一、先抄这张表:任务 × 档位决策速查
如果没时间读完,直接看这张表就够了。它基本覆盖了八成日常场景——找到你正在做的任务,照着调就行。
| 你在做的任务 | 模型 | 推理深度 | 加速模式 | 一句话理由 |
|---|---|---|---|---|
| 日常写代码(接口 / 表单 / 不难的 bug) | 主模型(gpt-5.5) | medium | 关 | 标准任务,主模型够用、能等就别烧 |
| 批量改文件(统一格式、批量替换) | 轻量 mini | low / minimal | 关 | 任务简单、跑量,省用量 |
| 跨文件复杂重构 | 主模型 | high | 关 | 要全局理解,长任务不指望加速 |
| 架构迁移 / 安全审计(最难) | 主模型 | xhigh | 关 | 错了代价大,质量优先 |
| 实时编辑器补全 | spark / mini | minimal / low | 开 | 要的是即时响应 |
| 只读探索 / 看陌生代码 | mini | low | 关(沙箱设只读) | 不写代码,别让它乱改 |
新手最容易在这两件事上吃亏:用最强模型跑批量改(白白烧用量),用快模型跑复杂重构(结果不行又得返工)。学会按任务难度调档,才是省用量的最大杠杆——核心原则是“按需分配”,而不是“永远调最高”。
不确定当前任务落在哪一行?用这三步判断:
- 先问难度:这件事是“机械重复 / 改格式 / 查一下”,还是“要跨多个文件理解后再动手”?前者往轻量挡走,后者往主模型 + 高推理走。
- 再问紧不紧:你会盯着屏幕等结果吗?会就考虑开加速,不会(后台跑 / 长任务)就关掉,省用量。
- 最后问代价:这件事改错了好不好回滚?好回滚的(有 git 检查点)大胆用低挡试,难回滚的(架构迁移、删数据)才值得上最贵的 xhigh。
下面把每个旋钮拆开讲,每节都给一张可以直接抄的对照表。
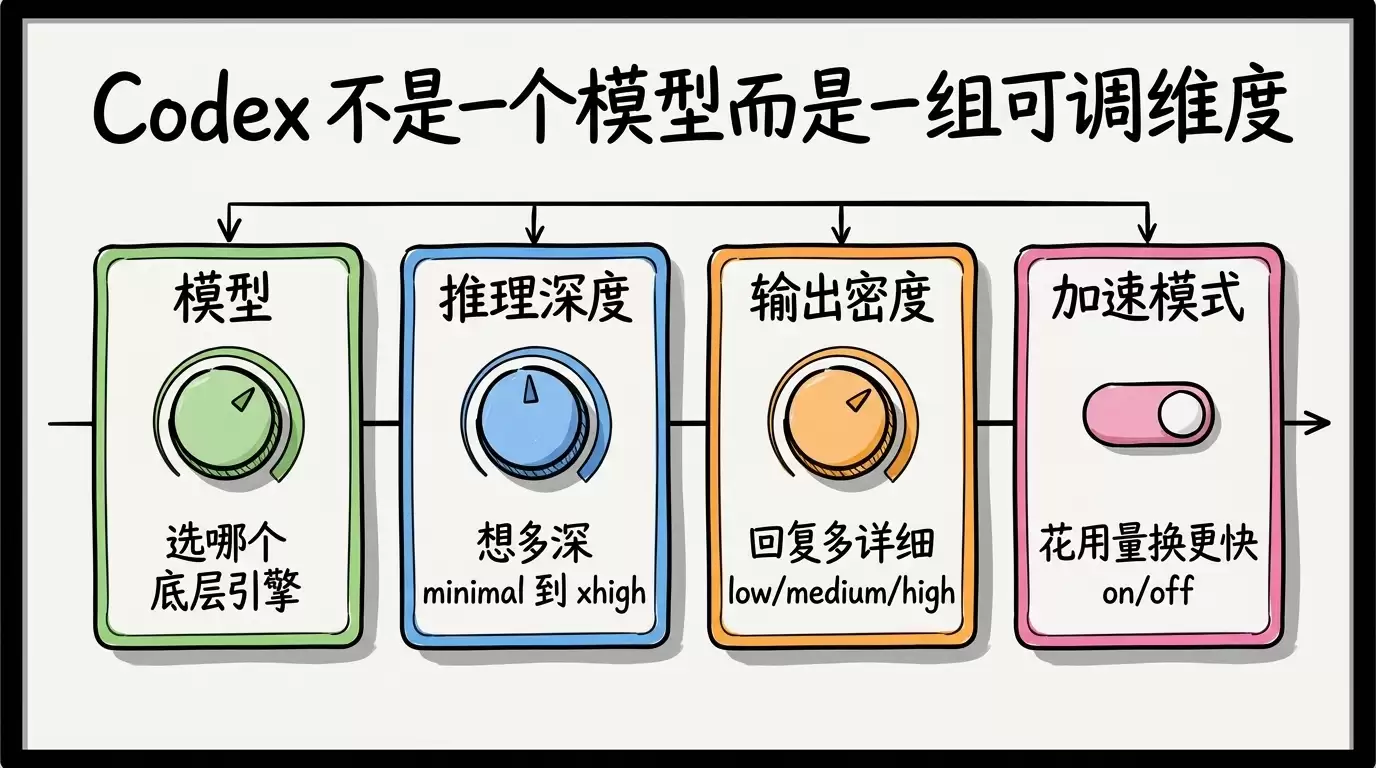
二、Codex 不是「一个模型」,是「一组旋钮」
Codex 设置页里那几个下拉菜单,本质上是把控制 AI 行为的几个维度分开交给你。核心有四个旋钮:
| 旋钮 | 管什么 | 主要影响 | 取值 |
|---|---|---|---|
| ① 模型(model) | 选哪个底层 AI 引擎 | 智能、速度、用量全维度 | gpt-5.5 / gpt-5.4 / mini / 编程专精 / spark |
| ② 推理深度(reasoning effort) | 模型内部「想多深」 | 主要影响质量与成本 | minimal / low / medium / high / xhigh |
| ③ 输出密度(verbosity) | 给你的回复写多详细 | 阅读体验 + 小幅输出成本 | low / medium / high |
| ④ 加速模式(Fast mode) | 花更多用量换更快响应 | 速度 ↑、用量消耗 ↑ | on / off(另有 flex 等服务档位) |
这四个旋钮是互相独立的——同一个模型可以配低推理 + 简短输出 + 不开加速,也可以配高推理 + 详尽输出 + 开加速。但新手不用记全部组合,只要记住第一节那张速查表里的几种典型搭配就够。
为什么 OpenAI 不直接做一个“智能档位”总开关?因为不同任务的最优解是互相矛盾的:
| 场景 | 目标 | 矛盾点 |
|---|---|---|
| 实时补全 | 速度 | 牺牲深度 |
