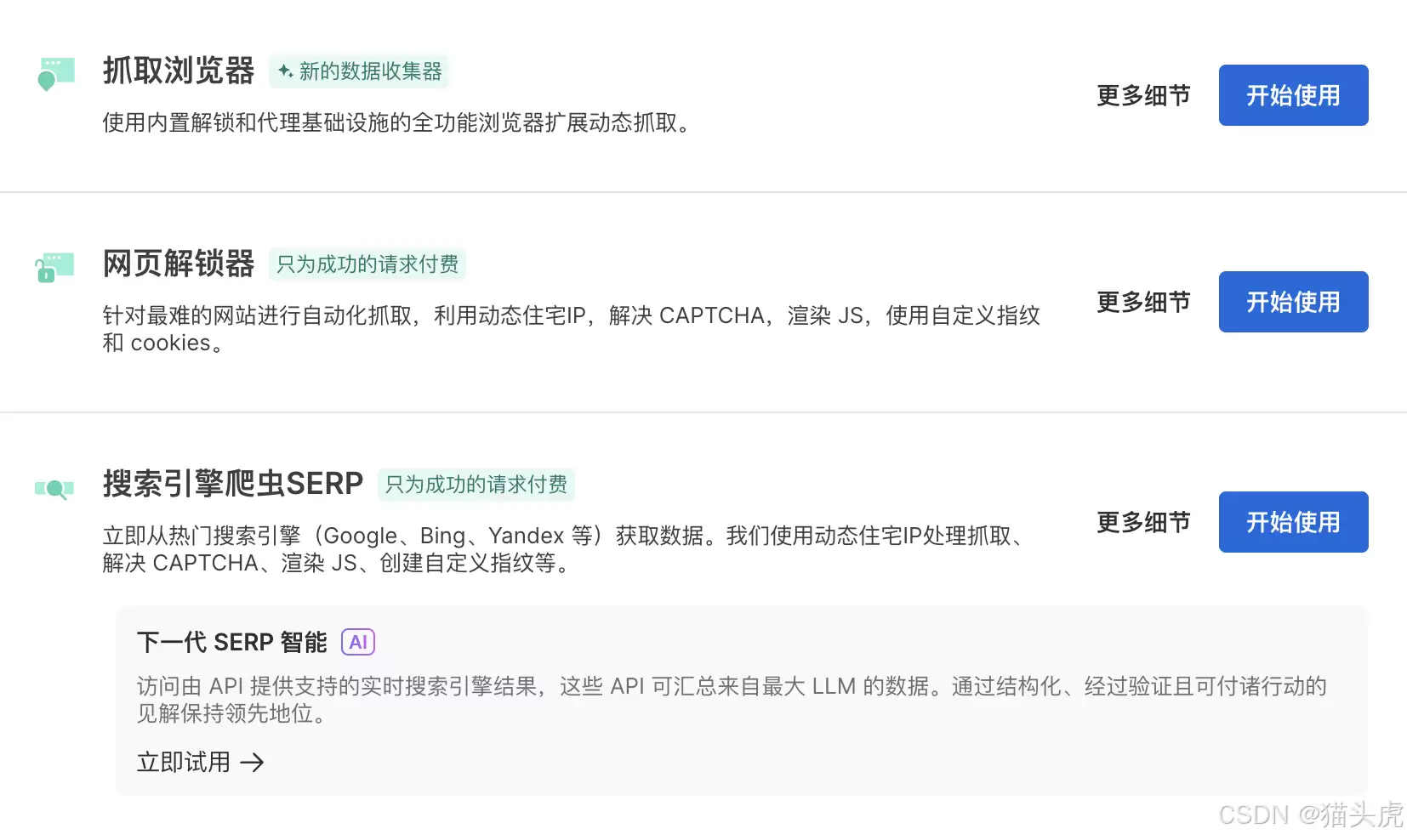
如果你需要抓取动态加载的复杂页面(比如商品详情、评论瀑布流),Web Scraper更合适。它本质是一个自动化浏览器,能模拟真实用户点击、滚动、输入。