vLLM 再次迎来重要更新,本次发布的是 0.22 稳定版本。
持续关注此项目的用户不难发现,vLLM 的迭代速度持续加快,功能也愈发强大。它已不再仅仅追求吞吐量,而是系统性地攻克生产环境中的各类难题——例如长上下文处理、硬件兼容性,以及备受关注的确定性推断(Batch Invariance)。
我们仔细研读了 Release Notes 及相关技术博客,整理出六大值得关注的更新。本次升级是否值得跟进?读完本文你就能做出判断。
首先通过一张全景图,概览 vLLM 0.22 的六大核心升级方向:
 vLLM 0.22 六大核心升级全景图
vLLM 0.22 六大核心升级全景图
vLLM 0.22 的六大核心升级方向全貌
DeepSeek V4:从“可运行”到“生产就绪”
DeepSeek V4 是近期备受瞩目的明星模型,拥有 1.6T 参数、49B 激活的 MoE 架构,支持 100 万 token 上下文,技术规格十分耀眼。然而在之前的 vLLM 版本中,它仅处于“可以运行”的阶段,距离大规模生产部署仍有一定差距。
v0.22 正是为了弥补这一差距。首先,对模型代码进行了架构重构,将分散的代码整合到独立的 vllm/models/deepseek_v4/ 包中。这意味着 DeepSeek V4 拥有了专属的优化管线,不再受通用框架抽象层的拖累,优化路径更加直接高效。
其次是内核级别的加速,一口气集成了六类融合内核,例如 NVFP4 Fused MoE、MegaMoE 内核、稀疏 MLA 压缩器重构等。其中有一项数据值得关注:采用静态 warpID 分发的 Fused Q norm & KV RoPE & K insert 内核,实测可带来 10-20 倍的加速效果。
更实际的是 KV Cache 的压缩能力。V4 的注意力机制引入了 c4a(约 4 倍压缩)和 c128a(约 128 倍压缩)两级压缩策略。在 bf16 精度下,处理 100 万 token 的上下文时,KV Cache 仅需 9.62 GiB。作为对比,同等规模的 V3.2 需要 83.9 GiB,压缩率接近 8.7 倍。
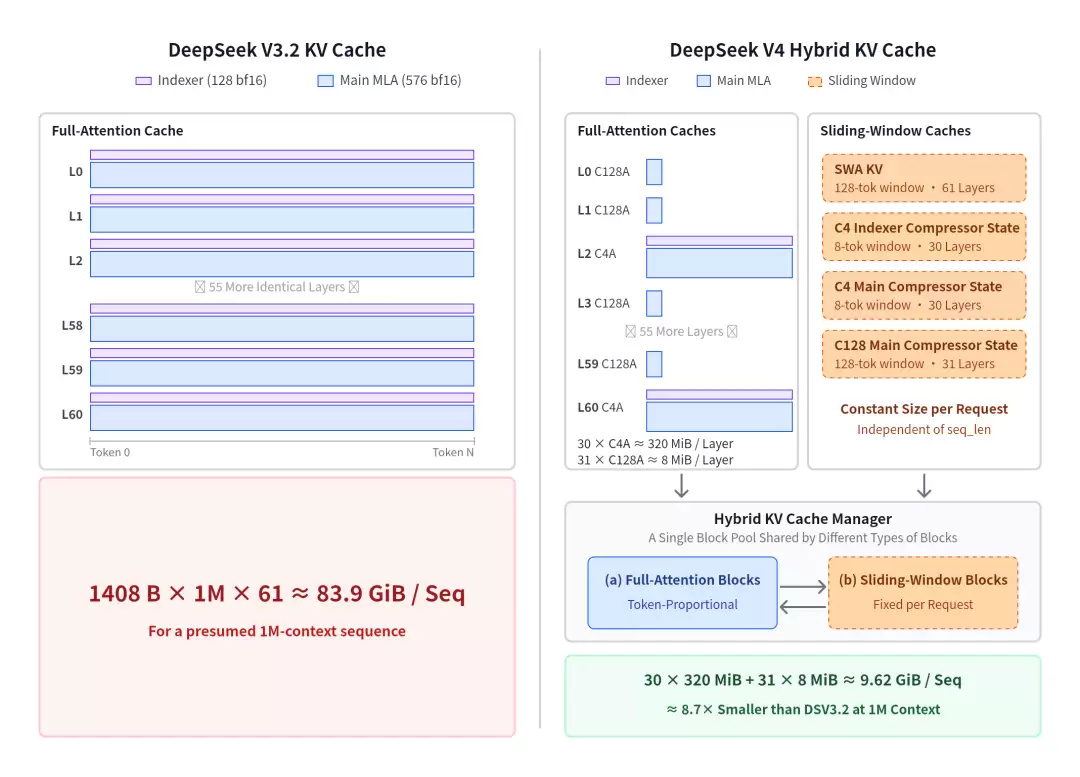 DeepSeek V4 vs V3.2 KV Cache 对比
DeepSeek V4 vs V3.2 KV Cache 对比
DeepSeek V4 与 V3.2 的 KV Cache 占用对比
如果再加上 FP4 indexer 与 fp8 attention cache,容量还能再翻一番。
一句话总结:如果你正在评估 DeepSeek V4 的生产部署方案,v0.22 是第一个真正具备生产能力的版本。
Batch Invariance:精度与速度兼得的新选择
Batch Invariance 是一个“正确但沉重”的功能。它能保证相同的 prompt 在不同 batch 组合下产生完全一致的输出,这对评测、合规审计、RL 训练的可复现性至关重要。但代价是性能下降——因为需要启用确定性内核并关闭 all-reduce 优化,导致“正确但缓慢”的使用体验。
v0.22 在这个方向上实现了质的飞跃。以 Cutlass FP8 路径为例,端到端延迟改善了 28.9%;Padding 预处理也让首 Token 延迟(TTFT)改善了 13.5%。更值得一提的是,NVFP4、SM80 等路径也都获得了 Batch Invariance 支持。
