【编者按】科学仪器被誉为科技创新的“眼睛”与“双手”,然而长期以来,高端仪器操作极度依赖人工经验,导致效率低下、标准化困难。5月21日,在未来光锥「AI for Science 创变者说」第二期沙龙“AI+材料的千亿级机会”上,北京科学智能研究院研究员张泽中分享了团队如何运用AI赋能科学仪器,布局智能仪器的“基础设施”。
今天我们来探讨AI如何赋能高端科学仪器。很多人认为仪器是前沿尖端的硬件设备,但在相当长一段时间里,其研发和使用方式其实非常传统。
举个例子,某位研究者博士期间的一个发现,可能是人类已知尺寸最小的“斑马”——左边那张图里,明暗相间的条纹仅有0.5纳米宽,看起来就像斑马的纹路。科学家不仅能观察到它,还能在空间和时间尺度上追踪它的生长过程及三维结构变化。科学仪器正是实现这一功能的工具——观测微观世界的“眼睛”。它曾给许多人带来惊喜。

但传统仪器理论还有另一面:从事其中的理论和计算,也充满了深深的孤独感。有一项研究前后耗费了五六年,研究者甚至为此写过一首诗:
⽉⼉寻榻下,影⼦对寒⼭。 温酒出⻓夜,倚柱看星残。
那是一个冷门到极致的科学问题——当电子以接近光速的速度撞击一个原子时,会导致原子轨道跃迁。在这个过程中,电子损失能量、激发到更高能态,然后跌落回来又会产生X射线。研究者整理了该领域的论文集,大约800页,然后一步步推导公式进行计算。不少同行都默默走过这样的路。
然而,因为AI for Science,今天这一切正在发生翻天覆地的变化。
AI for Science:中国科技史上最好的机遇
北京科学智能研究院倡导用AI真正改变科学研究的范式,其建设框架被称为“四梁N柱”:
四梁:
- 基于原理和数据驱动的模型、算法与软件;
- ⾼效率、⾼精度的实验表征⽅法(这部分由表征团队负责);
- 替代⽂献的数据库与知识库;
- ⾼度整合的算⼒平台。
N柱:支撑N个国家的战略需求——包括材料、能源、航天等。
为什么要强调“最好的机遇”?纵观科学仪器发展史,可以简化地看:
过去:硬件追赶期,软件不受重视,数据积累缓慢。
现在:硬件取得突破(比如电镜、质谱),软件能执行简单工作流,但数据仍碎片化,算法迭代以半年或一年为周期。
未来:硬件设计更智能,软件能智能决策,数据实时闭环,模型持续迭代——仪器将越用越聪明。
这里面每一件事的落地都是巨大的机会,同时也是中国仪器突破发展的重大挑战。
AI做仪器是个系统工程,要“一杆子捅到底”
从AI赋能仪器的学科内涵上看,目标很清晰:实现高效率 + 高精度。
高效率 = 自动执行 + 智能决策。
高精度 = 打通原理、算法和模型。
有了高精度,就能更准确地反馈;有了高效率,就能产生海量数据,反哺算法模型,形成良性循环。

需要明确一点:AI做科学仪器不仅仅是算法上的事情——不是说开发了什么模型,仪器的问题就解决了。它是一个系统工程:最底层是硬件接口——代码能不能直接控制仪器?还是只能用鼠标手动点击?在此基础上,构建系统能力:识别、测量、决策执行、仿真模拟、定量反演、AI Ready数据库、领域知识库;最后在应用层结合领域知识和仪器功能,实现各种智能化应用。
只有代码能控制仪器了,才能在这个基础上构建系统能力。目前,团队已经用AI覆盖了双束电镜、SEM/TEM/STM、XAS等工作,同时其他同事也在做核磁、质谱、XRD等工作。
具体来说说已落地的仪器。
智能双束电镜:从“因人而异”到“标准化”