使用也很简单,在配置页面把“网页解锁器”切换成“网页抓取浏览器”即可。
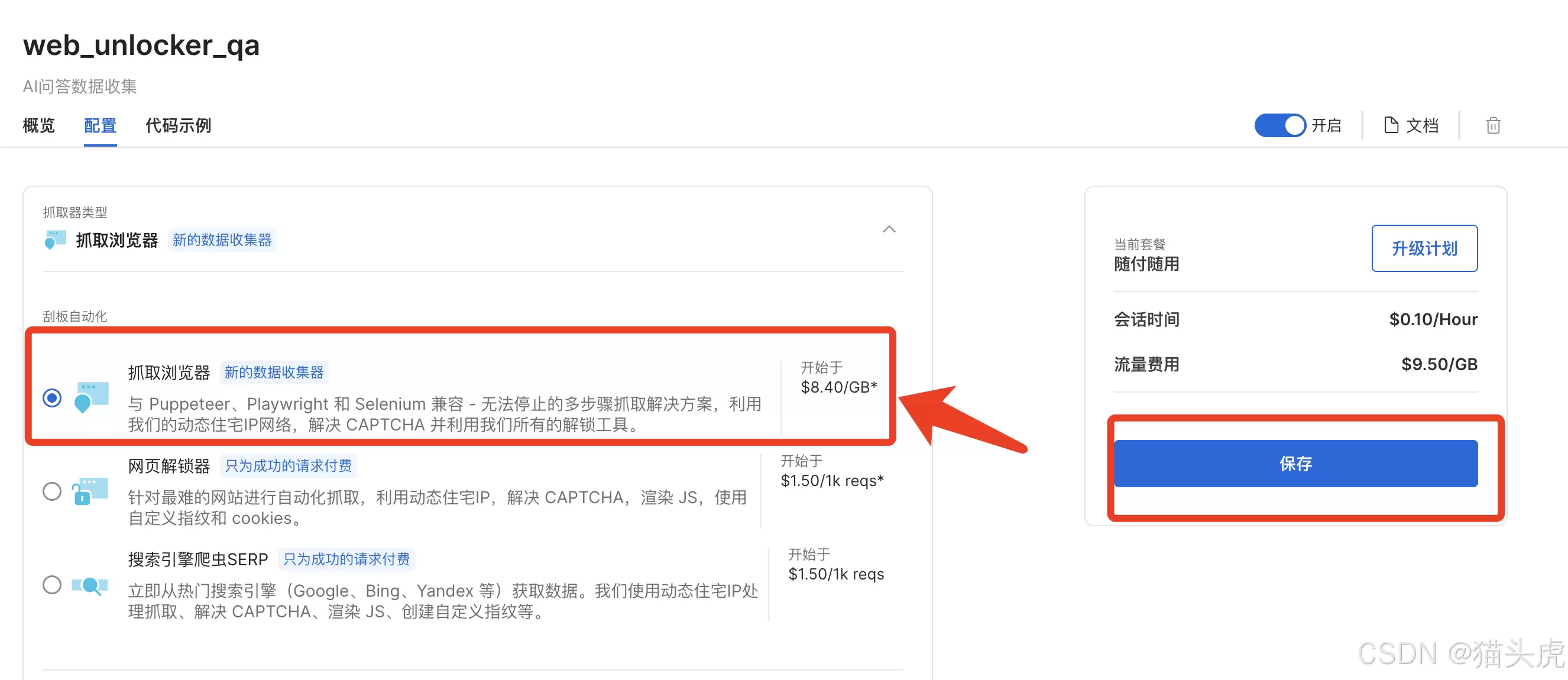
它是网页解锁器抓取套件的一部分,主打多步骤数据收集。
四、SERP API:专攻搜索引擎结果页