这意味着,Batch Invariance 不再是一个需要权衡的“特殊选项”,而是可以考虑默认开启的特性。
开启方式也非常简洁:
export VLLM_BATCH_INVARIANT=1
vllm serve meta-llama/Llama-3.1-8B-Instruct
目前已验证支持的模型包括 DeepSeek V3/R1、Qwen3 全系列、Qwen2.5、Llama 3 等主流模型族,覆盖范围十分广泛。
Rust 前端:Python 推理热路径的终结信号
这可能是 v0.22 中最具前瞻性的变化。vLLM 原有的 Python 前端在高并发场景下是公认的性能瓶颈——请求调度、Token 分发、数据并行管理都受限于 GIL 和异步调度开销。v0.22 引入的实验性 Rust 前端,直指这一核心问题。
具体来说,Rust 实现已正式合入 vLLM 主仓库,不再是外部实验项目。数据并行场景下的 Supervisor 进程也改用 Rust 实现,负责跨 Worker 的请求分发。构建过程通过 setuptools-rust 集成到 Python 构建流程中,对用户完全透明。
联系 vLLM 此前已有的 Rust Router(高性能负载均衡器),一条清晰的趋势已经浮现:推理热路径正在从 Python 向 Rust 迁移。目前虽然仍处于实验阶段,但方向非常明确。对于重度使用 vLLM 的团队,可以开始关注这一变化了。
多层级 KV Cache 卸载:显存不够?磁盘来凑
KV Cache 管理是长上下文推理的核心瓶颈。过去的做法是 GPU 显存满时直接抢占请求、丢弃 KV Cache,下次重新推理——代价极高。
v0.22 构建了完整的多层级卸载框架,能力链条非常清晰:GPU HBM → CPU DRAM → 文件系统 / 磁盘。
核心能力方面,提供了统一的卸载/加载接口,支持任意层级组合。Python 文件系统二级存储可以通过标准文件系统 API 将 KV Block 持久化到磁盘。DeepSeek V4 也专门适配了混合注意力的 KV 布局。Mooncake 磁盘卸载路径同样支持直接写盘。
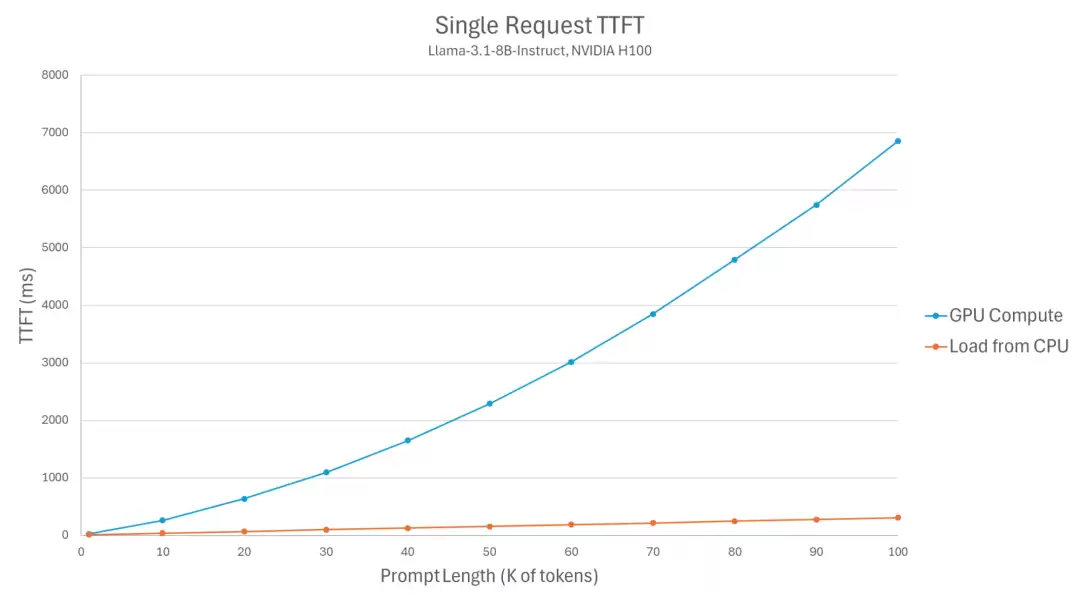 KV Cache 卸载 TTFT 性能对比
KV Cache 卸载 TTFT 性能对比
KV Cache 卸载对 TTFT 性能的影响对比
根据 vLLM 团队的测试数据,从 CPU 加载 KV Cache 可以将 TTFT 降低 2-22 倍(取决于 prompt 长度),并发吞吐量提升最高达 9 倍。
实际意义非常直观:一台 8×H100(640GB HBM)的机器,通过 CPU 内存加 NVMe SSD 卸载,能服务的有效上下文长度可以翻倍甚至更多。虽然可能带来额外延迟,但对于 prefill-heavy 的批处理场景,这一 trade-off 非常划算。
硬件生态:不绑定任何供应商
v0.22 在硬件覆盖上的野心十分明显。除了 Blackwell 的专属优化,AMD ROCm 也得到了平等对待——DSV4 全功能、精度修复、Tilelang MHA、Flash Sparse MLA Triton 内核,甚至连 XGMI 高速互连后端都做了适配。
