归根结底,现阶段智能体(Agent)的性能瓶颈并非单纯依赖模型的“智商”,绝大多数失败案例的根源在于模型无法准确解析上下文——那些隐含规则、行业惯例与问题预设,都处于模型的理解盲区中。
如今,这一层被称作“harness”的组件加以封装。它负责上下文的存取管理、提示词的缓存、工具的识别与调用、将上下文中的噪声降至最低、实现会话信息的结构化,并能够协调多个Agent协同工作。
换言之,这些基础设施的目标并非让模型变得更聪明,而是确保模型获取的上下文正确且可控,避免被各类干扰信息淹没。因此行业内常有人言,同一模型搭配不同的harness,实际效果可能相差十倍之多。
需要强调的是,这一差距无法通过更换更强大的模型或撰写更优质的提示词来弥补。关键在于:上下文是否完整、工具是否能被高效复用、记忆是否能被妥善整理、技能是否能固化沉淀、流程是否能顺畅编排、结果是否能可靠验证。
举一个简单例子。以往我们总认为,给模型提供足够多的上下文就能解决问题,但最终发现推理过程与质量依然不理想。然而换个思路,倘若能为模型配置一个快速且精准的定制化工具,其效率可能提升百倍。
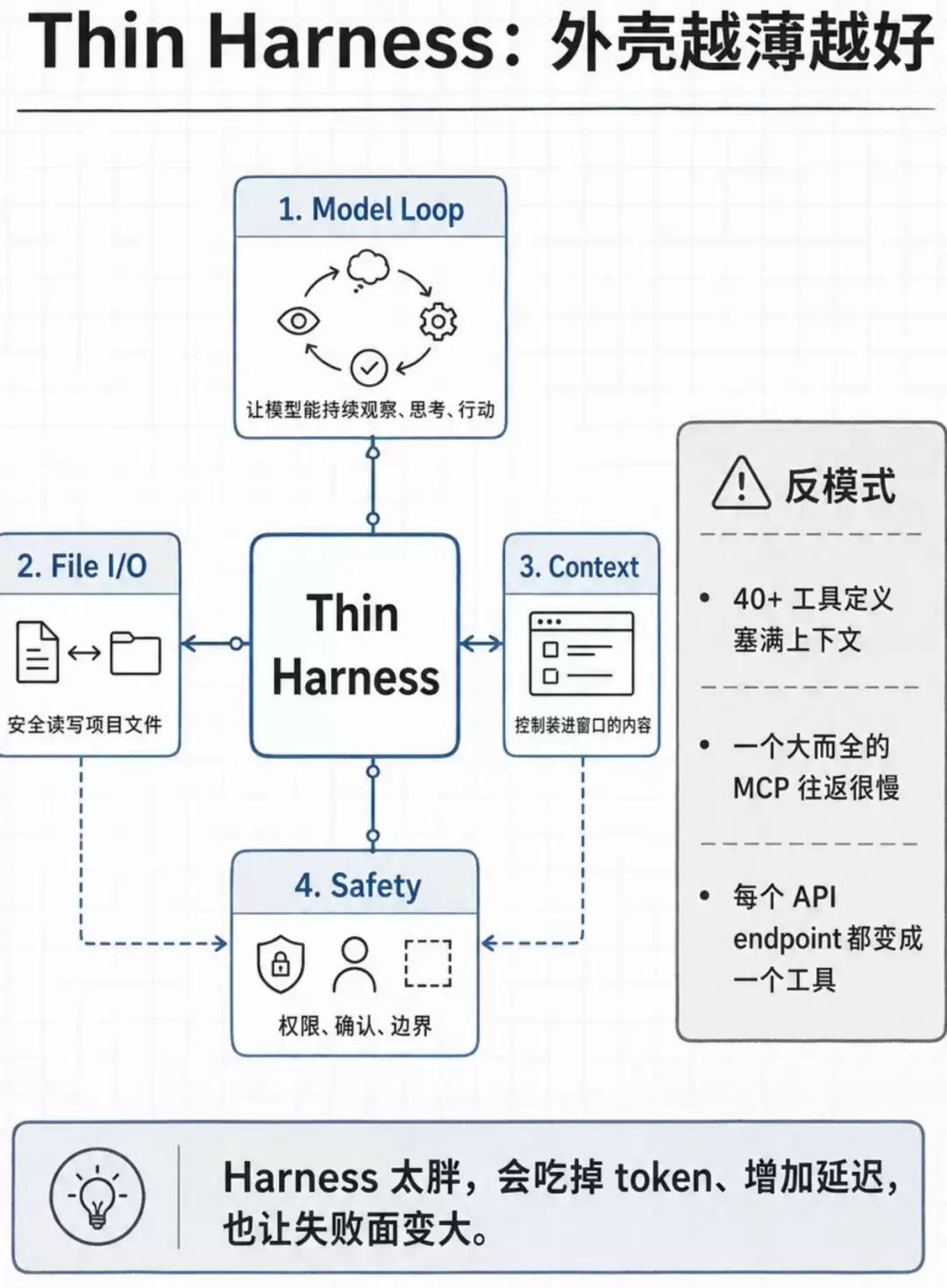
又如,一次性塞给模型40个工具,仅工具定义就占用了近一半的上下文窗口。每个工具来回调用耗时2至3秒,这还只是单次操作。结果便是:Token消耗增加3倍,延迟增加3倍,失败率同样飙升3倍。
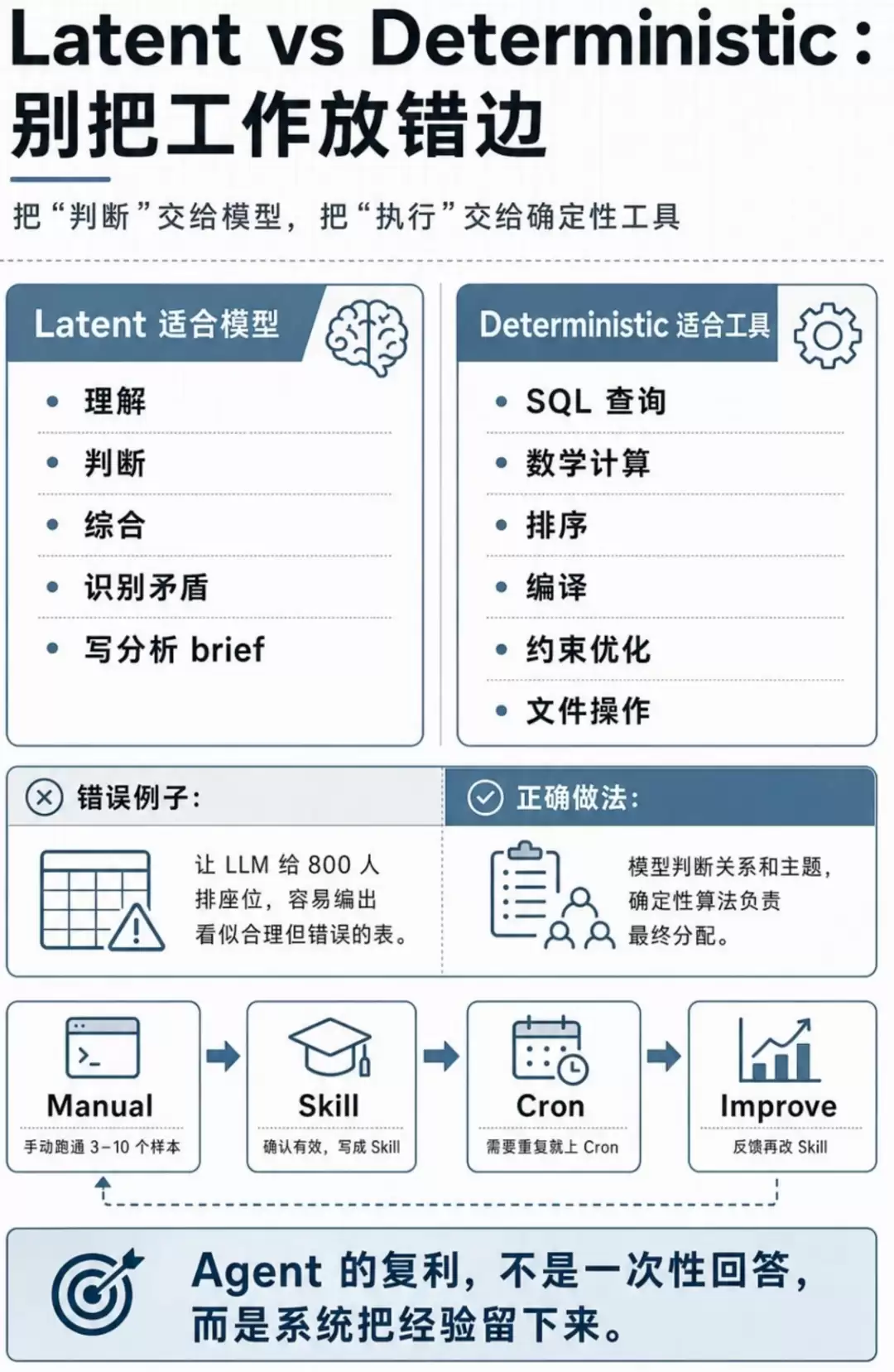
因此,这背后实则是一次原则性的转变:从“给模型海量上下文,令其概率性地推理”转向“让模型执行确定性的任务”。