| 复杂重构 | 质量 | 牺牲速度和成本 |
| 跑批改文件 | 省用量 | 牺牲单次智能 |
没有任何单一按钮能同时把速度、质量、成本都拉满——所以 Codex 把选择权交给你,按任务自己权衡。
三、模型(Model)怎么选:按定位选,不是按高低排
模型是四个旋钮里影响最大的一个。先说清楚一点:Codex 的几个模型不是一条从弱到强的直线,而是定位不同。下表是 OpenAI Codex 模型页给出的官方定位(按用途归类,不是按高低排序):
| 模型 | 官方定位 | 适合 |
|---|---|---|
| gpt-5.5 | 最新前沿模型,面向复杂编程、计算机操作、知识工作与研究型工作流 | 官方推荐的默认起点 |
| gpt-5.4 | 旗舰专业模型,把 gpt-5.3-codex 的编程能力与更强推理、工具调用、智能体工作流合一 | 专业复杂任务 |
| gpt-5.4-mini | 快速高效的轻量模型,面向需要快速响应的编程任务和子袋里 | 简单任务、批改、子袋里 |
| gpt-5.3-codex | 面向复杂软件工程的编程专精模型,其编程能力也支撑了 gpt-5.4 | 纯代码编写、Bug 修复 |
| gpt-5.3-codex-spark | 纯文本研究预览模型,为近乎即时的实时编程迭代优化 | 编辑器实时补全 |
3.1 新手默认:从官方推荐的最新前沿模型起步
OpenAI 模型页明确写了“多数 Codex 任务从 gpt-5.5 起步”(For most tasks in Codex, start with gpt-5.5)。先用最新前沿模型把活跑顺,跑顺了再按需要往 mini 省、往专精模型调。
很多新手会纠结“最新最强的不是最贵吗,为什么官方反而推荐先用它”。这里要分清两件事:单看一次请求,更强的模型确实可能更贵;但省不省用量看的是“把活做成”的总成本,不是单次成本。能力更强的模型往往一次就把任务做对,弱模型可能要反复试、来回返工,加起来未必更省。所以新手的正确顺序是“先用够强的把任务跑顺、建立判断,再针对简单任务往轻量挡省”——而不是一上来就为了省钱用最弱的模型,结果在返工上把省下的用量又赔进去。
# 命令行(CLI)模式:在 ~/.codex/config.toml 写
model = "gpt-5.5"
# 桌面应用(App)模式:在 Settings → Model 选最新主模型
3.2 什么时候该换轻量 mini
下面这些场景换 mini 系列更划算——官方对 mini 的定位就是“快速高效、面向快速响应的任务和子袋里”:
| 场景 | 为什么 mini 更合适 |
|---|---|
| 批量改文件(统一格式、批量替换) | 任务简单、跑量,智能不是瓶颈 |
| 简单自动补全 | 速度比智能更重要 |
| 子袋里做探索性扫描 | 子袋里只负责报告、不下决策 |
| 不重要的实验性脚本 | 出错代价低 |
| 当月用量吃紧、要省 | mini 输出成本是主模型的零头 |
切换最快的方法:CLI 里敲 /model,选 mini。
3.3 Spark:实时迭代专用
gpt-5.3-codex-spark 是研究预览模型,专为“近乎即时的实时编程迭代”设计。适合在编辑器里要 AI 即时回应、做局部小改;不适合跨文件重构、复杂逻辑设计、长会话深推理。新手第一周一般用不到,先用主模型跑顺。
3.4 模型 × 推理深度:组合矩阵
