开源具身世界模型τ0-WM:最大规模预训练版本发布
类型:热点整理2026-06-01
具身智能领域已经持续火热近两年。 坦白说,研究者们早已开始认真思考一个问题:如何让机器人真正“学会”某项技能,而不是仅仅在实验室里完美运行,一旦走出门就频频“翻车”。 如今,终于有团队愿意投入“重金”,而且一出手就是**17800小时**的真机遥操作数据,直接用于预训练模型的训练。 你没看错,是一万
具身智能领域已经持续火热近两年。
坦白说,研究者们早已开始认真思考一个问题:如何让机器人真正“学会”某项技能,而不是仅仅在实验室里完美运行,一旦走出门就频频“翻车”。
如今,终于有团队愿意投入“重金”,而且一出手就是**17800小时**的真机遥操作数据,直接用于预训练模型的训练。
你没看错,是一万七千八百小时。
这是什么概念?相当于一台机器人,不眠不休,连续两年,每天24小时都在人类手把手的遥操作指导之下。
在此之前,行业内存在一个心照不宣的共识:真机遥操作数据是奢侈品,昂贵、耗时、难以规模化扩展,只能用在最后微调阶段,当作“画龙点睛”的一笔。
但就在最近,上海创智学院副教授、智元机器人首席科学家**罗剑岚**团队,直接突破了这一天花板——他们发布了**全球最大规模的开源预训练具身世界模型**:
**τ0-World Model(τ0-WM)**。

该模型的参数量达到了**5B**,预训练数据总量更是惊人地接近**3万小时**。其中,**真机遥操作数据第一次成为绝对主力**,占据了1.78万小时。
**这3万小时的预训练数据规模,是目前全球开源预训练具身世界模型中的最大纪录。**
而且,τ0-WM不仅仅是能“预判”未来、能“规划”动作。它最独特之处在于,还结合了**测试时计算(Test-Time Computation)**。简单来说,就是让机器人在实际执行之前,先在脑海中模拟一遍:候选动作里哪个最靠谱?质量不够?那就在虚拟沙盘里再调整、再优化,然后再行动。
基于这套方法,τ0-WM在四个极其考验精细操作能力的任务——工具箱收纳、书包整理、羽毛球装盒、水管接头对接——上的平均成功率,已经直接超越了π0和Fast-WAM。
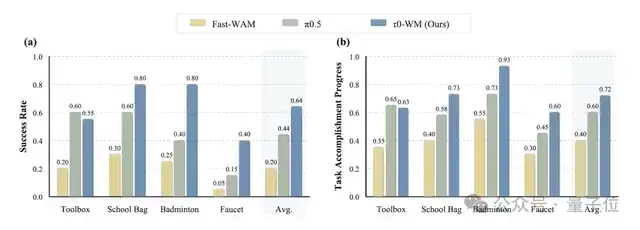
可以说,罗剑岚团队之前在真机数据采集和后训练方面的持续投入,如今终于结出了硕果。他们不仅积累了足够的家底,更探索出了一套将真机数据大规模用于预训练的方法论。
预训练和后训练这两条路径,现在终于被打通了。
提议、推演、评估,然后行动
过去几年,驱动机器人感知和行动的主流范式更像是一种“条件反射”:神经网络一看到画面,便凭借肌肉记忆立刻输出动作。
这种反应式策略,在“抓取-放置”之类的标准任务中确实很高效。
但现实世界中的复杂操作往往是“一步错,步步错”。当面对接触密集、步骤冗长、或者存在严重遮挡的场景时,纯粹依靠“看见就动”很容易造成不可逆的失误。
因此,和许多世界模型一样,**τ0-WM**选择了一条更“谨慎”的路径——让机器人在行动之前,先在脑海中“想象”一下:如果我这样做了,未来会发生什么?环境会变成什么样?