先说双束电镜。这种仪器很有意思,它既有电子束(如同眼睛,用于观察),又有离子束(如同手,用于操作)。也就是说,你有了眼睛也有手,可以在微纳尺度上“雕刻”。这对半导体研发至关重要——切出各种样品来观察。
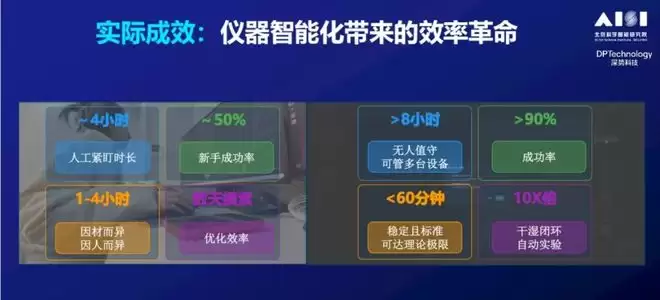
但传统方式下,人得蹲在仪器旁边1-4个小时不停操作。每一步做完,立刻要画下一个框、移动到下一个区域,几乎不能走开。在半导体厂里,这样的工作需要24小时三班倒,不同人手艺不同,做出来的样品质量和效率天差地别。当行业要求标准化和高通量时,这就是人力的卡点。
团队联合北京大学赵晓旭老师课题组和深势科技,开发了中国首套智能双束电镜系统。你只需要选定初始坐标、可视化调整加工区域,剩下的所有步骤——挖坑、切沟道、让薄片半悬空、用纳米机械手粘住、拎起来、转移到载网、减薄——全部自动化进行。
把一个“因人而异、成功率不定、时间不定”的事情,变成了标准化的、高通量的流程。当前正在攻克的是,面对变化万千的材料样品时,如何实现更高的稳定性和泛化性。
从预设工作流到自主构建工作流
除了双束电镜,在扫描电镜(SEM)和透射电镜(TEM)上也实现了智能化。比如在北京大学的一台电镜上,通过自然语言描述,它可以自动执行拍摄任务。仪器可以整晚运行,学生去休息,数据还在源源不断产生。过程中会实时定量分析、分割、拼接,早上过来直接收报告。此外,在进行原子级表征时,有很多环境造成的扰动,现在这些扰动可以被识别并矫正,目前已在多个模态上实现。
前面几个工作,大多需要花大量时间预先写好工作流。但最新进展是——让仪器可以自主构建工作流,并自主执行。这样一来,仪器就真的有了一个“脑子”,而不是你说什么它才做什么。
比如切割芯片的过程,可以通过对话实时生成,而不是提前写好的。同样的工作在STM(扫描隧道显微镜)上,与北京量子院合作,用于更智能地探索量子缺陷,效果很好。
数据引擎:解决科研数据“沉睡”的问题
数据层面,有一个严重的问题:不同仪器、不同厂商的数据格式五花八门;学生毕业了,数据存在某个文件夹里,老师都找不到。大量科研数据沉睡在各自的硬盘上,没有发挥价值。
团队正在做一个数据引擎,把各种模态的科研数据变成AI-Ready的。它遵循FAIR原则:
Findable(可被找到)
Accessible(可被访问)
Interoperable(可被解读)
Reusable(可被重新使用)
同时,这套系统可以离线部署,不离开你的电脑,只有确定要发布时才会发布,保证隐私安全;它会用AI做训练,原本需要厂商专用软件才能打开的数据,可以直接读取,送到GPU里。目前支持20多个领域、400多种数据格式。团队近期在紧密开发,希望未来能开源。
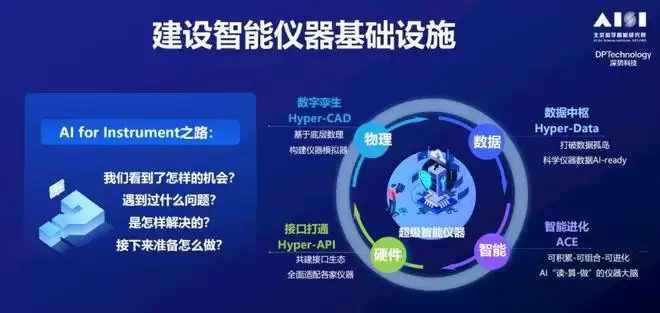
综合来看,团队在做智能仪器的“基础设施”——底层接口打通、数据孪生、数据中枢、仪器大脑。这些都是解决实际问题过程中形成的一系列工作。
团队还请AI画了一张它认为的未来仪器应该长什么样。图上提到几个关键词:多模态分析、AI自动化、更高效执行、更好分辨率、可云端与合作伙伴耦合。
很喜欢《三体》里章北海的一句话:“成吉思汗的骑兵的攻击速度和20世纪的装甲部队差不多,北宋的弩床跟20世纪的狙击步枪差不多。”这些兵器在刚出现时,速度可能相差不大。但它们的原理完全不同。骑兵用再好的汗血宝马也有上限,而装甲部队的上限要高得多。
相信未来的史学家回看我们现在这个时代,也会得出类似的结论——基础理论决定了一切。
互动提问
Q1:10年之后的材料实验室长什么样?