通用Agent的“通用性”核心体现在harness上——例如文件管理、上下文读取与加载、安全校验与审计。而专有领域Agent的上限,则取决于那些凝结了逻辑判断、业务流程与领域知识的skill,这些正是90%价值的来源。
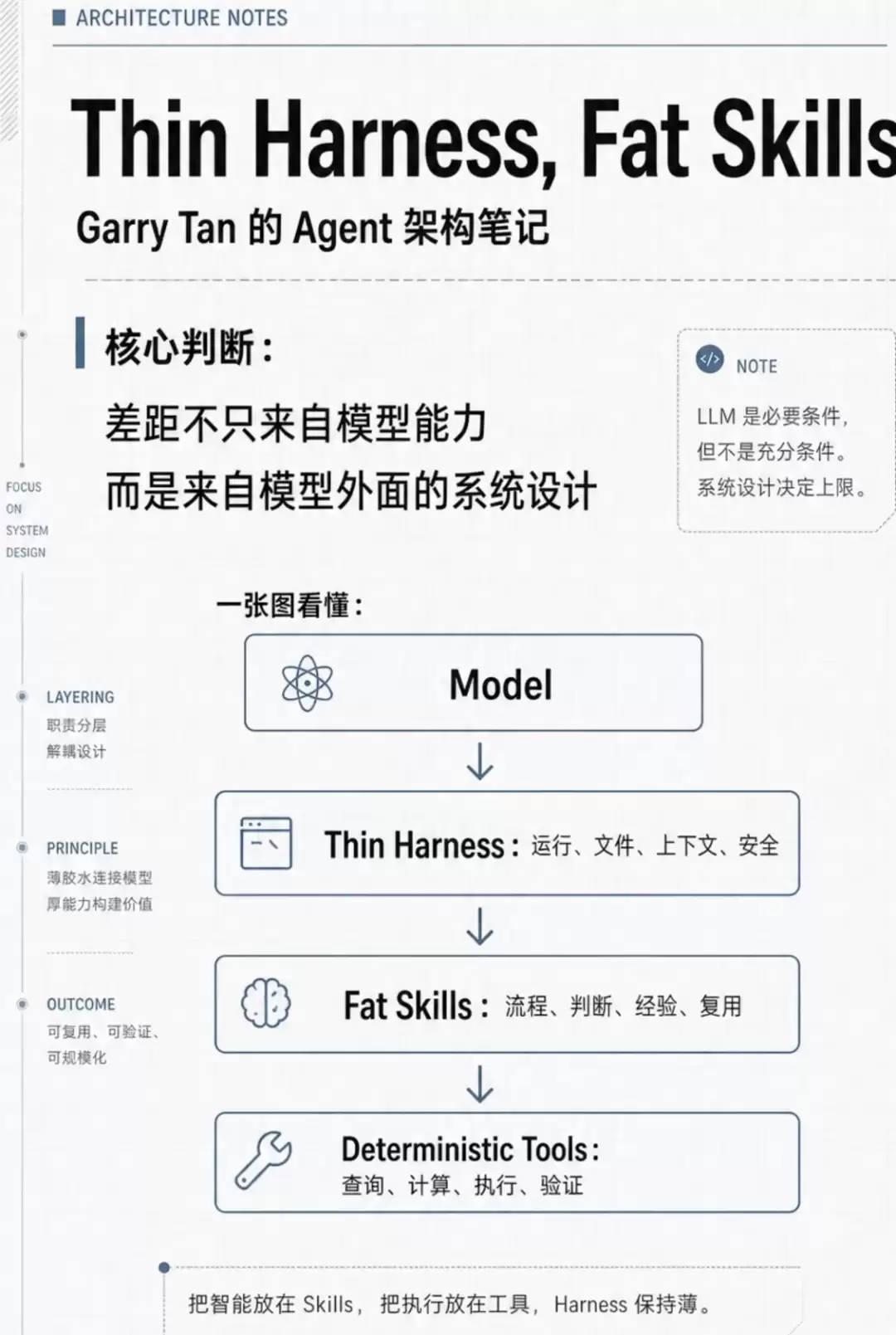
换言之,智能向上收敛至skill,执行向下下沉到tools。
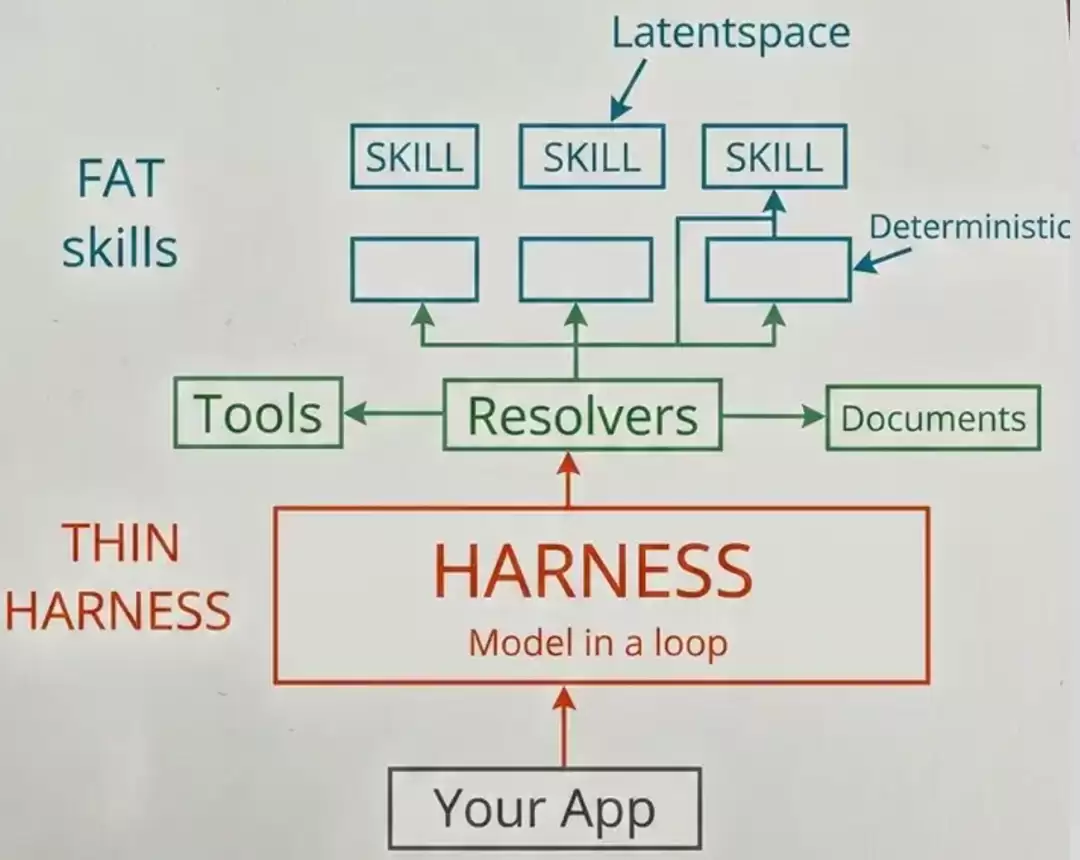
这样来看,harness的职责便十分清晰:其核心是调度,不应也不宜承载过多业务逻辑,必须保持轻量化。主要承担以下工作:文件读写、状态机驱动(无论是ReAct还是Plan-and-Execute)、上下文管理(历史对话维护、Token控制、必要时压缩或截断总结),以及边界守卫(权限越界检测、异常处理、重试机制等)。