但τ0-WM的过人之处在于,它不只“想象一次”。
为了让机器人真正做到“三思而后行”,研究引入了测试时计算。这相当于给机器人一个内部“虚拟沙盘”,它可以在里面并行地、反复地“模拟多次”,比较不同方案,甚至主动发现并修正错误路径。
换句话说,τ0-WM让机器人不再是“看到即行动”,而是像人一样,先在内心盘算一遍哪种路线更可靠,再决定怎么做。这本质上是在教机器人学会一种“慢思考”。
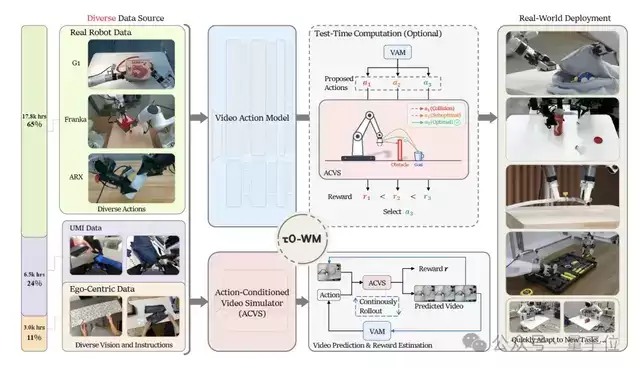
具体到在线推理,τ0-WM可以拆解为三步:
**第一步,提议。**
视频动作模型(VAM)根据当前的多视角画面、语言指令和机器人自身状态,先进行“头脑风暴”,一次性采样出多组候选动作,并生成对应的、略显模糊的未来画面。这好比是机器人快速闪过几种可能的做法。
**第二步,推演。**
动作条件视频模拟器上场,针对每组候选动作,进一步生成更清晰、多视角的未来画面。为什么需要多视角?因为在真实操作中,正面视角常被机械臂或物体遮挡,机器人必须能够从侧面、顶部等其他视角“脑补”出未来状态,才能真正判断该动作的后果。
**第三步,评估与修正。**
系统会用一种称为RCS(Re-denoising Consistency Score)的方式给动作打分:将候选动作重新加入噪声,再丢回模型去噪,观察重建误差。误差越小,说明这个动作越接近模型训练时学到的高质量动作分布,也就越可靠。
如果最优动作的分数依然不够高,就会触发第二层机制LAR(Low-quality Action Rectification)。系统会把所有候选动作送进视频模拟器,预测对应的未来状态和任务进度,从中挑出“任务推进效果最好”的未来画面,然后让VAM基于这个“最优未来”重新生成动作。
经过这三步层层筛选,模型才输出最终的最优动作。
值得一提的是,虽然许多世界模型在训练时也会预测未来,但部署时为了推理速度,往往会把“想象未来”这个模块直接删掉。而τ0-WM则坚持在推理阶段保留了这种“显式未来想象”,并把这些未来画面真正用于后续动作的打分、筛选与修正。
对τ0-WM而言,“想象未来”不是一种训练技巧,而是机器人做决策的核心环节。
在这个三阶段流水线背后,τ0-WM主要由两个共享视频扩散backbone的组件驱动:
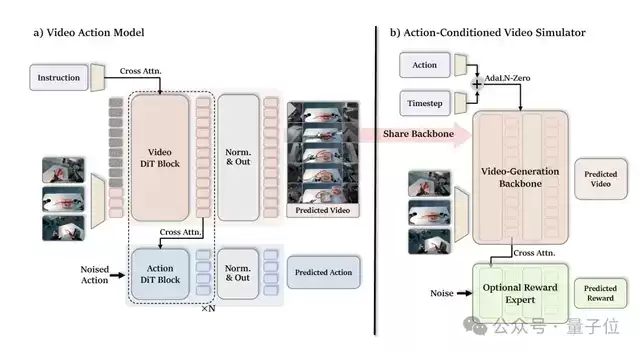
一个是负责“提议动作”的VAM,基于Wan2.2-5B视频生成模型,同时输出未来视频的latent和动作chunk;另一个是负责“沙盘推演”的动作条件视频模拟器,专门评估未来状态和任务进度。
而在训练阶段,三类不同来源的数据,通过一个巧妙的设计——Modality-specific supervision masks——被统一揉进了同一个体系:有动作标签的数据,同时训练视频和动作;没有动作标签的数据,则只训练视频分支。