模型和推理深度是两个旋钮,真正决定一次任务表现的是它们的组合。下面这张矩阵把“模型档次 × 推理深度”拆开,标出每个交叉格典型用在哪、要注意什么。读这张表的方法:先按任务难度找行(轻量还是主模型),再按要不要深思找列。
| 模型\推理深度 | minimal / low | medium | high / xhigh |
|---|---|---|---|
| 轻量 mini | 批量改文件、机械补全、只读扫描 —— 最省用量的角落 | 简单到中等任务的省钱挡,质量够用就停在这 | 一般不这么配:mini 上 high 性价比不高,要深推理直接换主模型 |
| 主模型(gpt-5.5) | 主模型配低推理多用在“要主模型的知识但任务不难”的过渡场景 | 日常写代码的标准挡,多数任务的落点 | 复杂重构 high、架构迁移与安全审计 xhigh,质量优先、不在乎多花用量 |
两条用这张表的经验:
- 左上角最省、右下角最贵。同一件事能用左上角解决就别往右下角挪——这就是省用量的核心动作。
- 轻量模型 + 高推理这一格基本是浪费。要的是深推理就直接上主模型;mini 的价值在“快和省”,给它配 xhigh 等于既不够聪明又不省钱。
四、推理深度(Reasoning Effort)怎么调
推理深度是第二大影响力旋钮,决定模型“内部想多深”。
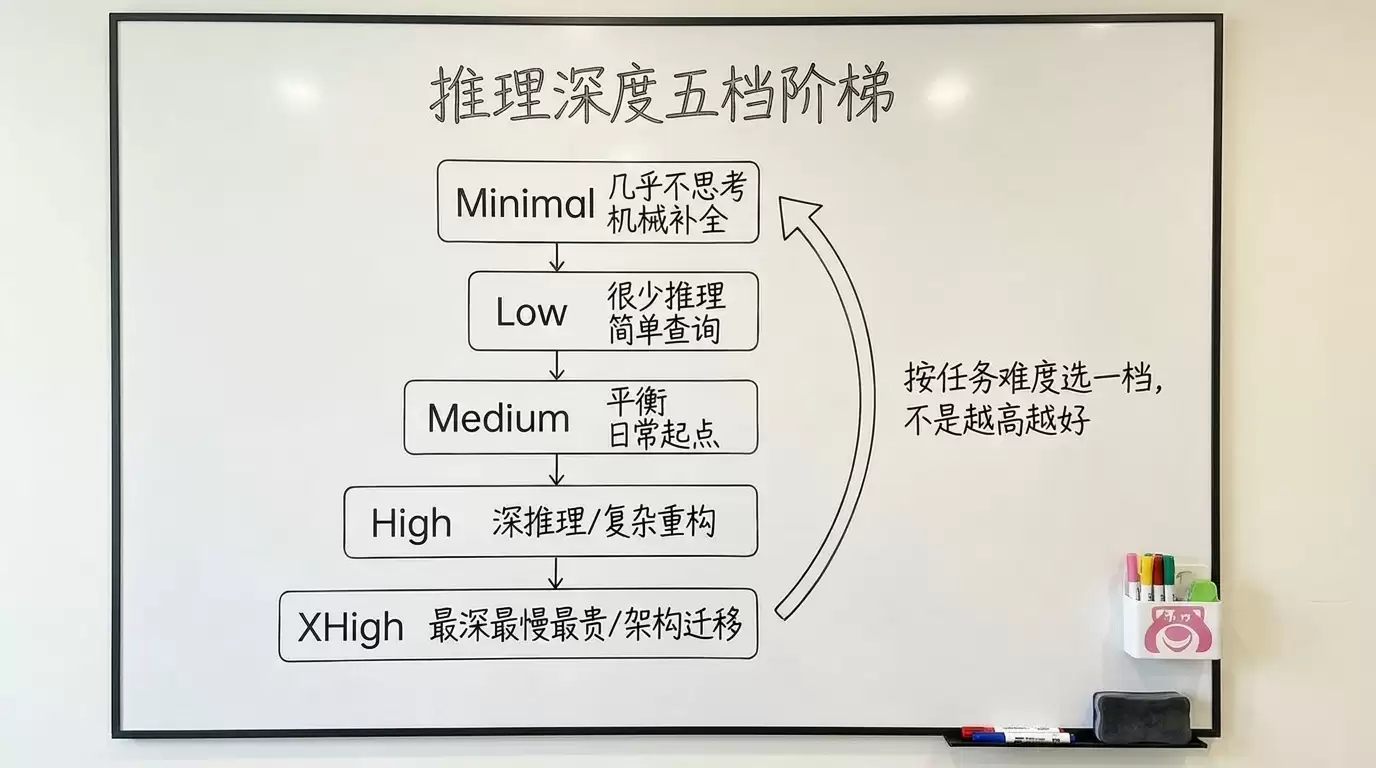
4.1 五档分别什么意思
按 OpenAI Codex 配置参考,model_reasoning_effort 的取值是 minimal | low | medium | high | xhigh 五档(注意:xhigh 是否可用取决于具体模型)。官方没有声明哪一档是默认值——所以下表只标用途,不标“默认”。
| 档位 | 意思 | 适合的任务 |
|---|---|---|
| minimal | 推理最浅、几乎不思考 | 纯格式化、机械补全 |
| low | 很少推理、快速直出 | 简单查询、增删改查(CRUD) |
| medium | 平衡推理与速度 | 多数日常编程任务(新手稳妥起点) |
| high | 深度推理、慢但质量好 | 复杂调试、跨文件重构、安全审计 |
| xhigh | 最深推理、最慢、最贵 | 大规模重构、跨框架迁移、最难的算法(受模型支持限制) |
4.2 按任务选档对照表
| 任务类型 | 推荐深度 | 理由 |
|---|---|---|
| 机械格式化 / 补全 | minimal / low | 不需要思考 |
| 简单查询 / CRUD 接口 | low / medium | 任务标准 |
| 调试已知模块的 bug | medium | 大多数 bug medium 能搞定 |
| 跨多文件并发 bug | high | 要追踪复杂状态 |
| 中等复杂度新功能 | medium | 标准任务 |
| 跨模块大规模重构 | high | 要全局理解 |
| 框架迁移 / 数据库迁移 | xhigh | 错了难回滚,质量优先 |
| 安全审计代码 | high / xhigh | 错过漏洞代价大 |
| 跑批 / 后台体力活 | minimal / low | 量大,要省 |
4.3 新手两个误区
误区一:默认就上 xhigh。 简单任务用 xhigh 不仅更慢更费用量,还可能因为“想太多”引入不必要的复杂度,结果反而不如 medium。OpenAI 文档对推理档位的建议是按任务难度选一档、自己测试在工作流里哪档最好,并强调不同用户、不同任务适合不同设置——没有“越高越好”这回事。