SEO分析、市场调研、领域知识库构建,经常需要抓取Google、Bing的搜索结果。SERP API就是干这个的——专门解析搜索引擎结果页面,返回结构化数据。使用同样简单:切换配置、保存通道。
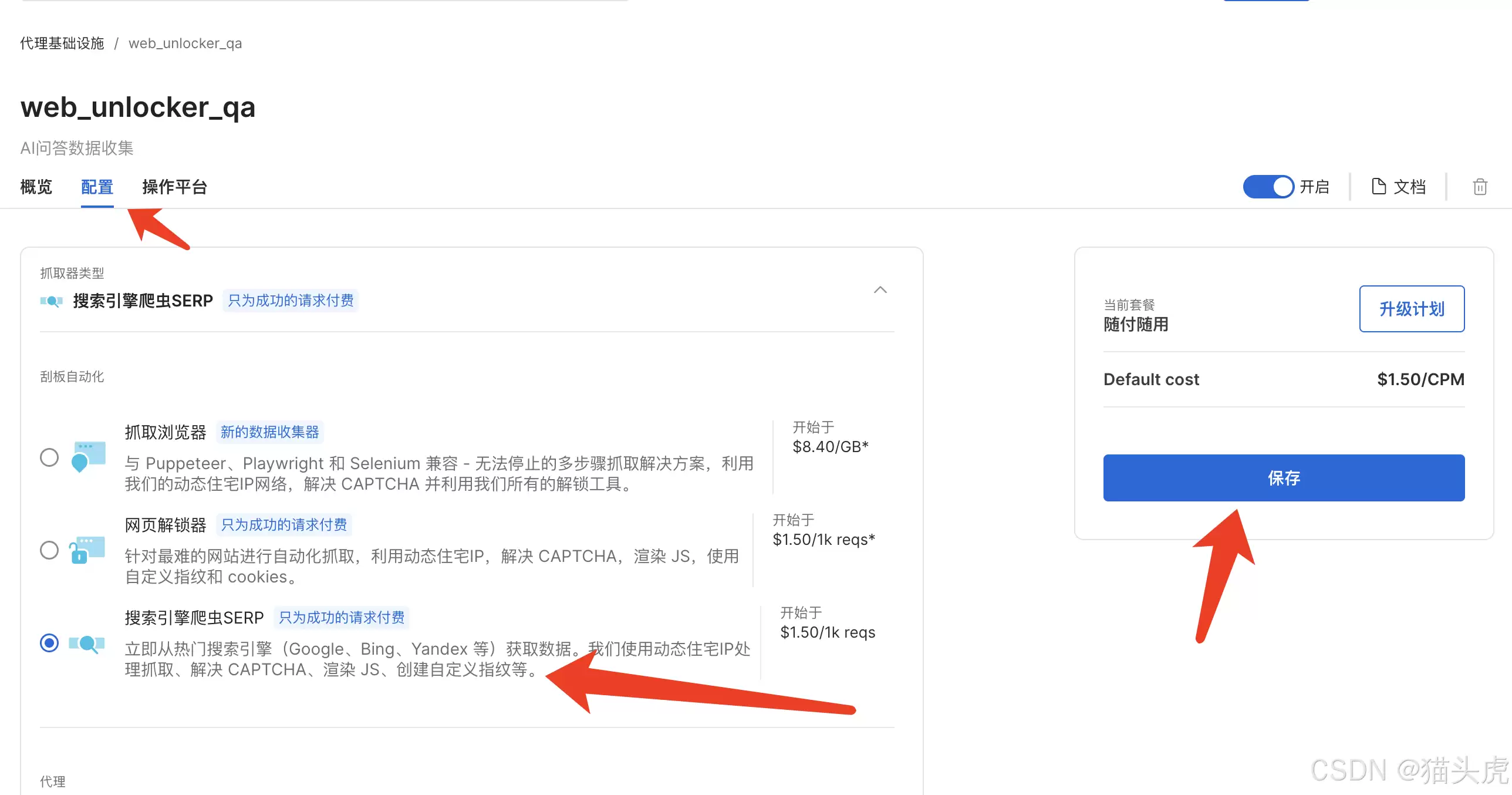
