在企业日常运营中,数据散落在 Excel 报表、MySQL、PostgreSQL 等各类存储中已是常态。业务人员提出“华东区上季度销量环比增长超过 10% 的门店”“检验合格的都是哪些公司的什么产品”这类问题时,传统路径往往绕不开这个流程:提需求 → 数据工程师写 SQL/Python → 排期开发 → 交付验证。一次看似简单的查询,耗时数小时甚至数天是家常便饭,数据团队也深陷在重复取数的低效循环里。
这背后是什么逻辑?说白了,数据量在爆炸式增长,但数据获取的门槛并没有同步降低。
针对结构化数据问答场景,澜舟智能体问数技术提供了一套 NL2Python(面向 Excel)和 NL2SQL(面向数据库)的双引擎方案。这篇文章打算从技术架构、评测方法、效果数据、典型错误分析这四个维度,把整套方案的设计思路与落地效果完整地摊开来聊一聊。
技术架构总览
澜舟问数系统分为两条技术路线,但底层共享同一个设计哲学:把不确定性降到最低。通过 Schema 校验、元数据增强、模板召回、自验证循环等一系列机制,把自然语言天然的歧义性逐层收窄,最终输出可执行、可复现的代码与结果。
ExcelQA(NL2Python):让 Excel 分析自动化
五阶段工程化流程
下图展示了 Excel 问答的五个处理阶段:

阶段一:文件入口与合法性检查
用户上传 Excel 后,预处理模块先把文件流转为内存对象,然后用预设的 Excel Schema 进行校验:列名是否匹配、数据类型是否合规、必填字段是否存在、值域范围是否合法。只要任一条件不满足,系统立刻返回明确的“文件不合法”提示,避免无效计算进入后续环节。合规的文件则被提取出表、列、值等元数据并持久化存储。
阶段二:自然语言需求捕获
系统把 Prompt 模板、用户自然语言问题以及阶段一产出的元数据一并送入 LLM。LLM 在这里扮演“需求翻译官”——把口语化提问(比如“找出销量环比增长超过 10% 的门店”)转化为结构化的、带字段名与计算逻辑的形式化描述。
阶段三:NL2Python 代码生成
形式化描述传入 NL2Python 模块,一次性生成可执行的 Python 脚本。工程约束如下:代码必须自包含、可重入;所有依赖(pandas、numpy、openpyxl 等)在隔离容器中预装;代码头部自动注入 Excel 文件路径与结果输出路径,真正实现“开箱即跑”。
阶段四:执行与结果回收