误区二:把推理深度当质量补救。 结果不行时,先查的应该是提示词和 AGENTS.md,而不是把 reasoning effort 一路拉高。下面是结果不达标时的排查顺序,调推理深度排在最后:
| 顺序 | 先查什么 | 怎么改 |
|---|---|---|
| 1 | 提示词是否含糊 | 把模糊需求写成明确的工程任务,参考提示词工程 |
| 2 | AGENTS.md 是否缺约束 | 补上项目规则、风格、禁区,参考 AGENTS.md 指南 |
| 3 | 上下文是否够 / 是否太杂 | 该补的文件没给、不相关的内容塞太多,都会拉低质量 |
| 4 | 模型选得对不对 | 复杂任务用了 mini,先换主模型再谈推理 |
| 5 | 最后才升推理深度 | 前面都对了仍不行,medium → high → xhigh 逐级试 |
前四步没排查就一路拉高推理深度,多数时候只是更慢更贵,质量并不会真正变好。
4.4 调推理深度的几种方式
# 方式一:CLI 一次性指定
codex -c 'model_reasoning_effort="high"' "重构这个模块"
# 方式二:写进 ~/.codex/config.toml 持久化
model_reasoning_effort = "high"
# 方式三:会话内切换
/reasoning high
CLI 与 IDE 扩展共用 config.toml,一次配置多端生效。
五、输出密度(Verbosity)和加速模式(Fast Mode)
第三、四个旋钮影响相对小,但用对了能省时间或省用量。
5.1 输出密度(Verbosity)
按 config-reference,model_verbosity 取值是 low | medium | high 三档;官方说明是“不设时使用所选模型或预设自带的默认”——同样没有把某一档钉死成默认。
| 档位 | 意思 | 适合场景 |
|---|---|---|
| low | 简洁、只给关键信息 | 已经熟悉任务、只要结果 |
| medium | 平衡解释和结果 | 日常工作 |
| high | 详细解释每步 | 学习、复杂任务想看 Codex 思路 |
verbosity 控制“Codex 给你输出多详细”,reasoning effort 控制“Codex 内部想多深”——前者影响阅读体验,后者影响质量,是两件事。
5.2 加速模式(Fast Mode):花用量换速度
按 OpenAI Codex speed 页,“Fast mode 让受支持模型的速度提高 1.5 倍”(increases supported model speed by 1.5x),代价是用量积分按更高倍率消耗——官方页给的倍率是 GPT-5.5 为标准档的 2.5 倍、GPT-5.4 为标准档的 2 倍。也就是说,提速 1.5 倍要付出 2 到 2.5 倍的用量,划不划算取决于你是不是真在等。
Fast mode 只在用 ChatGPT 账号登录时可用;用 API key 时走标准 API 计费、用不了 Fast mode。
# 会话内开关
/fast on
/fast off
/fast status
# 持久化在 config.toml
service_tier = "fast"
[features]
fast_mode = true
什么时候开:
| 场景 | 开 Fast 吗 |
|---|---|
| 我盯着屏幕在等结果 | ✅ 开 |
