Anthropic 昨天发布了最新旗舰模型 Claude Opus 4.8,官方公告称其在编码、袋里任务和专业工作方面表现更出色,具备持续处理长期任务所需的稳定性和自主性。SuperCLUE 团队基于中文大模型测评基准体系对 Claude Opus 4.8 进行了全面测试,以下是具体的测评结果与分析。
一、SuperCLUE 智能指数
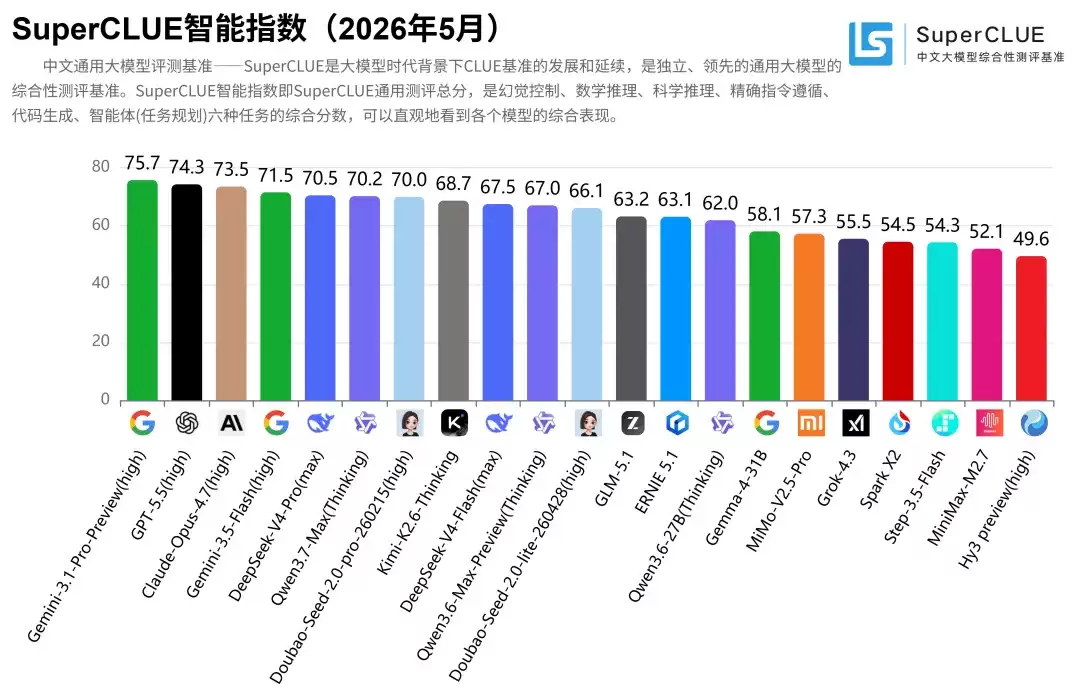
这个智能指数是一个综合得分,涵盖幻觉控制、数学推理、科学推理、精确指令遵循、代码生成、智能体(任务规划)六种任务,相当于看谁才是真正的“六边形战士”。即使在中文评测环境下,“御三家”依然牢牢占据领先位置。Gemini 后来居上,老牌技术公司的底蕴确实深厚。