生成的 Python 代码通过 exec() 在沙箱中执行。成功时,标准输出与序列化结果(CSV/JSON)被捕获;失败时,系统捕获报错信息,重新生成代码。
阶段五:答案生成与可视化
执行结果与用户原问题再次送入 LLM,映射为最终的自然语言答案。同时,系统支持将结果表格自动渲染为图表(折线图、柱状图、饼图等)。
评测方法
数据集:共 600 条内建测试数据,包含 300 条简单问题和 300 条困难问题。
评估标准:采用 LLM 四分量表打分(0-3 分),以 score ≥ 2 视为正确。
- 3 分:回答完全正确,语义与内容高度一致。日期字段需换算为日期格式后比较。
- 2 分:基本正确,语义一致但表达或细节有差异;或结果为标准答案的子集。
- 1 分:部分正确,存在明显错误或遗漏重要信息。
- 0 分:完全错误。
当前效果

DatabaseQA(NL2SQL):让数据库查询像对话一样自然
四大阶段 + 亮点能力
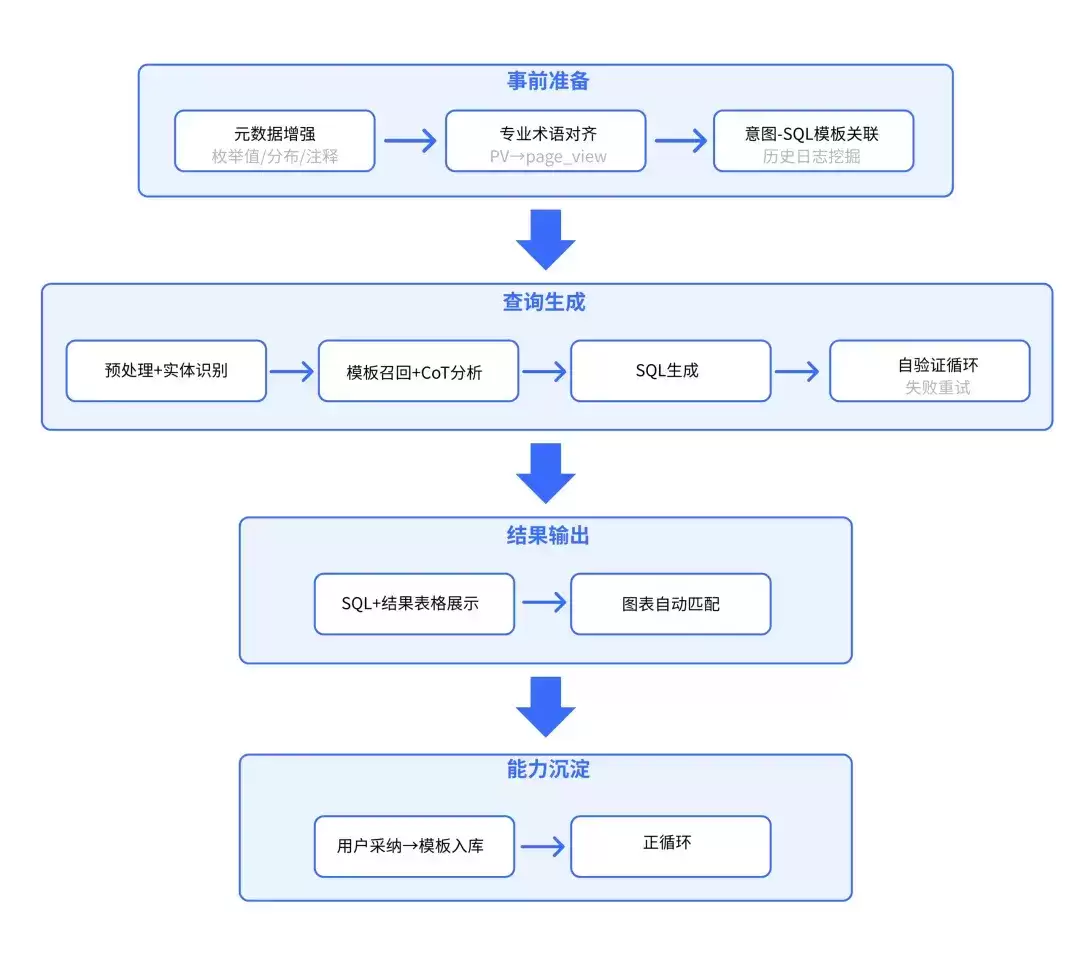
亮点能力说明
- 元数据增强:对 MySQL 等数据库运行 m-schema 解析,自动抽取字段枚举值、取值分布、业务注释,生成一张“表扩展信息库”。相当于给每张表配了一份“活字典”——字段别名、业务含义、枚举值、样例数据四件套,显著降低 LLM 幻觉。
- 专业术语对齐:维护行业术语库(同义词、缩写、中英文映射)。用户问“PV”自动改写成 page_view,“销售额”对齐 GMU。
- 意图-SQL 模板关联:离线挖掘历史日志,建立“意图标签 → SQL 模板”映射。线上召回 1~3 条高相关模板,让 LLM 先“抄作业”再“做题”。
- 自验证循环:执行失败 → 自动捕获错误码/报错信息 → Prompt 中追加“错误原因” → LLM 重新生成。
- 图表可视化:根据字段类型自动匹配渲染策略——时间 + 数值→折线图;分类 + 数值→柱状图/饼图;地理字段→地图。
- 模板沉淀正循环:用户点击“答案正确/采纳”时,系统将“标准化问题 + 最终 SQL”沉淀到模板库,后续优先召回高频、高评分模板。
评测方法
数据集:Falcon(源自论文 https://arxiv.org/pdf/2510.24762 的 dev 数据集),包含 28 个数据集、90 张表,共 500 道中文题目(dev 集合中带 ground truth 的 309 条)。
