阿里千问大模型今日正式发布了Qwen3.7-Plus模型,其定位清晰明确——多模态交互混合智能体。
简单来说,Qwen3.7-Plus是Qwen3.7的多模态增强版本,核心定位为视觉与语言统一的智能体基座。这意味着模型不仅具备视觉感知能力,还能基于所见内容进行推理与执行任务。
该模型保留了原版的文本处理、编码、工具调用及生产力工作流等核心功能,并重点强化了视觉理解、视觉推理以及跨模态任务处理能力。可以将其视为一个既擅长编写代码,又能“理解”屏幕内容,还能直接在图形界面中执行操作任务的AI智能体。

目前,Qwen3.7-Plus已通过阿里云百炼平台正式上线,用户还可在Qwen Studio直接体验。该模型支持图像、视频、屏幕、网页及文本等多种输入形式,专为复杂的软件与办公流程而设计。换言之,无论是图形化界面、命令行还是工具环境下的各类任务,它都能轻松应对。
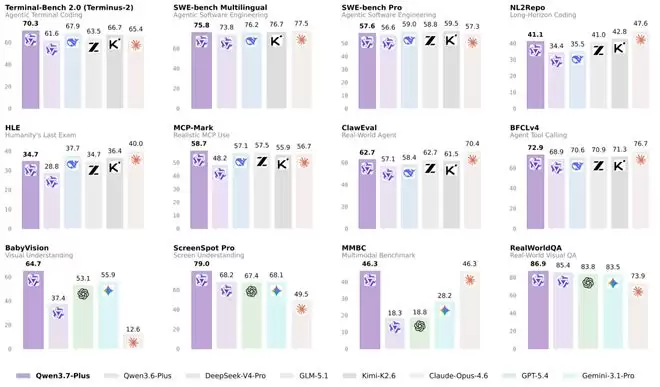
该模型的实际性能同样值得关注。在Vision Arena评估中,Qwen3.7-Plus助力阿里跻身全球前五、中国第一。这一优异成绩,直接反映了其多模态能力的显著提升。

在纯文本测试方面,Qwen3.7-Plus的表现接近Max级别的大模型,在编码智能体、通用智能体、推理、指令遵循及多语言任务上,依然展现出强大的竞争力。文本能力并未因多模态强化而有所削弱。
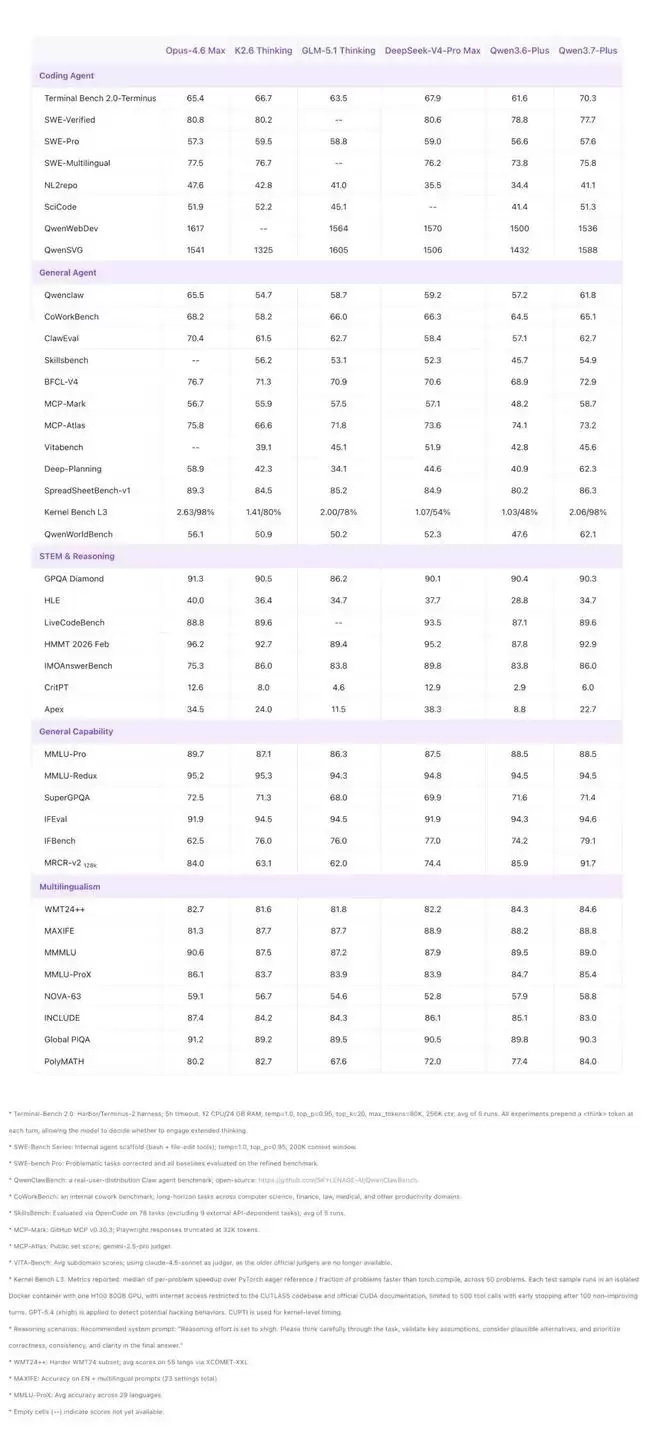
多模态测试结果则更具说服力。该模型在视觉推理、工具调用及完整任务执行链条上均获得显著强化。具体而言,它在BabyVision、MathVision、ScreenSpot Pro、OSWorld-Verified、AndroidWorld等一系列评测中均取得了明显进步。这些评测覆盖范围从婴儿视角的视觉理解到复杂的操作系统界面操作,跨度广泛,标志着模型的泛化能力已跨上一个新台阶。