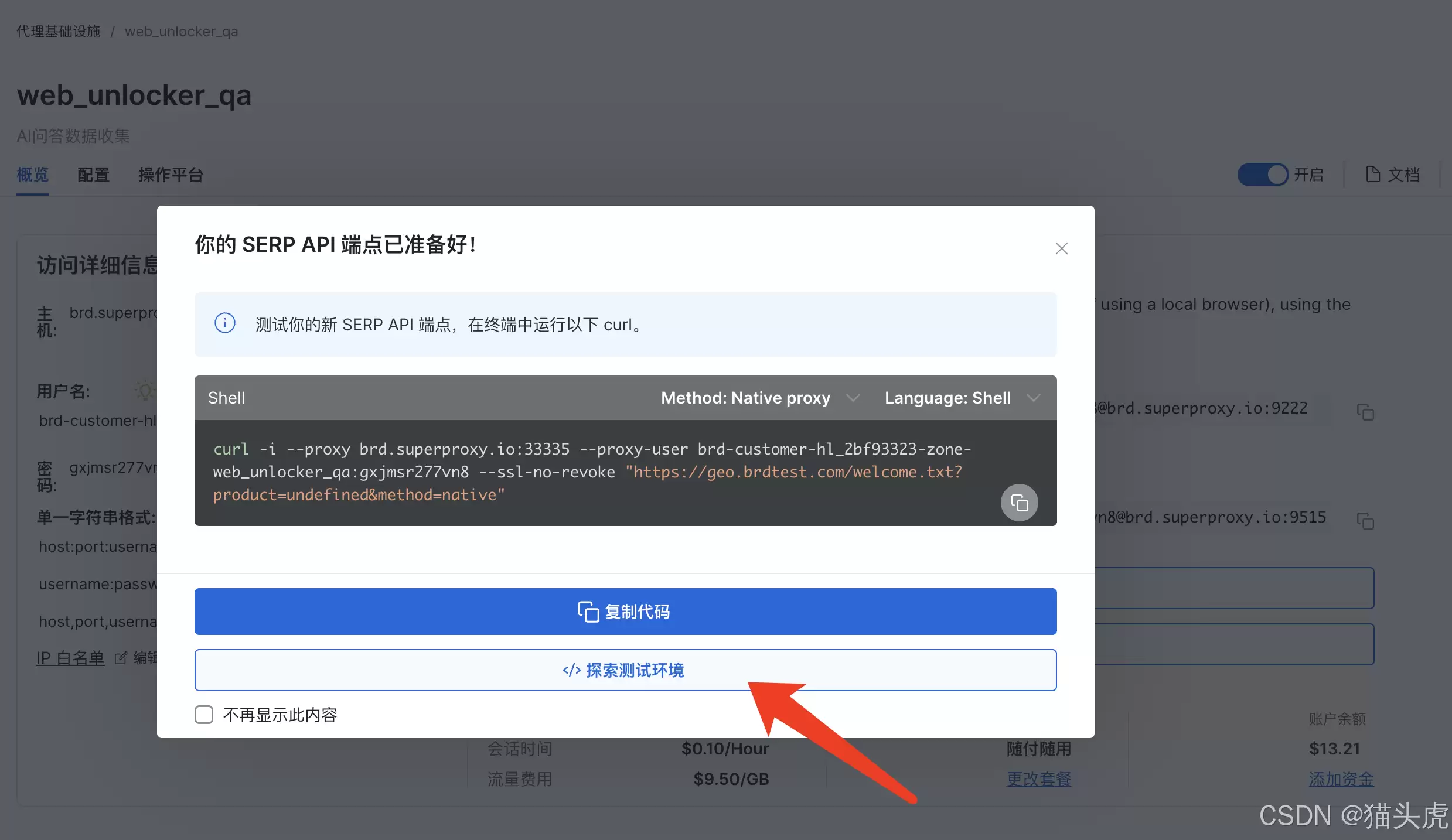
进入测试页后:
直接配置关键词搜索即可。比如我搜最近热门的MCP协议和A2A协议,秒出结果(网页和代码双视图):
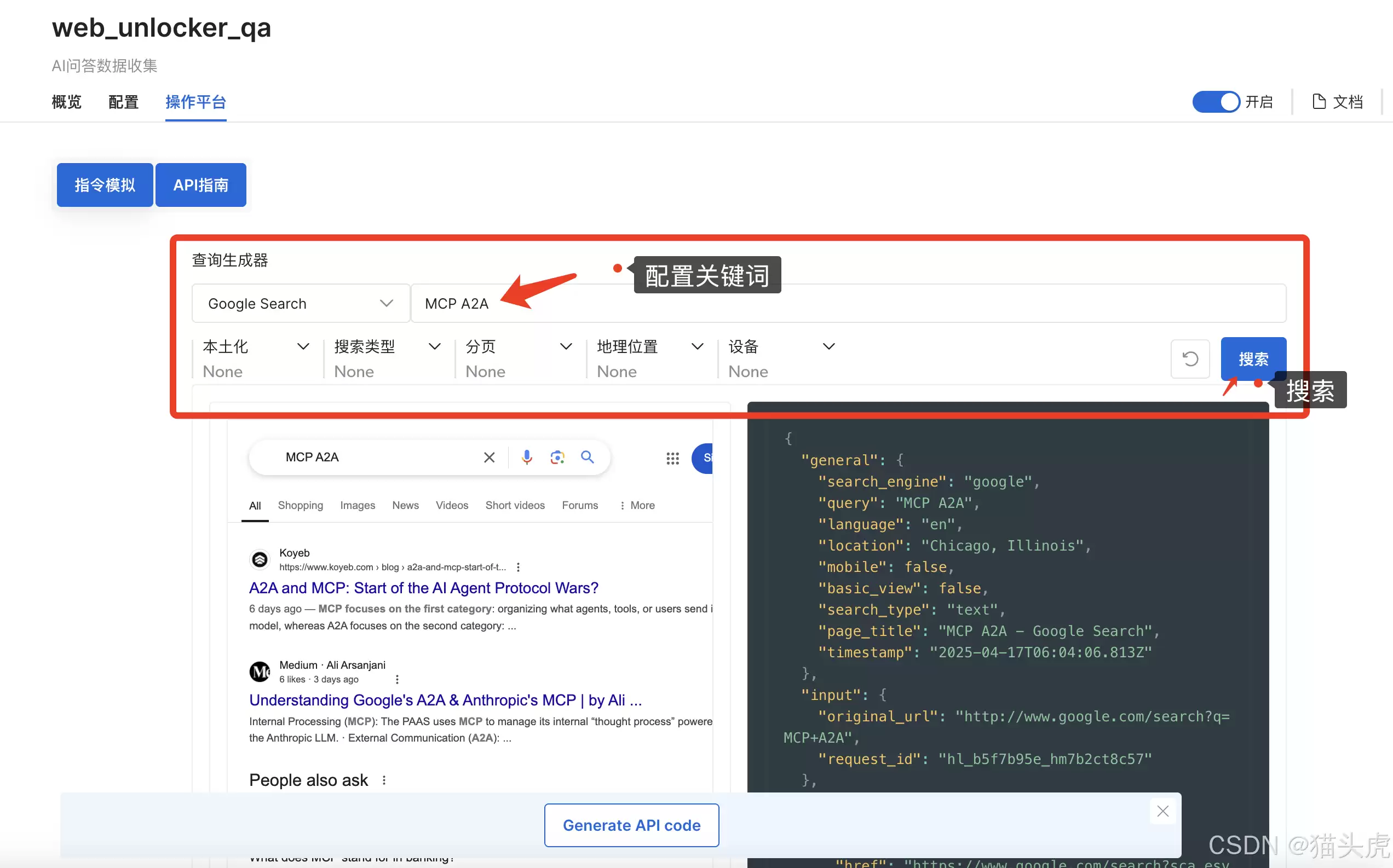