3万小时预训练数据
接下来,就是τ0-WM这次最“硬核”、也最“重资产”的部分:**训练数据**。
这近3万小时的预训练数据,不仅刷新了开源具身世界模型的规模记录,更重要的是,它正在撼动整个行业对“具身智能数据金字塔”的固有认知。
τ0-WM的训练数据主要由三部分组成,每一类都扮演着独特的角色:

**第一类,真机遥操作数据,总量高达17800小时。**
这部分数据来自双臂机器人、多视角采集,动作空间和真实部署环境完全对齐。这是在行业里公认的“最贵”的数据,因为采集不仅慢,还特别烧人力和硬件资源。但与此同时,它也是质量的金字塔尖,提供了最核心的动作监督信号,是τ0-WM敢做大规模预训练的根基。
**第二类,6500小时的UMI数据。**
UMI(Universal Manipulation Interface)是一种不依赖特定机器人平台的数据采集方式。它的优势在于覆盖的物体种类和操作场景非常丰富,但问题也明显:它的动作空间并不完全等同于真实机器人部署时的动作空间。所以,在τ0-WM里,UMI数据更像是在补“行为多样性”——不一定最精准,但能让模型见过更多操作方式、更多物体、更多长尾场景。
**第三类,3000小时的人类第一视角EgoCentric数据。**
这部分数据的采集成本最低,但覆盖范围最大。里面包含了大量长尾交互行为和机器人很难专门采集到的真实场景。不过,它有一个“硬伤”:没有机器人动作标签。模型只能“看”,不能直接学“机器人该怎么动”。因此,这部分数据只参与视频分支训练,不参与动作预测。它的价值在于帮助模型学习:物体会怎么运动,人与环境如何交互,场景状态会如何变化。
看到这里,一个很自然的问题就冒出来了:既然人类视频没有动作标签,UMI的数据格式又和真机动作空间不完全一致,那模型到底怎么把它们一起训进去?
τ0-WM的解法很巧妙——**模态特定监督掩码(Modality-specific supervision masks)**。
简单说,就是让模型在训练时“看菜下饭”:对于有动作标签的数据,就同时学习视频和动作;没有动作标签的数据,就把动作部分“屏蔽”掉,只学习视觉分支。
这样一来,不同来源、不同模态、不同动作空间的数据,第一次被真正揉进了同一个预训练体系里。
实验:三思而后行,效果立竿见影
在实验部分,团队最核心想验证的一件事就是:测试时计算到底有没有用。
他们选了**抽纸巾放进盒子**和**捡笔放进盒子**两个任务,这两个任务在3万小时预训练数据中从未出现过,属于模型完全没见过的新任务。并且采用了比常规做法更严格的评测标准——不允许重试,单次机会,20轮取平均。
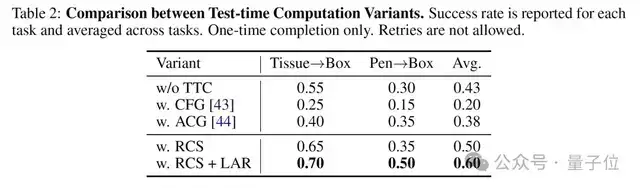