张泽中:现在可以看到,无论国内还是国际上,都在推进智能实验室的工作。很大程度上是受了人力瓶颈的影响——实验室里很多工作是重复性的劳动,有巨大改善空间。
期望的未来仪器:一定是有利于智能化操作的。这和现在不一样——过去,仪器是为人使用而设计的;未来,可能得面向方便AI使用、方便机器人使用而设计。这个机器人不一定是长得像人的机器人。就好像工厂里面最擅长做装配的不是人形机器人,而是更多的、工业的、专业的机器人——它可以远超人类的效率去做对应的事情。
Q2:你说的AI仪器系统从“预设的工作流”走向“自主进化”,现在进展到什么程度?是AI自己调参数,还是能自己发现新的实验方法?
张泽中:现在好比建一个楼——先要打地基。团队目前处于打地基的状态。打了一部分地基以后,一楼的小卖部可以开张了。只是小卖部——还没有说自己能发现新方法。当地基打好了以后,是有可能做这件事情的。
Q3:系统在做决定时,主要靠科研人员的经验规则,还是学习背后的物理规律?
张泽中:它需要基于现有知识的基础上去学习规则——这两个不是互相矛盾的,而是前后关系。已经知道的物理规律,没必要在一个仪器上再学一遍。
需要把已知的物理、已知的仪器操作放进去的基础上,让AI去动态构建仪器操作——先验证从简单操作开始,一步一步到更复杂的操作。
Q4:计算物理会不会很快就把所有可能性都算完了?那计算和实验接轨的未来,在实践时间线上、真正推动工业的步伐会怎样?
张泽中:这个行业AI怎么做科学,从大的板块来说是三个:读(文献)、算(计算)、做(实验)。行业内很多人认为:前面两个会在有限的几年内全部穷尽。
做实验是很难的——它自身周期就很慢,里面有很多脏活累活得去解决。就算解决了,周期也是一个自然周期——不是你全部丢到计算机就可以解决的。
“做”肯定是这三个板块最后能实现的,但也是最重要的——往往是要靠“做”出来一个东西(比如一个新材料、一个新仪器、一种新的合成制备、一个药),这时候大家才认为AI干出了一个落地的东西。
但前两个(读和算)其实是在做大量的筛选:使得我们不是在实验上用很昂贵的方法去无限穷举或炒菜。本次沙龙的子恒老师、刘淼老师,包括研究院,都是从计算上先从大海里捞出一批“针”——再去验证这些针是不是真有用。
测试针是否有用的过程——这部分当然也在被变得更高效、更智能。但前半部分的工作是非常有必要的。
作者简介
张泽中,北京科学智能研究院研究员,表征负责人,沉迷于用AI“点亮”科学仪器,日常在散射物理、材料表征、智能仪器之间反复横跳。带领一群跨领域跨组织的小伙伴,搞出了国内首套智能双束电镜系统HyperFIB。目前正忙着给SEM、TEM、STM、AFM一个个装上AI“大脑”。曾经建过一个相对论的电子能量损失谱数据库,以及在研究铝合金时,发现了全新的相变和界面——科研的惊喜,有时就是这么猝不及防。