左侧还有多种查询器可以切换,按需调整即可。
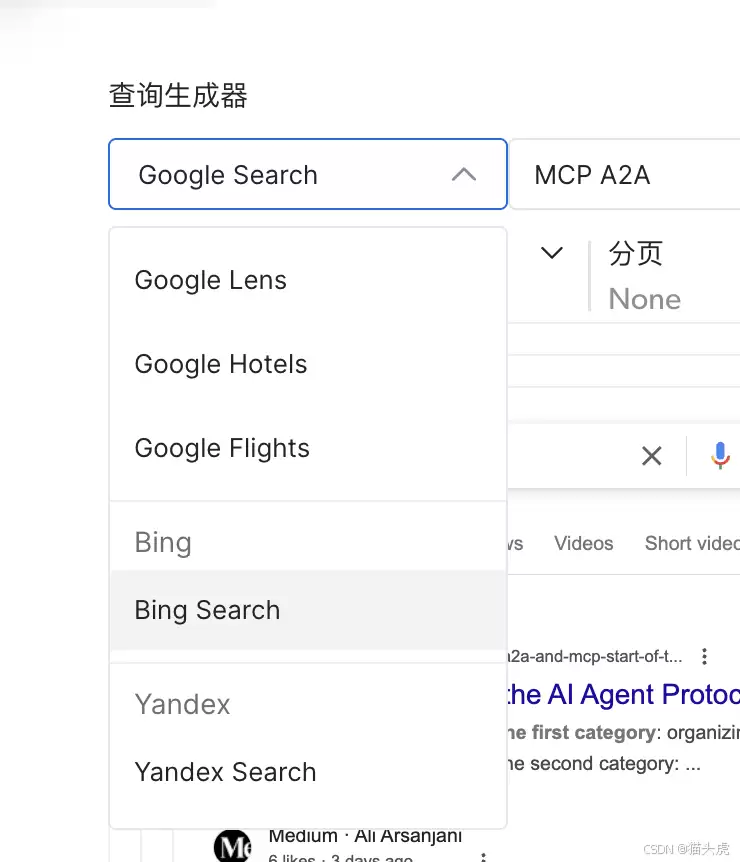
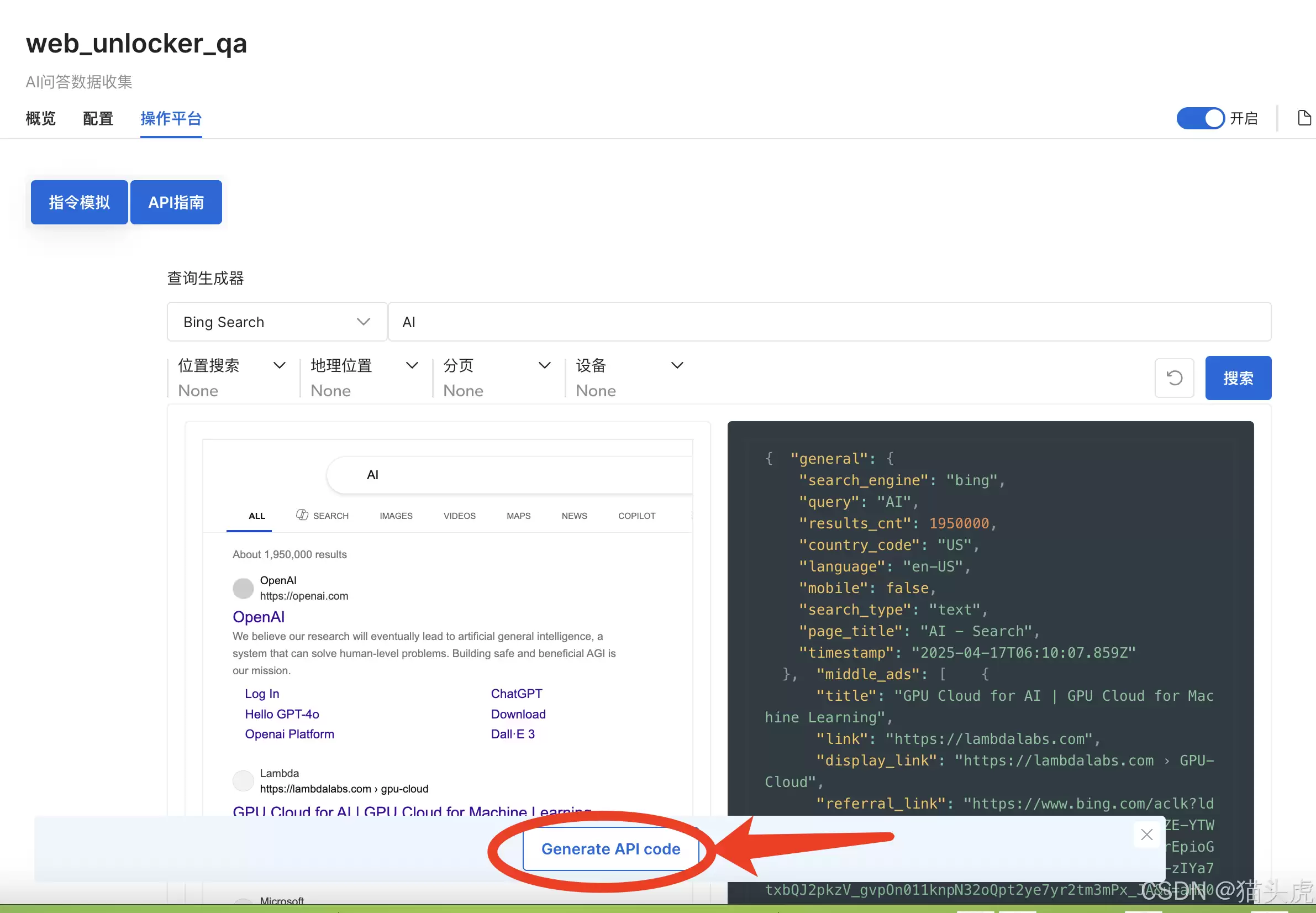
另外,SERP API支持在线调用和API方式。