结果非常清晰:不加测试时计算时,裸策略平均成功率只有43%。加入第一层RCS动作筛选后,提升到50%。再接上LAR模拟器修正后,最终达到60%。提升最明显的是更难的Pen→Box任务,成功率直接从30%拉到50%。
研究团队还专门对比了其他测试时引导方法。同样条件下,Classifier-Free Guidance(CFG)成功率只有20%,Action Coherence Guidance(ACG)为38%,而τ0-WM达到60%。
这里的关键区别就在于:CFG和ACG本质上还是在检查“动作本身是否连贯”,而τ0-WM评估的,是“这个动作做完之后,未来世界会变成什么样,任务有没有真正往前推进”。前者关注动作空间内部的一致性,后者则开始真正把“未来后果”纳入决策。
(其余实验细节可参考论文原文)
数据金字塔,要变样了
如果放到整个具身智能行业的数据路线图里看,τ0-WM这次最特别的地方会显得更加突出。
过去,行业的数据体系是一个典型的金字塔结构:
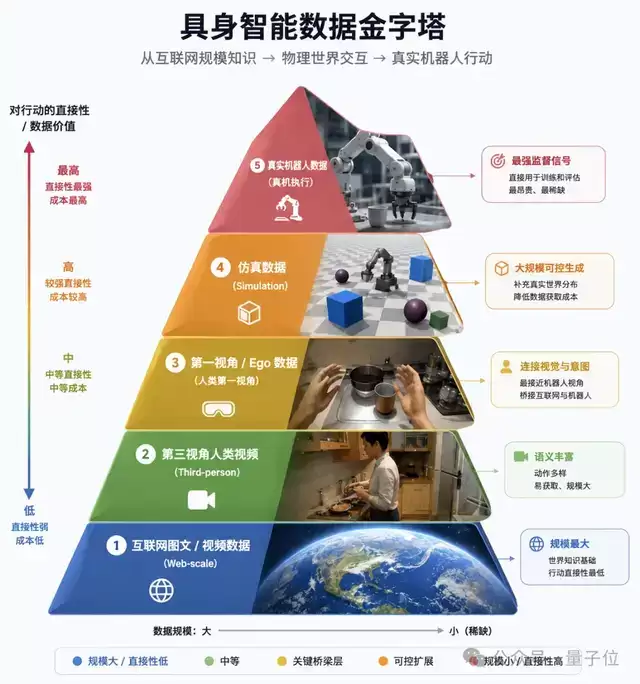
最底层是互联网视频数据,规模最大、最便宜,但没有机器人动作标签,只能让模型学点通用的视觉规律和世界变化规则。再往上,是仿真数据,机器人终于开始“动起来”了,但仿真和真实物理世界之间,那道巨大的sim2real gap始终存在。而金字塔的尖顶,则是真机遥操作数据,质量最高,但行业共识一直是:太贵、太少、根本不可能scale。所以大多数团队都把它留到最后微调时才用。
但今年,一个新的变数出现了——**Ego-Centric第一视角数据**突然崛起。大家开始意识到,人类第一视角视频虽然没有机器人动作标签,但它天然包含了大量真实世界的交互过程、物体变化和长尾操作,很快就成了数据金字塔里那个“新中层”。
问题是,绝大多数团队做到这里就停了,因为大家依然默认真机数据贵到不可能成为预训练主体。
但τ0-WM第一次把这个逻辑彻底翻了过来。
他们一边引入Ego-Centric数据,一边直接用17800小时的真机遥操作数据给预训练打底。这件事不是一夜之间发生的。回看罗剑岚团队过去一年多的工作,会发现一条非常清晰的主线——他们搭的不是单点模型,而是一整套**真实世界数据飞轮**。

2026年1月,SOP搭起了规模化的真机数据采集和回流基础设施。同年4月,LWD把大规模强化学习引入具身VLA的后训练,构建了“部署即训练”的数据飞轮——机器人跑得越多,回流数据越多,模型越强,又能跑更多任务。连失败轨迹也第一次被系统性地纳入学习。

当真实交互数据积累跨越某个临界点后,一件以前没人敢想的事,就自然而然地发生了:**真机数据,终于开始从“后训练耗材”,变成“预训练燃料”。**
直到这里,具身智能那条“预训练—真机部署—数据回流—再预训练”的完整链路,才第一次真正跑通。