| Codex 跑长任务我去做别的 | ❌ 关,省用量 |
| 实时编辑器补全 | ✅ 开 |
| 跑批 / 后台 cron | ❌ 关 |
| 当月用量快用完 | ❌ 关 |
5.3 服务档位(Service Tier):还有一个 flex
按 config-reference,service_tier 的内置值含 flex 和 fast。flex 速度更慢但消耗更低,适合不在乎延迟的批处理;fast 就是上面的加速模式。新手第一周不用碰 flex,先把标准档与 fast 切顺。
六、配置集(Profiles):把组合存起来一键切
旋钮多了,每次任务前手动调四个开关很烦。配置集(Profiles)就是解决这个的——把“模型 + 推理深度 + 输出密度 + 服务档位 + 沙箱 + 审批”一整套打包命名,启动时一行 --profile <名字> 切换。
6.1 直接抄这套配置集
把下面这段加到 ~/.codex/config.toml:
# ============ 配置集 1:日常默认 ============
[profiles.daily]
model = "gpt-5.5" # 主模型
model_reasoning_effort = "medium" # 平衡推理
model_verbosity = "medium" # 平衡输出
sandbox_mode = "workspace-write" # 工作区可写
approval_policy = "on-request" # 按需问
# ============ 配置集 2:批改省用量 ============
[profiles.budget]
model = "gpt-5.4-mini" # 轻量模型
model_reasoning_effort = "low" # 低推理
model_verbosity = "low" # 简短输出
sandbox_mode = "workspace-write"
approval_policy = "on-request"
# ============ 配置集 3:复杂重构 ============
[profiles.deep]
model = "gpt-5.5"
model_reasoning_effort = "high" # 深推理
model_verbosity = "medium"
sandbox_mode = "workspace-write"
approval_policy = "on-request"
# ============ 配置集 4:极难任务 ============
[profiles.extreme]
model = "gpt-5.5"
model_reasoning_effort = "xhigh" # 最深(受模型支持限制)
model_verbosity = "high" # 详细输出
sandbox_mode = "workspace-write"
approval_policy = "on-request"
# ============ 配置集 5:只读探索 ============
[profiles.readonly]
model = "gpt-5.4-mini" # mini 省用量
model_reasoning_effort = "low"
sandbox_mode = "read-only" # 只读
approval_policy = "on-request"