点击界面下方的“API代码”,就能生成可直接运行的多语言代码:
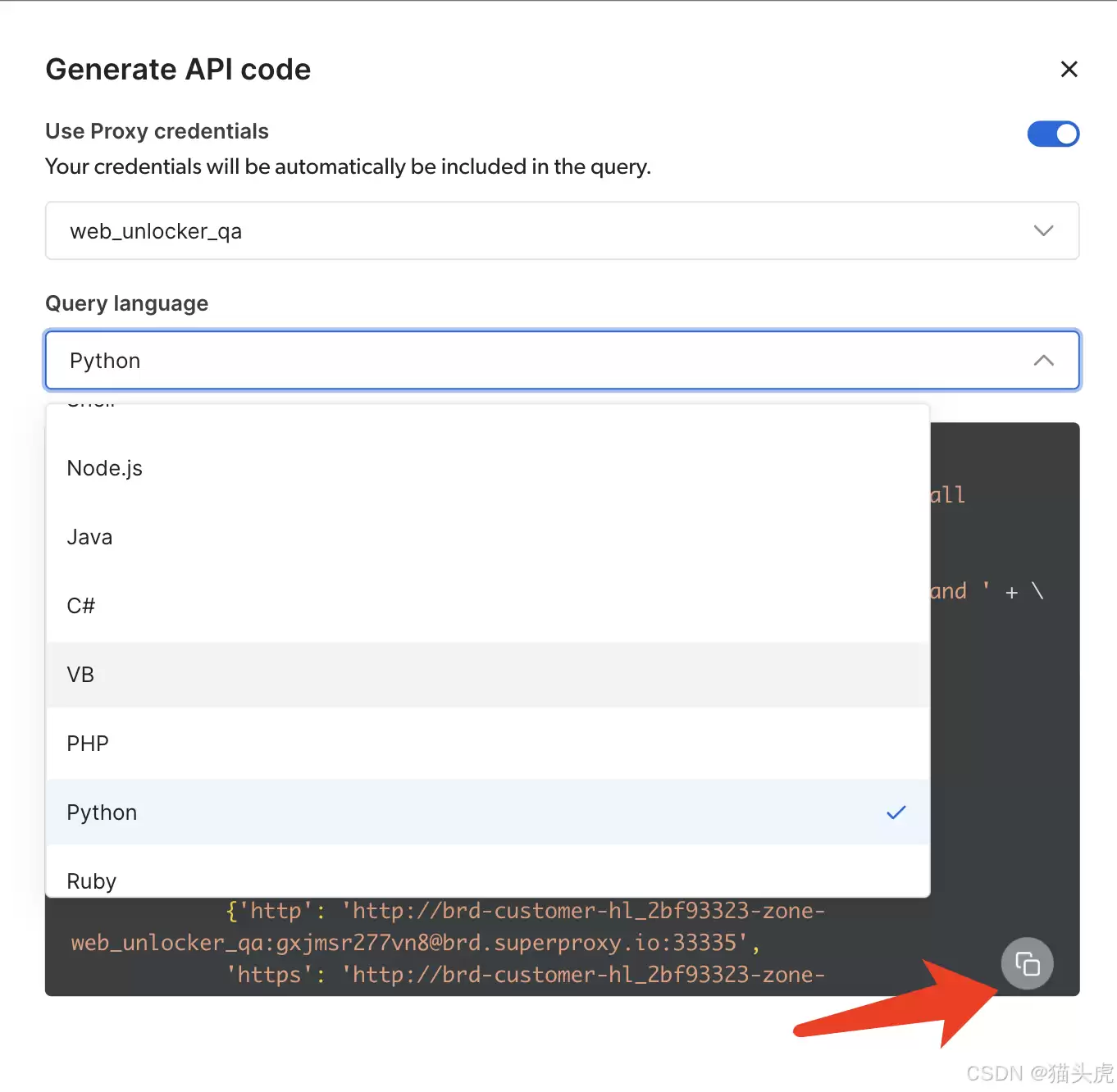
点击右下角菜单可快速复制到IDE运行:
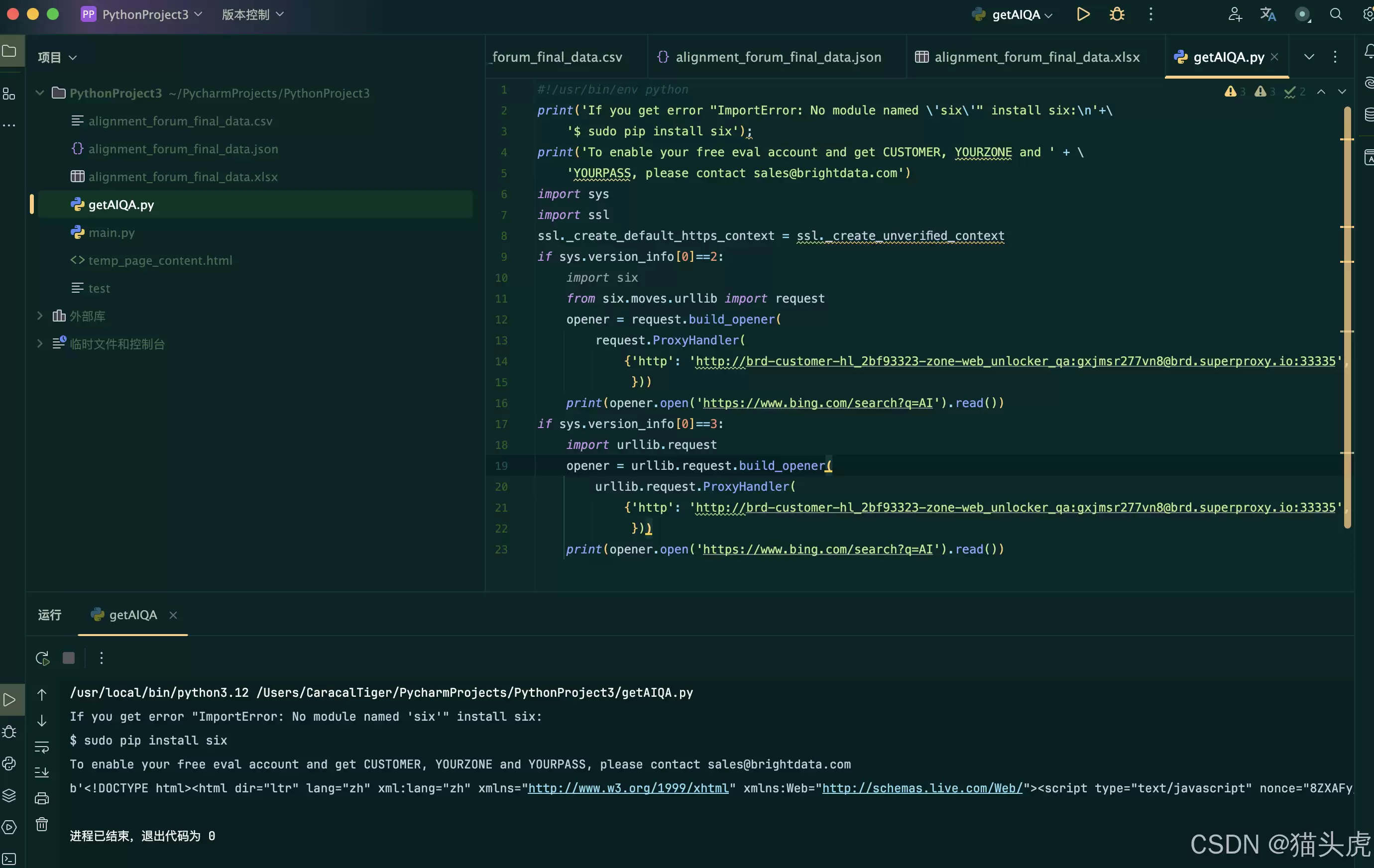
运行效果:
总结
这三个工具各有所长:
- Web Unlocker API:专治高防护网站,智能袋里+指纹伪装+验证码绕过,一步到位。
- Web Scraper:动态内容抓取利器,适合复杂页面和交互式数据采集。
- SERP API:搜索引擎结果结构化提取,SEO、竞品分析、知识库构建的必备组件。
它们共同的特点是把“踩坑”的活干了,让你直接拿到干净数据。无论你是做大模型微调、构建领域知识库,还是做市场研究,都能省下大把开发和维护成本。从入门到投产,流程清晰,投入产出比相当可观。




