先下一个判断:企业级智能体正在经历一场从“经验驱动”到“知识驱动”的范式转移。传统思路依赖动态检索——从历史轨迹里翻找相似片段来指导当前行为,这在一成不变的任务上还行,但一遇到分布外(OOD)的新场景,检索结果往往和当前上下文“打架”,系统鲁棒性大打折扣。那么问题来了:怎么跳出这个坑?答案呼之欲出——把重心转向声明式标准作业程序(SOP)。
这种思路的本质,是把零散的执行轨迹归纳成静态逻辑增强的通用原则。SOP 本身是“架构无关”的,它不绑定任何模型,却能成为异构集群高效协作的底层逻辑。下面这张表对比了以 ReasoningBank 为代表的检索式经验库和以 Trace2Skill 为代表的声明式技能,架构差异一目了然:
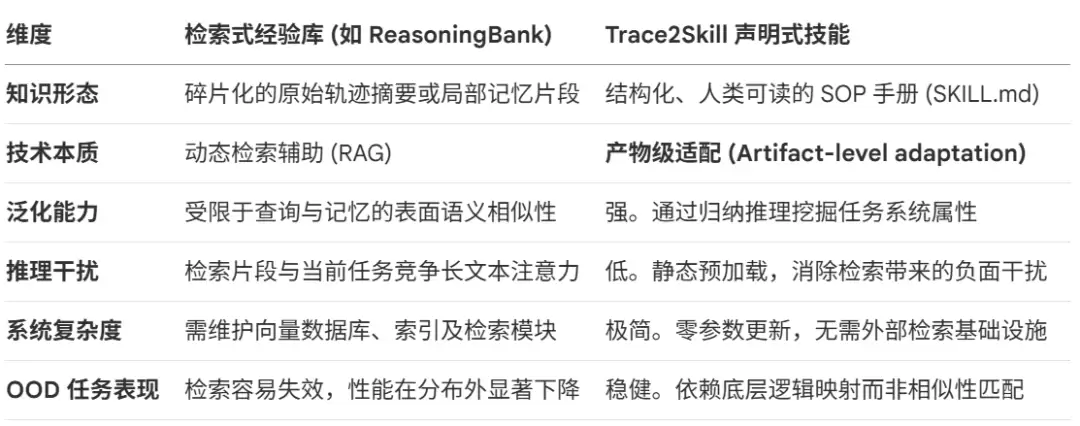
在 Trace2Skill 框架里,声明式技能被定义为一套跨模型可迁移的“专家手册”,核心组件包括:
- SKILL.md(主文档):用自然语言编码程序性知识,涵盖执行策略(比如“由下而上删除行”)、操作步骤以及针对已知失败模式的防御性指南。
- 辅助资源:比如执行确定性子任务的脚本(如强制公式重算的
recalc.py)、领域参考资料等资产。
2. 能力解耦深度分析:“做题”与“教书”的规模效应差异
当我们要搭建异构集群时,一个核心的战略洞察必须摆上台面:执行能力与反思编写能力是两种截然不同的维度。这挑战了“模型越大越好”的传统假设,也为资源配置提供了科学依据。
实验数据揭示了一个颇为反直觉的“能力倒置”现象。拿 DocVQA(视觉问答)任务来说,没有技能辅助的情况下,35B 的小模型(ANLS 0.6843)执行表现居然优于 122B 的大模型(ANLS 0.6424)。然而,35B 虽是个优秀的执行者,却是个“不合格的导师”。当它尝试为自己编写技能时,因为归纳推理深度不够,生成的技能质量极低——不仅没法赋能 122B,反而让自身准确率下降了6.2个百分点。
反思能力的本质是归纳推理,也就是从局部案例中识别系统性规律并转化为高阶规则。这种能力与模型规模强相关。122B 大模型展现出了不可替代的“反射分析能力”——它能够识别深层错误(比如索引偏移导致的计算损坏),并将其提炼成防御性准则。通过解耦“编写”与“使用”技能的能力,企业可以实现“大模型提炼知识、小模型高效执行”的异构模式:用大模型的深层反思来弥补小模型在复杂推理上的短板,不增加推理成本,却显著提升小模型的性能上限。
3. Trace2Skill 核心机制:三阶段自动化经验蒸馏流程
Trace2Skill 模拟人类专家的思维模式,把零散的执行轨迹系统化地转化为高价值的领域资产,整个过程分三步走。
3.1 轨迹生成(Stage 1)
基于初始技能 S₀ 并行生成包含成功(T⁺)与失败(T⁻)样本的语料库,作为后续演进的原始基石。
3.2 非对称分析师设计(Stage 2)
- 成功分析师(A⁺):采用固定单次提取流,快速识别促成正确结果的行为模式。
- 错误分析师(A⁻):采用“袋里循环”(Agentic Loop)。因为错误比成功更难诊断,A⁻ 会交互式检查日志、读取文件、验证修复方案,直到定位根本原因。这种基于证据的分析保证了诊断的因果性。
3.3 无冲突合并(Stage 3)
