自然语言直接生成数据库查询(Text-to-SQL)这一方向近年来持续受到关注,但真正落地到商业智能(BI)实际场景时,传统NL2SQL技术的局限便暴露无遗:数据表动辄包含上百个字段,列名定义模糊不清,用户提出的问题往往嵌套多层计算逻辑。为此,百度联合北京邮电大学近日发布了一篇论文,提出了一套名为ChatBI的解决方案,专门攻克这些复杂场景下的难题。
论文原文链接:https://arxiv.org/abs/2405.00527
简而言之,ChatBI是一套面向商业智能场景深度定制的自然语言处理技术。它并不满足于简单的“一问一答”交互,而是综合运用了多轮对话匹配、单视图选择,以及一套颇具特色的分阶段处理流程。这一组合拳的明确目标是:解决大规模数据表结构复杂、语义模糊等带来的核心挑战。
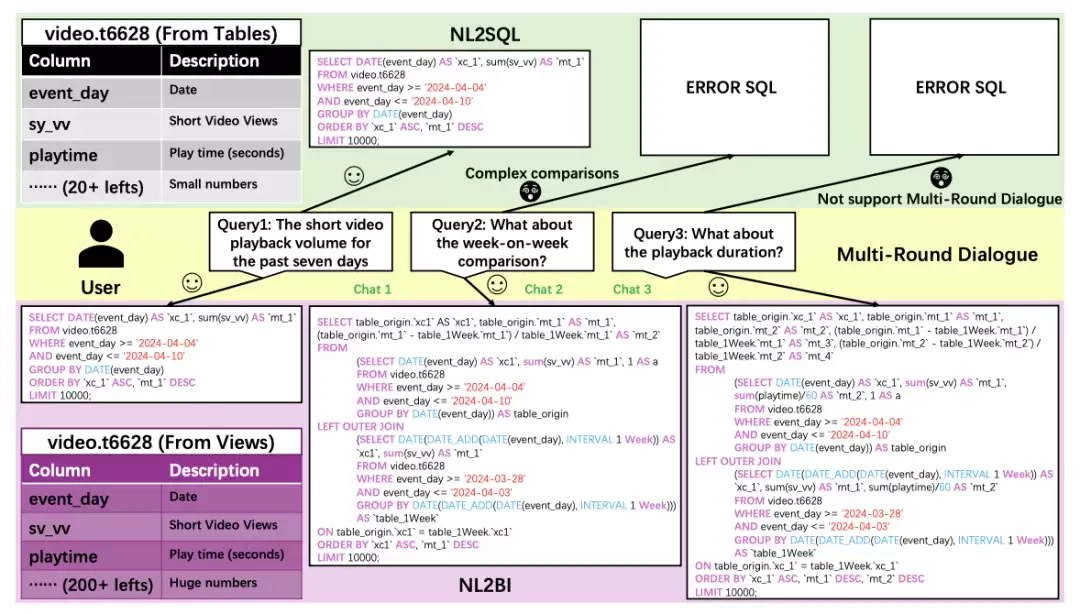
其多轮对话匹配模块,核心任务在于准确理解用户连续交互中的上下文语境。这一点在BI场景中尤为关键——用户通常围绕一个分析主题反复追问、修正思路、逐步深入,系统必须能够连贯承接这些对话上下文,确保每次生成的SQL都精准匹配用户心中那条分析主线。同时,单视图选择技术有效解决了实际问题:数据库中存在大量视图,到底应该查询哪一个?ChatBI将繁琐的模式链接(schema linking)问题简化为单选任务,显著节省了计算资源,也大幅缩短了响应时间。
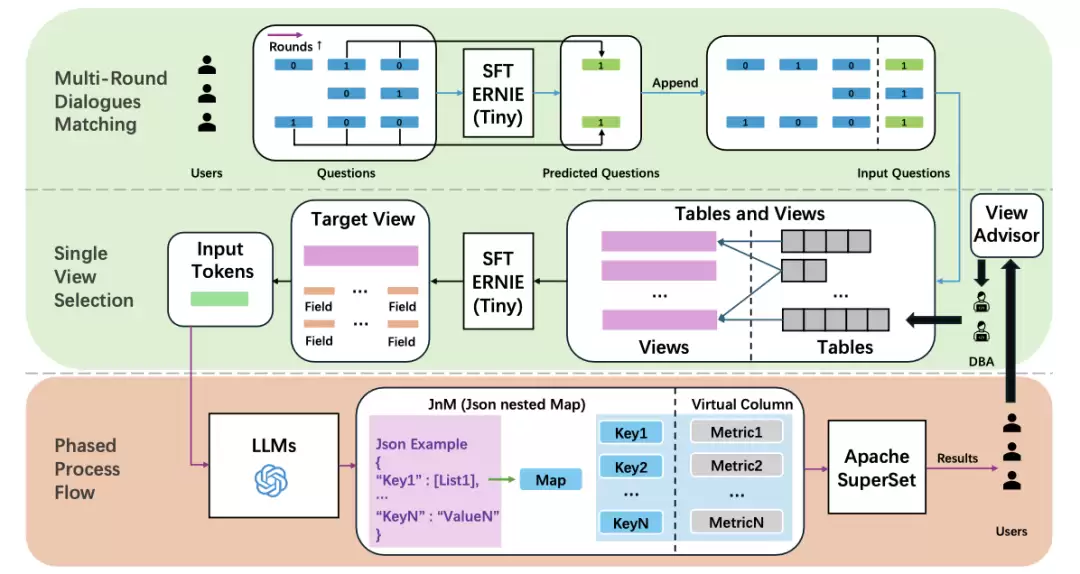
整个处理流程大致如下:系统首先借助大型语言模型生成一个中间JSON数据格式——这一步相当于把自然语言先转化为结构化的“草稿”,随后再通过规则化的方法精准生成最终SQL语句。这种两步走策略非常巧妙,既降低了大模型直接编写复杂SQL的难度,也增强了对复杂查询的兜底能力。实际运行结果表明,ChatBI在列数量多、计算关系错综的商业智能场景中,确实展现出了良好的实用性、通用性和处理效率。
值得一提的是,整个流程无需使用者成为数据库专家。ChatBI的设计初衷之一,就是让非专业用户也能通过自然语言轻松完成复杂的数据检索与分析工作。三项核心技术——多轮对话、视图选择、分阶段处理——共同构建了一个完整的处理闭环。
