在 Linux 环境下,用 NVIDIA Tesla T4 配合 CUDA 做 MNN GPU 推理,编译配置这事儿说大不大,说小不小——看似就那么几个步骤,可一旦链接规则、编译器版本、库依赖顺序这些环节出了差错,轻则编不过,重则运行时死活加载不了 GPU。这篇内容把关键配置、常见坑点和验证方法拆开讲清楚,希望能帮你把 GPU 版本的编译流程一次跑通。
一、CMakeLists.txt 链接配置修改(核心坑点集中区)
开启 CUDA 加速的编译,最折腾人的往往不是算法本身,而是链接规则、库依赖顺序和编译器兼容。下面这套配置方案已经实际验证过,可以稳定复用。
1.1 根目录 CMakeLists.txt
1.1.1 自动查找 MNN CUDA 相关扩展静态库
先确保 CMake 能正确找到 MNN 的 CUDA 扩展静态库,这一步是基础,漏了后边全白搭。
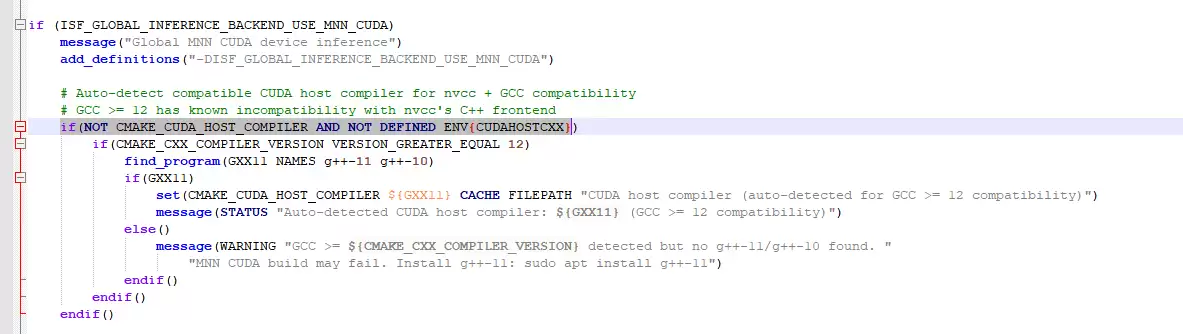
1.1.2 GCC ≥ 12 自动检测与 CUDA Host 编译器兼容处理
GCC 12 及以上版本跟 nvcc 之间有个已知的前端兼容问题,直接编译 CUDA 代码会报错。所以在开启 MNN CUDA 时,脚本会自动检测 GCC 版本,一旦发现版本 ≥12,就自动去找 g++-11 或 g++-10 来充当 CUDA Host 编译器,从源头避开编译失败。
1.1.3 全局链接库添加
把所有必要的全局链接库一并加进来,别等到链接阶段再手忙脚乱。
1.2 cpp/inspireface/CMakeLists.txt(核心修改)
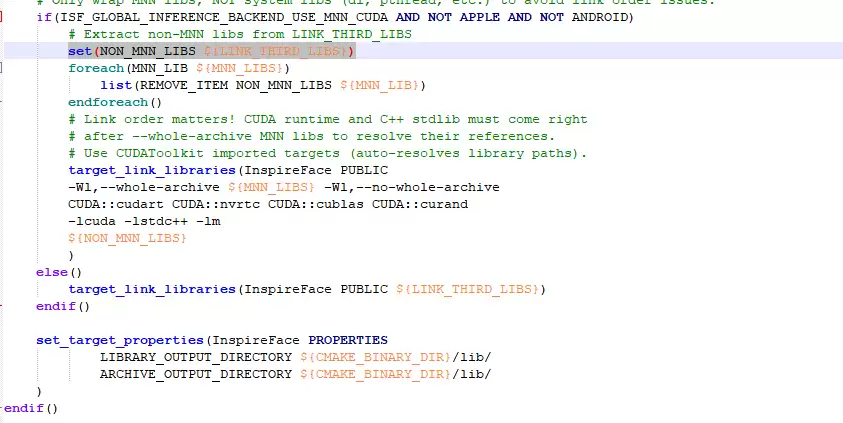
