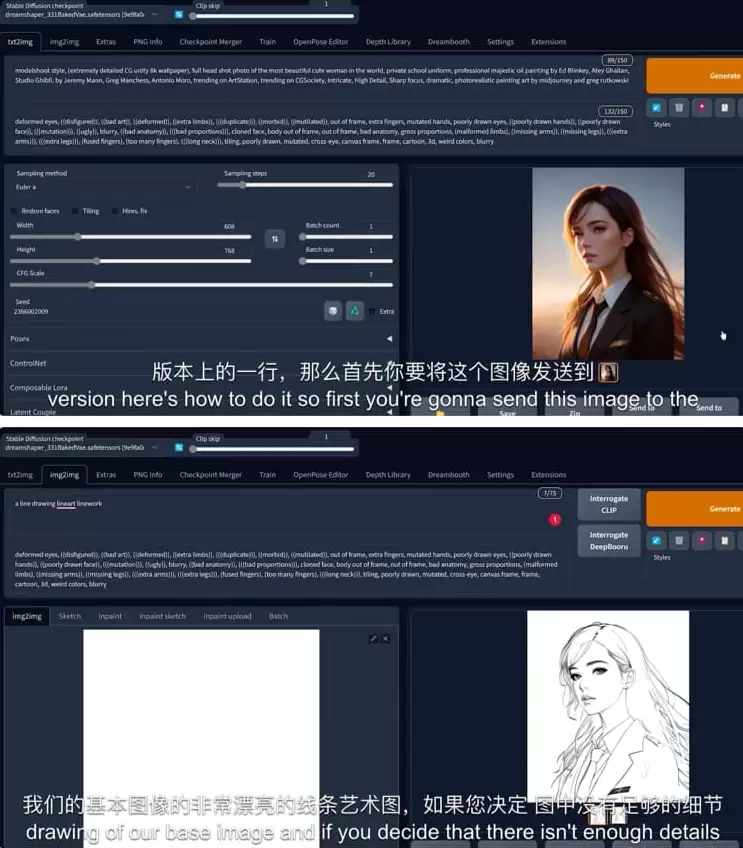
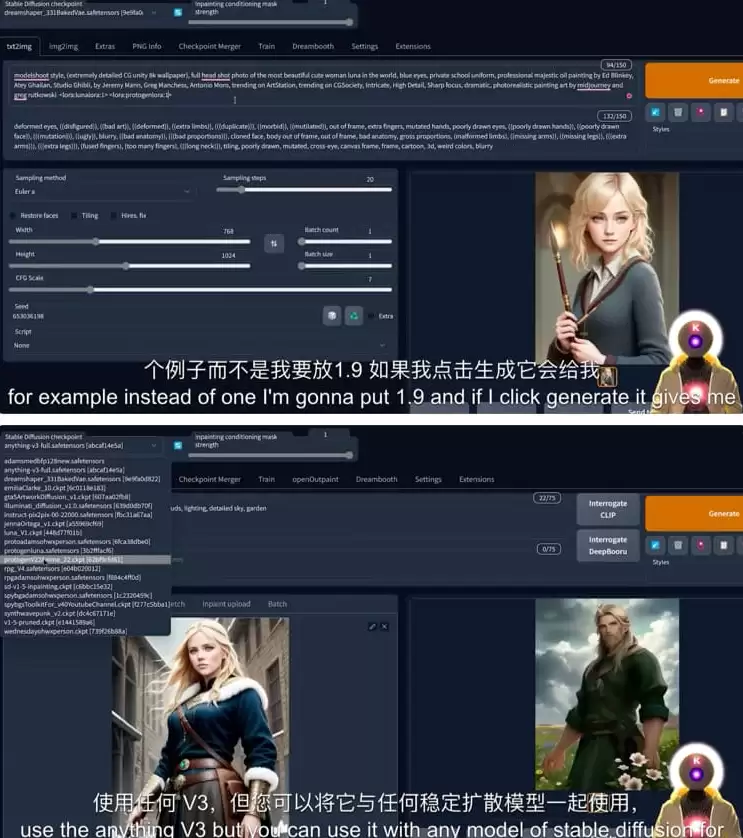
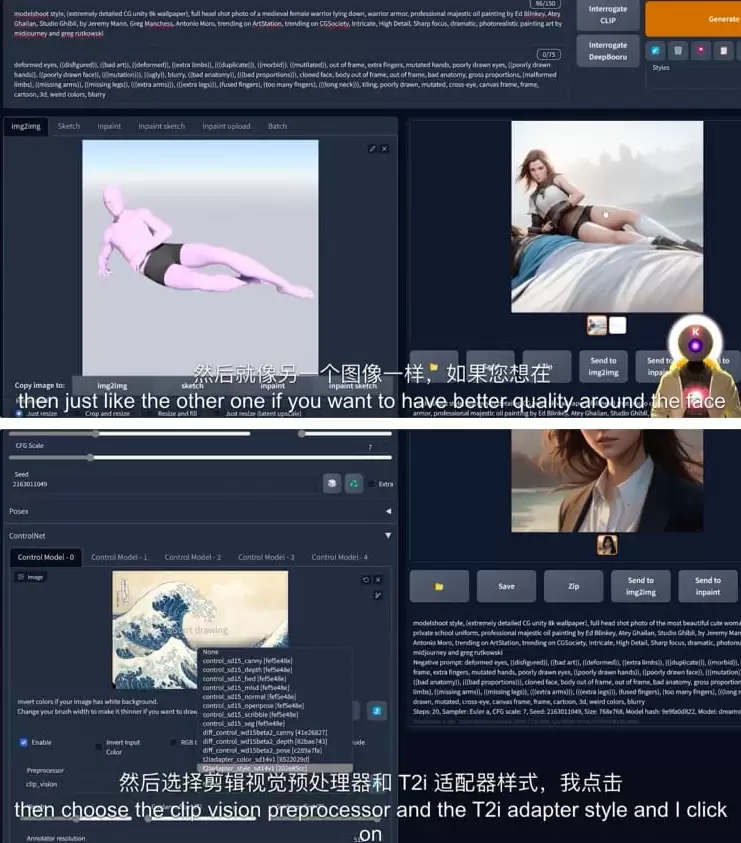
如果你正在探索AI绘画领域,一定对Stable Diffusion这个名字耳熟能详。作为一款开源图像生成模型,它已成为无数创作者和设计师探索创意边界的高效助手。其核心优势在于,不仅能将天马行空的文字描述转化为逼真的视觉作品,更能提供海量风格参考,在创作初期充分激发灵感,让你彻底告别在浩瀚图库中手动寻找素材的繁琐工作。

那么,Stable Diffusion到底有何独特之处?简单而言,它是由Stability AI公司打造的开源AI图像生成模型。其核心魅力,可归纳为以下几个关键特性:
- 训练高效:借助自监督学习与差分隐私技术,训练高质量模型不再完全依赖海量人工标注数据,流程更加简洁高效。
- 功能全面:无论是图像增强、风格迁移,还是从零开始生成全新画面,它都能轻松应对。用户可根据实际需求灵活选择不同生成模式。
- 效果出众:在生成图像的真实感和画质上,它获得了广泛好评,尤其在人物肖像生成方面表现尤为亮眼。
- 风格自定义:通过输入参考图片或详细的风格描述,可以精准引导生成方向,实现高度个性化的创意表达。
- 易于部署:模型基于PyTorch框架开发,训练代码与模型权重均已开源,极大方便了研究者和开发者进行二次开发与商业部署。
- 分辨率灵活:支持从64×64到1024×1024等多种分辨率,满足从快速草图到高清成品的不同场景需求。
总体来看,Stable Diffusion的成功在于巧妙融合了前沿的自监督学习技术与实用的定制化功能。它不仅仅是一款工具,更是一个强大的创意引擎。其开源属性显著降低了技术门槛,让任何人都能借助它实现自己的视觉构想,这无疑正在深刻改变内容创作与设计生产的工作流程。
可以说,Stable Diffusion是AI图像生成领域具有里程碑意义的存在。它的问世与持续演进,正推动整个创意产业向更深层次的AI融合不断迈进。