切换:
codex --profile daily # 日常
codex --profile budget # 批改省用量
codex --profile deep # 复杂重构
codex --profile extreme # 极难任务
codex --profile readonly # 只读探索
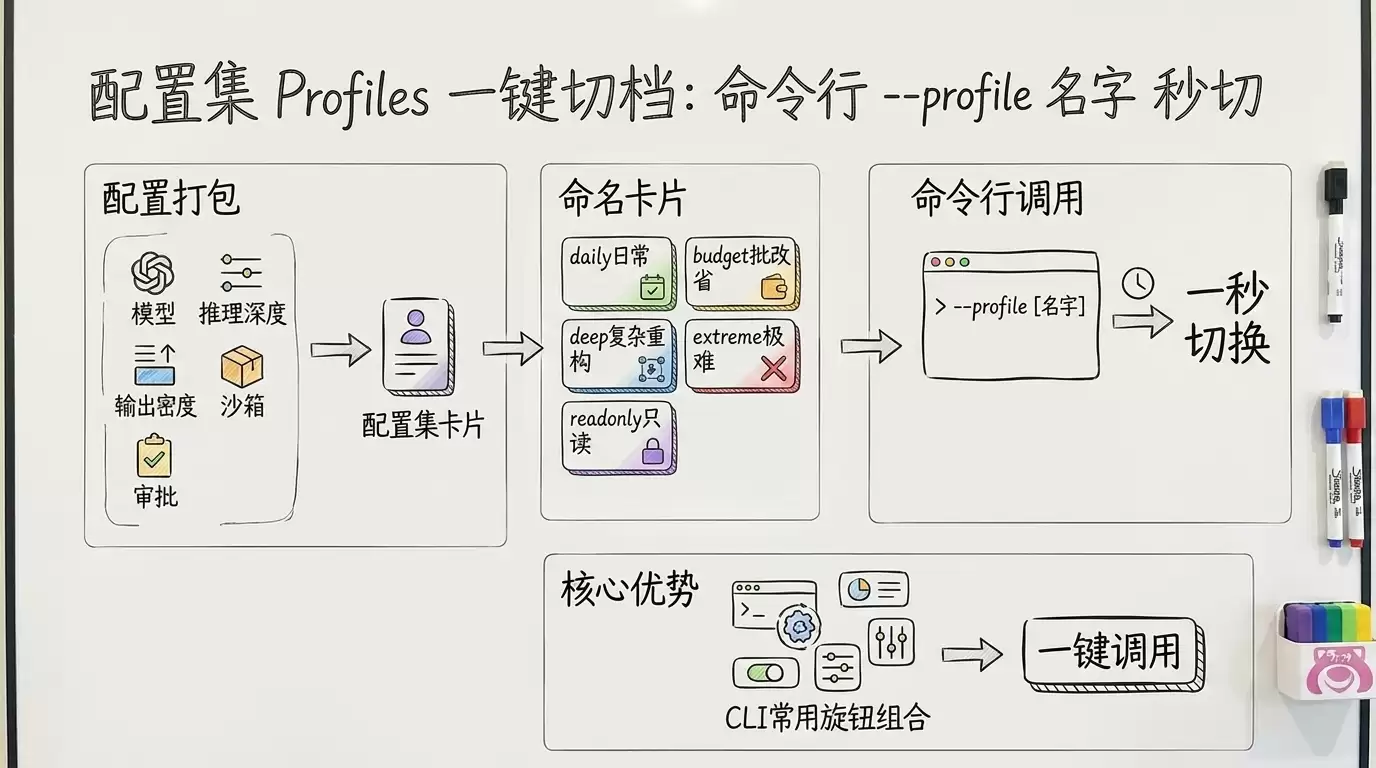
6.2 配置集只在命令行(CLI)有效
按 config-reference,profile 文件存为 $CODEX_HOME/<名字>.config.toml,靠 codex --profile <名字> 加载——这是命令行(CLI)的能力。桌面应用(App)没有这个一键切换入口,IDE 扩展虽与 CLI 共享 config.toml,也没有等价的一键切档命令。主要用 App 的人要切档,只能进 Settings 手动调每个旋钮——这是 CLI 比 App 顺手的地方之一,Codex 四个入口对比里展开讲过。
七、官方省用量做法 + 实战补充
OpenAI Codex pricing 页公开了四条让用量上限更耐用的官方做法。下面前四条是官方原话要点,后两条是配套的实战补充(已标注非官方)。
| # | 做法 | 来源 |
|---|---|---|
| 1 | 控制提示词大小:给指令要精准,但删掉不必要的上下文,别把半个仓库贴进 prompt | 官方 |
| 2 | 嵌套 AGENTS.md:用嵌套的 AGENTS.md 按目录分层控制注入的上下文,不要堆在一个长文件里 | 官方 |
| 3 | 关掉不用的 MCP:每个 MCP(模型上下文协议)服务器都往消息里加上下文、吃额度,不用就关 | 官方 |
| 4 | 换更小的模型:换到 GPT-5.4 或 GPT-5.4-mini 能延长本地消息用量上限,省多少取决于从哪个模型切过去 | 官方 |
| 5 | 不盯着等结果时关掉 Fast mode、用标准档位 | 实战补充 |
| 6 | 一个袋里能干完就不无谓拆子袋里 | 实战补充 |
下面把最常用的两条展开。
7.1 控制提示词与缩短 AGENTS.md
AGENTS.md 在每次对话都自动加载,文件越长每次消耗的输入令牌(token)越多。新手该做的:全局 AGENTS.md 别堆太长;项目专属规则放项目根的 AGENTS.md,不要全塞进全局;单体仓库(monorepo)里用多级 AGENTS.md,不要把所有子项目规则放根目录。
7.2 关掉不用的 MCP + 压缩长会话
- 配置文件里只列你真用的 MCP,不用的删掉或暂停。
- 长会话里用
/compact把之前的内容压缩成摘要,释放上下文空间——对话超过二十来轮、切换到新子任务、或看到上下文占用偏高的提示时,压一下。 - 跑批别用交互模式逐个开,用
codex exec循环跑:
# 反例(每篇都重新加载完整上下文):
for file in *.md; do
codex> 改 $file 的标点
done
# 正例(一条命令循环跑,每篇任务体令牌独立):
for file in *.md; do
codex exec --profile budget "把 $file 的中文标点改全角"
done
7.3 子袋里(Subagent)的用量账
Codex 不会自动拆子袋里,只在你明确要求时才启动。但每个子袋里都独立跑一遍模型加工具调用,所以子袋里工作流的总用量会明显高于单袋里——官方没有给出具体倍率,但“每多一个袋里就多一份模型与工具开销”这笔账要心里有数。