从另一个角度来看,ChatBI实际上也推动了NL2SQL领域一些长期存在的难题的解决。例如,它通过小型化模型降低了模式匹配的计算开销,又利用分阶段流程缓解了语义理解上的瓶颈。这些尝试并非仅仅为了论文中的实验指标,而是经过真实生产环境打磨验证的成果。
总体而言,ChatBI在商业智能与自然语言交互之间架起了一座更加顺畅的桥梁。它所解决的不仅是技术实现层面的问题,更是非专业用户面对复杂数据时的高使用门槛。随着此类技术的不断成熟,未来商业智能工具中的“智能性”很可能就体现在:用户随口一句自然语言,系统就能立刻给出精准的分析结果——这才是看得见的实质性进步。
论文核心解读
这篇论文正式提出ChatBI技术,面向的任务是将自然语言转换为商业智能SQL查询(NL2BI)。全文要点可概括如下:
摘要:ChatBI旨在解决实际生产系统中NL2BI的痛点——传统NL2SQL在交互方式、大量列的表、模糊列名等场景下频繁出错。ChatBI通过成本更低的小型模型、单视图选择技术以及分阶段处理流程,显著提升了复杂SQL生成的准确性和执行效率。
引言:论文指出了大型语言模型(LLMs)在NL2SQL领域的潜力,同时强调NL2BI作为其实践场景所面临的独特挑战:交互模式差异、表中列数过多、列名含义不清晰。
系统概述:ChatBI包含三个核心模块——多轮对话匹配、单视图选择、分阶段处理,形成从问题输入到SQL生成的完整链路。
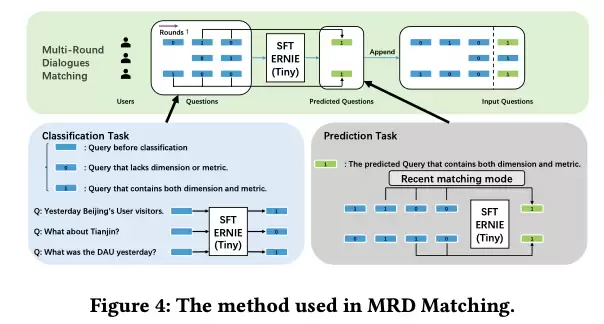
多轮对话匹配:强调在BI场景中处理多轮对话的必要性,采用Bert类小型模型进行上下文匹配。
单视图选择:将复杂的模式链接问题简化为对单一视图的选择任务,由小型机器学习模型完成。
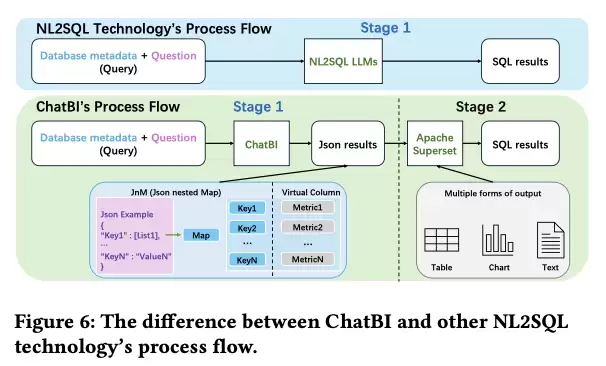
分阶段处理流程:核心流程是先让LLM生成JSON格式的中间输出,再在此基础上通过BI中间件(如Apache SuperSet)生成最终SQL。
实验评估:通过与现有NL2SQL方案的对比,展示ChatBI在准确性和效率上的优势。
结论:总结了ChatBI在真实生产系统中的部署效果与主要技术贡献。