把成百上千个补丁转化为单一连贯的技能手册,实现从“特定修复”到“通用原则”的升华。这种 agentic 分析机制实现了经验向知识的质变,尤其对于错误轨迹的深度诊断,能确保蒸馏出的技能具有极高的防御价值,有效防止智能体在 OOD 任务中重蹈覆辙。
4. 冲突规避与逻辑升华:并行合并机制的战略优越性
“并行合并”在避免模型“过早收敛”和“顺序漂移”上有显著优势。Trace2Skill 采用层级合并,设置超参数 Bmerge=32,在处理大规模补丁池时效率极高。相比顺序更新,并行合并在处理70条教训时仅需3分钟,实现了20倍的效率提升。这种递归树结构确保了合并过程不是简单的内容堆砌,而是逐层筛选的归纳推理。
通过对补丁池的提炼,系统能识别出电子表格等领域的系统属性 SOP,比如:
- 工具选型最优实践:识别出
pandas.to_excel()会破坏公式,因此 SOP 规定“使用 pandas 进行逻辑转换,使用 openpyxl 进行回写”。 - 回写验证规程:强制在公式写入后运行
recalc.py并以data_only=True模式读回验证。 - 结构性编辑安全:总结出“由下而上、由右向左”的行删除逻辑,防止索引偏移。
系统通过频率加权过滤掉模型特定“怪癖”,只保留反映任务本质属性的原则,同时设置三道确定性护栏——文件存在性检查、物理冲突检测(行级独立性验证)以及格式验证器——确保演进的健壮性。
5. 跨规模迁移与轻量化部署:低成本异构集群的实现路径
声明式技能的“架构无关性”彻底打破了模型规模的隔阂。实验证明,由 35B 小模型编写的技能,竟然能让 122B 大模型在 WikiTQ 任务中提升57.65个百分点(Vrf)。这种“小模型教学、大模型受益”的现象,说明经验已经从模型权重中解耦出来,成为独立可复用的数字产物。
在推理阶段,Trace2Skill 采用“静态提示词注入”(Static Prompt Injection):把进化后的 SKILL.md 预加载到智能体的系统提示词区块。相比动态检索,它消除了检索延迟和注意力竞争,尤其 OOD 稳定性远胜 ReasoningBank。自然语言编码确保知识在不同框架间“即插即用”,且无需参数更新,技能作为独立“插件”运行,运维门槛极低。
6. 企业级演进建议:构建高性价比智能体生态系统
基于前面的分析,这里给出几条构建自进化、高效率智能体系统的顶层设计建议:
6.1 异构资源配比策略
建议采用 1:50 的动态配比原则——配置1台高性能大模型作为“分析师/技能作者”,服务于50台轻量化小模型作为“执行者”。考虑到20倍的合并效率提升,这一比例能在维持 SOP 持续进化的同时,最大化执行端的能效比。
6.2 结构化技能资产管理
将 SOP 转化企业的核心数字资产。构建结构化的技能目录,把领域知识从具体模型中抽象出来,以 Markdown 形式存储。这样即使底层基础模型迭代更替,资产依然长期有效。
6.3 闭环演进路径
- 轨迹积累:并行收集各业务场景下的执行记录,标注成功/失败标识。
- 自动蒸馏:启动 Trace2Skill 框架,利用大模型的 Agentic Loop 进行深度反思与层级合并。
- 全集群部署:将蒸馏出的 SOP 以静态注入方式部署到小模型执行集群,实现系统能力的快速闭环。




