StreamingT2V:高质量文本到长视频生成技术详解
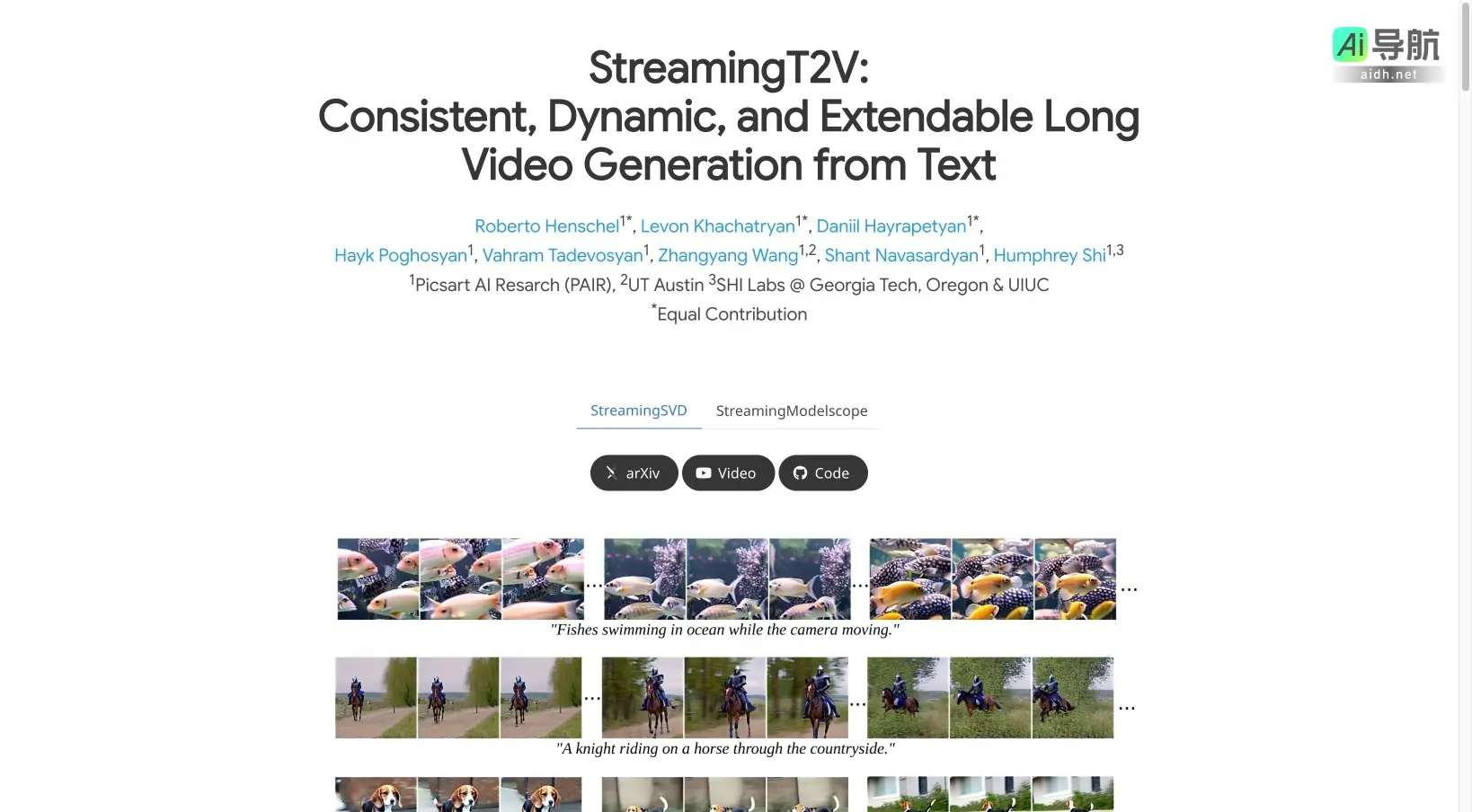
首先,一个核心结论:在文本生成视频领域,StreamingT2V成功实现了长视频的连贯生成。它并非简单拼接短视频,而是采用自回归机制,确保视频具有持续流畅的运动和丰富动态,无任何中断或卡顿。更值得关注的是,它的性能不限于特定文生视频模型。这意味着,随着基础模型的不断进化,StreamingT2V的生成质量也随之提升。
实际应用中,StreamingT2V已成功生成1200帧、长达2分钟的视频片段,理论上还可无限扩展。这背后有三个核心模块协同工作:
- 条件注意模块(CAM):相当于短期记忆模块,利用注意力机制将当前生成帧与先前块的特征对齐,确保相邻片段之间平滑自然的过渡。
- 外观保留模块(APM):负责长期记忆维护,从首个视频块中提取场景和对象的整体特征,防止模型在后继生成中遗忘初始场景。
- 随机混合方法:这是自回归增强的核心技术。通过引入随机混合,视频增强器可多次应用,生成无限长度视频且保持片段间一致性。
工作流程分为三个步骤:首先,使用文生视频模型生成初始16帧块;其次,通过Streaming T2V阶段自回归生成后续帧内容;最后,进入Streaming Refinement阶段,利用高分辨率文生短视频模型对长视频(如600帧、1200帧或更长)进行逐段增强。
实验对比显示,StreamingT2V在运动丰富度上显著领先;相比之下,其他图像转视频方法在自回归应用时容易产生画面停滞。因此,它在长视频生成的一致性和运动表现方面实现了质的飞跃。
数据表现与访问情况
截至目前,StreamingT2V产品页面已获得141次浏览。对此技术感兴趣的用户可直接访问官网:https://streamingt2v.github.io/