| 情况 | 该怎么做 |
|---|---|
| 一个袋里能干完 | 别拆,拆出来反而费用量 |
| 真要并行(同时探索多个文件) | 给子袋里用轻量 mini,而不是主模型 |
| 一批小任务要并行 | 优先用便宜的 mini 跑多个,往往比主模型拆子袋里划算 |
子袋里什么时候真正值得用,见子袋里与并行编排。
7.4 每月花五分钟看一次 Usage
省用量不是一次配好就完事,而是定期回头看。Codex 设置里有 Usage 面板,每月底花几分钟看三件事,往往能在下个月省下一笔:
| 看什么 | 发现问题的信号 |
|---|---|
| 这个月用了多少、还剩多少天 | 提前耗尽 → 多半在某类任务上用了过高的档 |
| 哪个配置集用得最多 | deep / extreme 占比异常高 → 任务真变难了,还是忘了切回轻挡 |
| 有没有“本该切 mini 却用了主模型”的场景 | 这是最常见、也最容易补回来的漏切 |
八、六种典型任务的完整旋钮组合
第一节给了速查表,这一节把六种高频任务展开成完整组合,连沙箱、配套动作一起说清。
8.1 任务 A:日常写代码
场景:写一个接口、加一个表单、改一段业务逻辑、debug 一个不太难的 bug。
| 旋钮 | 设置 |
|---|---|
| 模型 | 主模型(gpt-5.5) |
| 推理深度 | medium |
| 输出密度 | medium |
| 加速模式 | 关 |
用 daily 配置集就是这套。
8.2 任务 B:跑批改、批量处理
场景:批量改文章标点、批量替换 import 路径、给一批组件补 alt 文本。
| 旋钮 | 设置 |
|---|---|
| 模型 | 轻量 mini |
| 推理深度 | low / minimal |
| 输出密度 | low |
| 加速模式 | 关 |
切到 budget 配置集,配合 codex exec 后台跑。这类任务质量不分高下(标点改对就是改对),mini + 低推理跑得更快、用量是主模型的零头——把批改硬塞给主模型是新手最常见的浪费。
8.3 任务 C:跨文件复杂重构
场景:把嵌套 if-else 拆成早返回、把一套路由迁到另一个框架、class 组件改 hooks。
| 旋钮 | 设置 |
|---|---|
| 模型 | 主模型 |
| 推理深度 | high |
| 输出密度 | medium |
| 加速模式 | 关 |
切到 deep 配置集,可以先让它 Plan(规划)再动手。复杂重构动手前先 git commit 一次当检查点——改坏了能直接 git reset 回滚。
8.4 任务 D:架构迁移、安全审计
场景:换数据库、换状态管理库、做安全审计、跨语言迁移。
| 旋钮 | 设置 |
|---|---|
| 模型 | 主模型 |
| 推理深度 | xhigh |
| 输出密度 | high |
| 加速模式 | 关 |
切到 extreme 配置集,配合 Plan 模式 + 反复核对。这是少数 xhigh 真值得的场景:任务越难、回滚成本越高,多花的用量越划算。反过来,简单任务硬上 xhigh 就是纯烧用量。
8.5 任务 E:实时编辑器补全
场景:在 IDE 里按 Tab 补全函数、补全 import、补全测试用例。
| 旋钮 | 设置 |
|---|---|
| 模型 | spark(如有)/ mini |