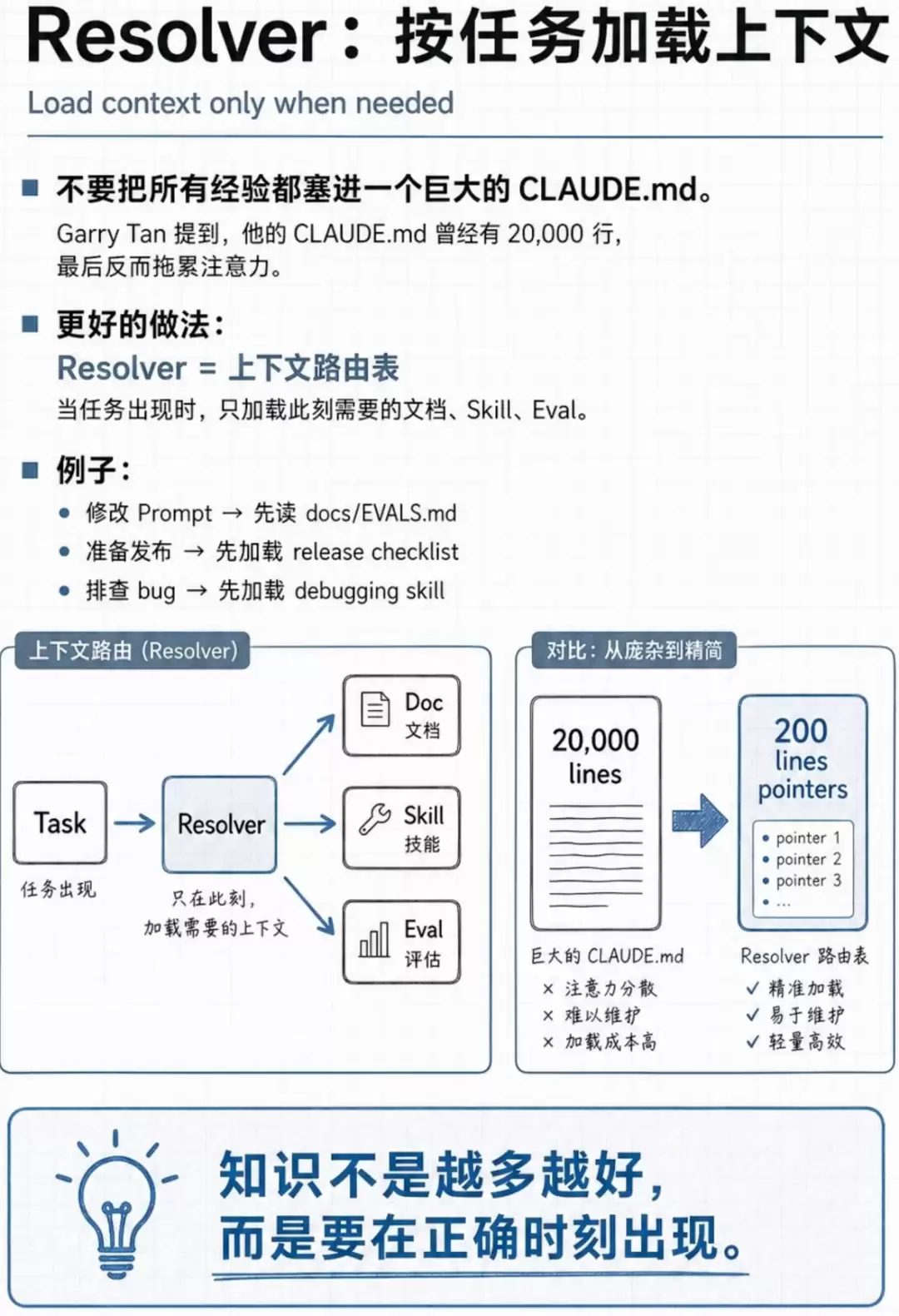
再看Resolver,它实际上是一个解析器,同时也是决策中枢。在发布之前,它会先读取docs/EVALS.md文件进行评估,其中包含了各类评估套件、基线分数与准确率信息。只有通过评估器验证的发布,才能被视为可信。
Resolver还扮演着路由表的角色。为了避免将所有skill一股脑塞入上下文,它能智能判断:当任务类型为X时,加载Y相关文档。面对用户的请求与提示词,它基于向量检索与语义路由,找到最匹配当前任务的特定skill。在Claude Code中,它所做的正是根据用户意图与技能描述进行匹配。
Tools这一层是确定性的。为何强调确定性?道理很简单:相同的输入必须每次都产出相同的输出,工具天然能够保证这一点。确定性的工具层是消除模型幻觉的有力武器,使Agent变得可控——判断力交由模型,执行力交由工具。
若要让Agent在专有业务领域高效稳定运行,最佳方式并非灌输大道理或堆砌所有SOP。更有效的方法是将业务流程提炼、沉淀,并固化为一个个skill。
这些skill文件,很类似于编程语言中的类与方法。它们具备明确的输入输出规范、清晰的前置校验逻辑、完整的执行流程,以及严格的约束条件与预期输出。高度结构化的Markdown文件能够使模型的注意力机制更加聚焦,显著降低执行过程中的漂移概率与幻觉问题。
因此,对业务逻辑进行抽象至关重要:输入是什么?前置条件是什么?执行标准是什么?输出格式又是什么?将这些内容沉淀进文件后,大模型在读取时才能保持专注,不易偏离方向。