评估标准:同样采用 LLM 四分量表(0-3 分),score ≥ 2 视为正确。核心差异在于评分依据是结果表格而非自然语言答案:
- 3 分:结果表格与标准答案在行集合、列对应上完全等价(列名可不同,但每列取值一致);数值允许合理误差(如 4.514 vs 4.51)。
- 2 分:SQL 思路基本正确,结果大部分一致(如因未去重等因素导致的不同)。
- 1 分:部分正确(主要表或关键条件正确,但漏条件/多条件/聚合方式错误)。
- 0 分:完全不符。
当前效果(优化前后对比)

数据来源:内部评测,基于 Falcon dev 集合(309 条 ground truth)。ours 包含元数据增强、术语对齐、模板召回、CoT、自验证等完整 pipeline。
提升幅度:准确率(≥2 分)从 61.81% 提升至 90.29%(+ 28.48pp),平均得分从 1.825 提升至 2.6440(+ 0.8015)。
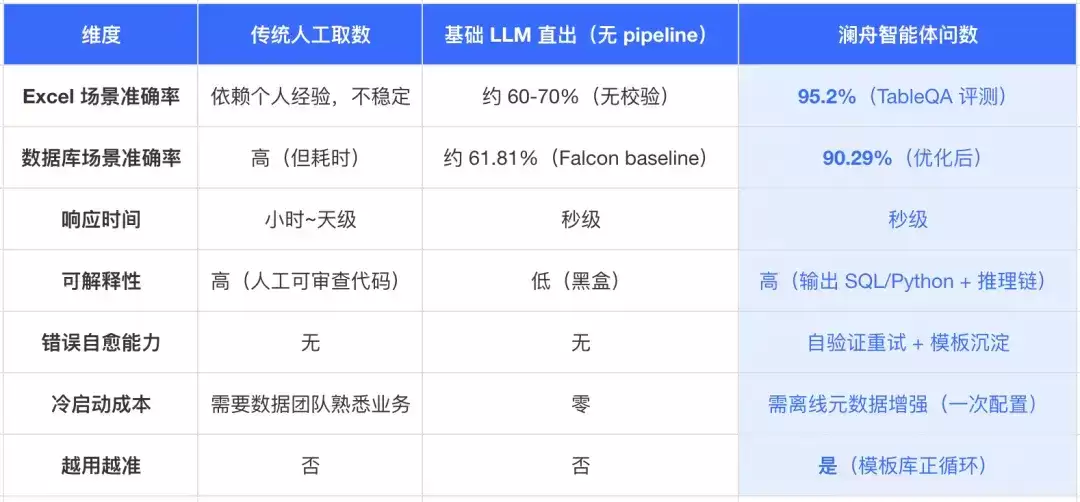
方案对比:澜舟 vs 传统人工取数 vs 基础 LLM 直出
可落地场景与技术适配要求
可落地场景
- 财务分析:月度利润表环比/同比自动计算,异常科目高亮
- 运营监控:DAU/MAU 趋势查询,渠道来源分布自动出图
- 供应链管理:库存周转天数超阈值门店过滤,多条件组合筛选
- 研发效能:各项目 Bug 解决时长分布,按负责人聚合统计
技术适配要求
- Excel 场景:表结构相对稳定(列名、类型可预先定义 Schema),单表行数建议 ≤ 100 万(受容器内存限制)
- 数据库场景:需提供只读账号,支持 MySQL 5.7+、PostgreSQL 10+;建议表注释、字段注释完整,以提升元数据增强效果
总结
澜舟智能体问数技术并非简单调用 LLM 生成代码,而是一套完整的工程化 pipeline——通过 Schema 校验、元数据增强、术语对齐、模板召回、CoT 推理、自验证循环、结果沉淀等机制,将自然语言问答的准确率从基础 LLM 的 60-70% 提升至 95%(Excel)和 90%(复杂数据库跨域场景)。更重要的是,它具备可解释(输出代码与推理链)、可进化(模板正循环)、可落地(沙箱执行,失败重试)的特性。这才是真正能拿来用的技术方案。