| 推理深度 | minimal / low |
| 输出密度 | low |
| 加速模式 | 开 |
实时补全主要在 IDE 扩展里用(见 Codex 四个入口对比),CLI 模式很少做这件事。
8.6 任务 F:探索 / 调研
场景:让 Codex 解释陌生代码、扫一个新仓库介绍架构、查 API 怎么用。
| 旋钮 | 设置 |
|---|---|
| 模型 | mini |
| 推理深度 | low / medium |
| 输出密度 | high |
| 沙箱 | read-only(只读) |
切到 readonly 配置集。这种任务沙箱必须设只读——避免 Codex“热心”帮你改代码。沙箱与审批怎么配,见 OpenAI Codex 沙箱与审批。
九、五个最容易踩的旋钮坑
| 坑 | 后果 | 正确做法 |
|---|---|---|
| 以为最高档 = 最好结果 | 简单任务上 xhigh 反而“想太多”出错、白烧用量 | 按任务难度选档:medium 起步、high 留给复杂、xhigh 留给最难 |
| 长期开 Fast mode | 提速约 1.5 倍却按 2~2.5 倍消耗用量,后台 / 长任务开纯烧 | 只在“人在屏幕前等”时开,离开就关 |
| 从不切到 mini | 简单批改硬用主模型,用量翻倍且质量没差 | 批改 / 探索切 mini,这是最大的省用量杠杆 |
| AGENTS.md 越写越长 | 每次对话全文进上下文,浪费输入令牌 | 按目录分层、嵌套,长了拆子目录(见 AGENTS.md 指南) |
| 所有 MCP 都开着 | 每个 MCP 的工具描述都塞进上下文,启动开销叠加 | 不用的 MCP 在配置里关掉 |
十、跑顺一两周之后的进阶路径
第一份默认配置跑顺后,会自然产生进阶需求:
| 你的感受 | 下一步 |
|---|---|
| “每天在重复调相同的旋钮” | 用 Profiles 配置集打包,一键切 |
| “批改太烧用量” | 切 budget:mini + 低推理 |
| “实时补全延迟高” | 切 spark / mini + 开 Fast |
| “跑批想更省” | 试 service_tier = "flex" |
| “想看本月用量趋势” | Codex 设置里的 Usage 面板 |
| “想把成本接进自己的监控” | 用 OpenTelemetry(OTel)导出运行数据 |
十一、开会话前的自检清单
每次开会话前对自己问一遍:
- [ ] 这个任务真需要主模型吗?mini 够不够?
- [ ] 复杂度够升 high 吗?还是 medium 就行?
- [ ] 我会盯着屏幕等吗?要不要开 Fast?
- [ ] AGENTS.md 是不是又长了?要不要剪一下?
- [ ] 开着的 MCP 都用得到吗?
- [ ] 当月用量还剩多少?
- [ ] 这个任务该用配置集,还是手动调?
一句话收官
OpenAI Codex 不是“一个模型”,是“一组旋钮”——模型 / 推理深度 / 输出密度 / 加速模式四个独立维度。新手最大的杠杆是学会按任务难度切档,不是“调到最高”。
记住第一节那张速查表就够开工:日常写代码用主模型 + medium、批改切 mini + 低推理、最难任务才上 xhigh、只在盯着屏幕等时开 Fast。光是“该用 mini 的时候不硬用主模型”这一条,就能让同样的额度明显多撑一阵。模型名、档位默认值、价格倍率这些都会变,落地前以 OpenAI 官方当前文档为准。