1.2.1 --whole-archive 必须只包裹 MNN 库
这个地方是典型的“一错就翻车”点。错误写法是把整个 `${LINK_THIRD_LIBS}` 都丢进 `--whole-archive` 里,像这样:
target_link_libraries(InspireFace PUBLIC -Wl,--whole-archive ${LINK_THIRD_LIBS} -Wl,--no-whole-archive)这么搞会把 `dl`、`pthread` 这类系统库也强行包裹进去,直接破坏 C++ 标准库的符号解析,编译阶段不出问题,运行时也会各种诡异崩溃。正确做法是把 `--whole-archive` 只对准 MNN 库:
二、编译脚本
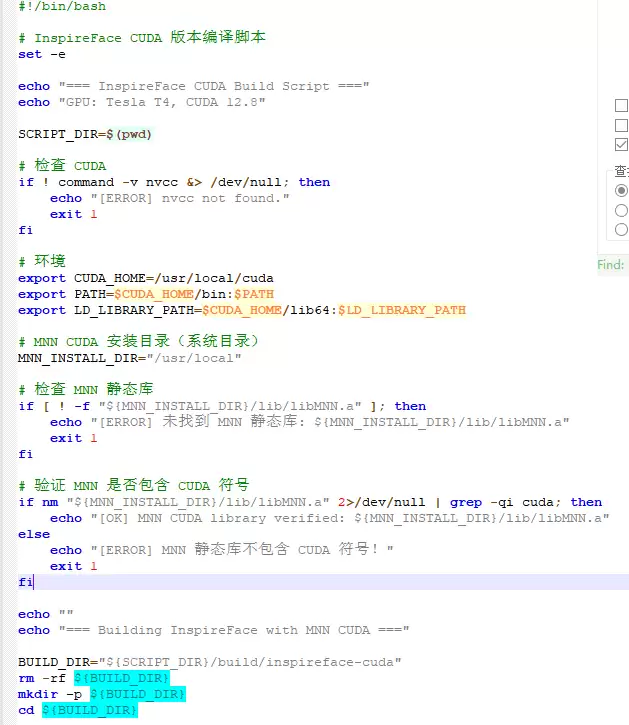
上面那些修改都做完之后,直接拿下面的脚本跑编译就行:

三、运行验证
编完了可别高兴太早,还得确认一下到底有没有正确加载 GPU。
3.1 正确输出示例
跑起来之后,关键看这两行输出:
InspireFace SDK [Community Edition] v1.2.3 Backend: MNN(CUDA)← 这条说明后端是 CUDA[inference_wrapper_mnn.cpp][Initialize][126]: Enable CUDA← 这条说明 CUDA 确实被开启了
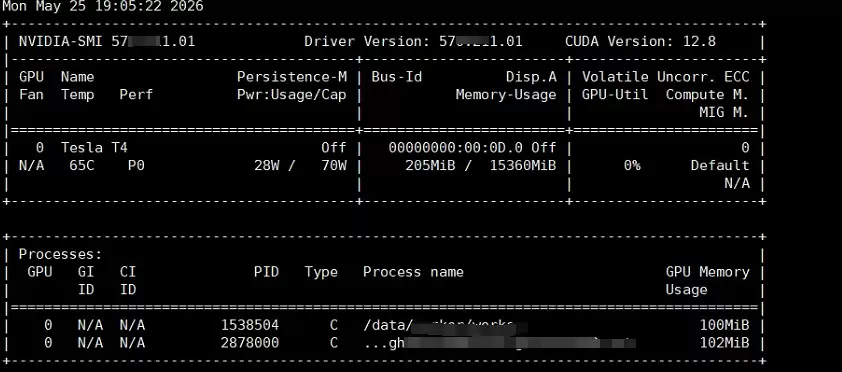
3.2 GPU 使用验证
最笨也最直接的方法:开一个终端监控 GPU 状态。
nvidia-smi -l 1运行程序的时候盯着看,GPU 使用率有没有跳起来,显存有没有被占用,一目了然。