最令人意外的更新是 CPU / RISC-V。RISC-V Vector Extension 优化的 Attention 内核(VLEN=256)——是的,RISC-V 也能运行 LLM 推理了。AMX CPU 上的 Fused GDN、MXFP4 W4A16 MoE——CPU 上也能运行 MoE 量化模型。此外还有实验性的 Triton & MRv2 CPU 支持。
一句话:vLLM 正在从“NVIDIA 专属推理框架”进化为“全硬件推理基础设施”。
Model Runner V2:温水煮青蛙式接管
MRv2 是 vLLM 的下一代推理运行时。v0.22 的接管策略非常聪明——不搞大爆炸式迁移,而是逐模型验证、逐步扩大默认启用范围。
系统通过 Oracle 机制自动判断当前模型是否适合 MRv2,Qwen3 Dense 已默认走 MRv2。检测到 KV Connector 时自动降级到 MRv1,实现零风险切换。另外,Sleep Mode 可以在推理空闲时释放 GPU 显存,需要时重新加载权重,对于多模型共享 GPU 的场景非常实用。共享 KV Cache 层则能在多模型场景下复用 KV Cache 内存。
其他值得关注的变化
量化生态方面,MXFP4 和 NVFP4 全面铺开,quantization_config 重构为 QuantKey & 激活覆盖模式,为“不同层使用不同量化策略”铺平道路。
解聚合推理方面,NIXL 方案持续完善,GDN 支持 PD 解聚,多节点 TP>8 修复。
LoRA 方面,One-Shot Triton 内核加速 MoE LoRA,同时支持 2D 和 3D MoE LoRA 适配器。
API 方面,新增 thinking_token_budget 支持,reasoning_effort 映射为 enable_thinking,与 OpenAI API 语义对齐。
需要特别注意的是 Breaking Changes——旧版 get_tokenizer 路径已移除,MLA prefill 参数已废弃,升级前务必仔细检查。
升级建议
| 场景 | 建议 |
|---|---|
| DeepSeek V4 用户 | 强烈建议升级,首个生产就绪版本 |
| 需要 Batch Invariance | 强烈建议升级,28.9% 延迟改善消除了精度-速度权衡 |
| Blackwell 用户 | 建议升级,SM12x 专属优化首次大规模落地 |
| AMD ROCm 用户 | 建议升级,ROCm 平等性有实质性进展 |
| 长上下文推理 | 建议评估,多层级 KV 卸载显著扩展有效上下文 |
| 稳定运行中 | 谨慎升级,注意 Breaking Changes |
总结
vLLM 0.22 的关键词是成熟化。DeepSeek V4 从实验走向生产,Batch Invariance 从“慢”变“快”,KV 卸载从单层走向多层,Rust 前端从概念走向代码入树。
横向上,从 NVIDIA 独占走向 AMD/Intel/CPU/RISC-V 全覆盖;纵向上,从纯推理引擎走向包含 Rust Router、DP Supervisor、解聚合推理在内的完整推理基础设施。
对于从事推理基础设施建设的团队而言,vLLM 0.22 是一个不容跳过的版本。