DeepSeek 紧随其后,国产模型和芯片随时有可能像汽车行业那样,在新的领域从追赶者变为领路人。这个榜单目前还未纳入新出的小米模型 Mimo,但从实际体验来看,它的表现也不错。
 图片
图片
二、模型象限图
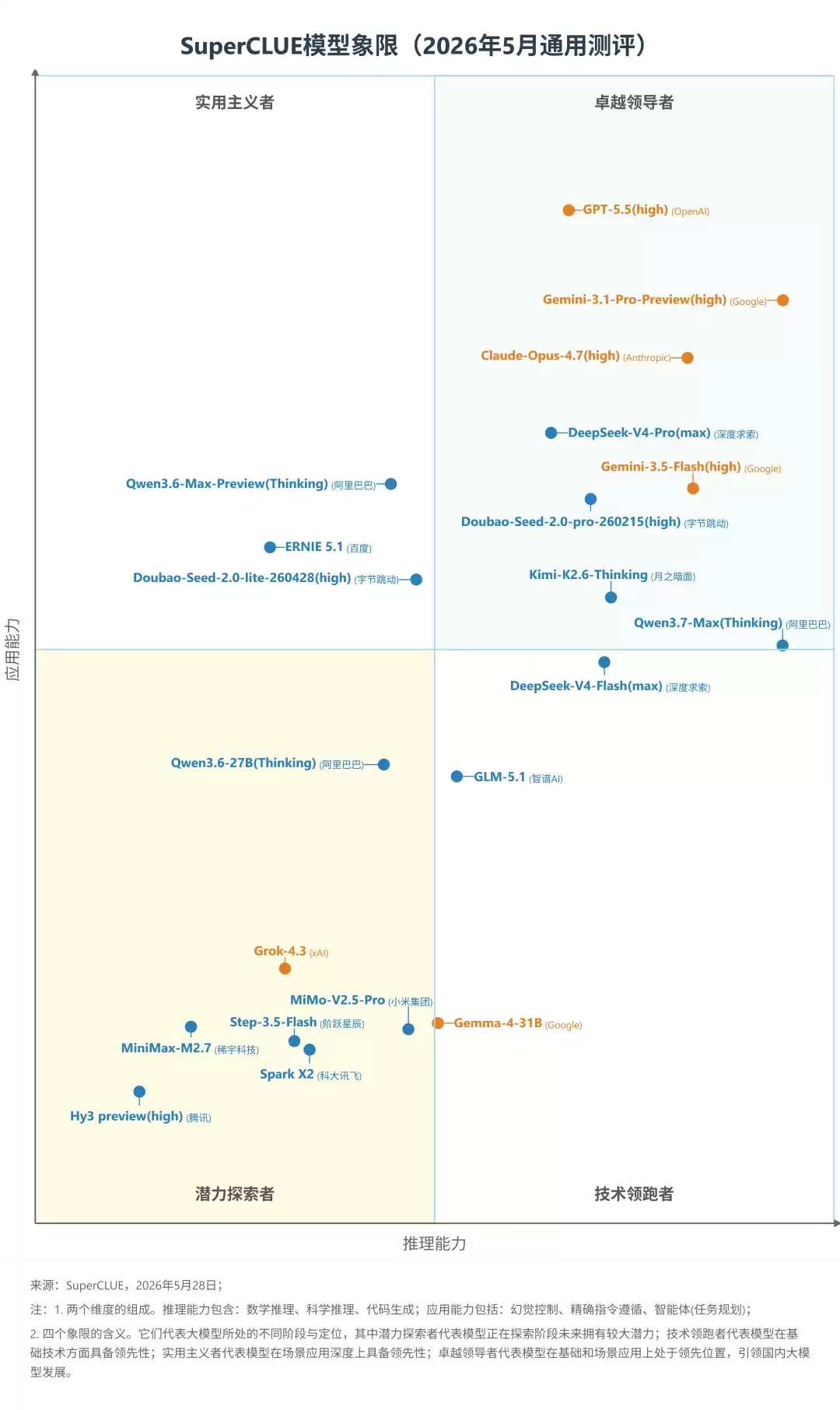
从应用能力和推理能力两个维度绘制各家大模型的擅长领域。新出的 Hy3 位于最末。
 图片
图片
三、性价比区间分布
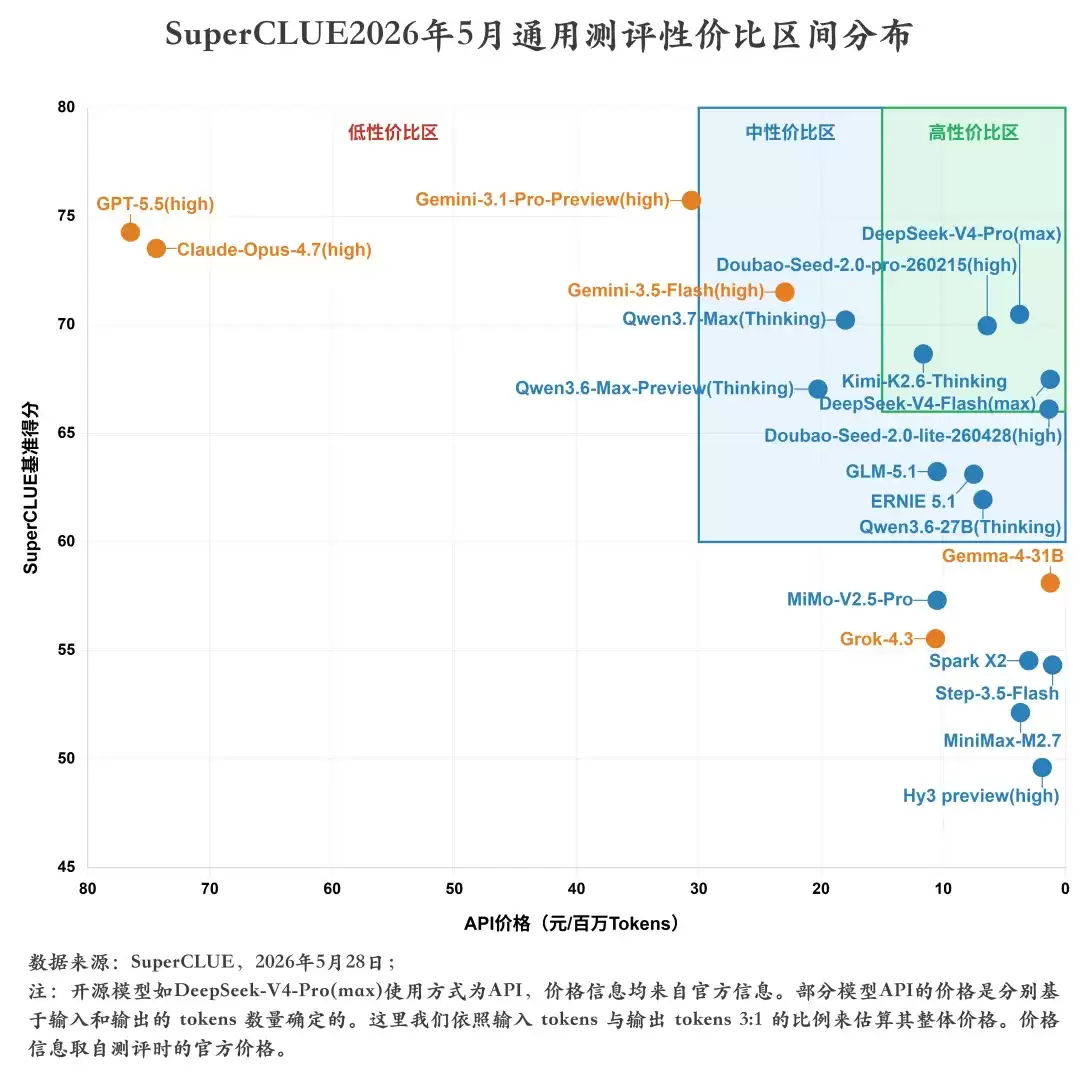
这部分的结论很直观:DeepSeek-V4-Pro 最具性价比。作为全球首家宣布降价四分之一的模型平台,它让大家能用上便宜又好用的 AI。
 图片
图片
四、推理效能区间分布
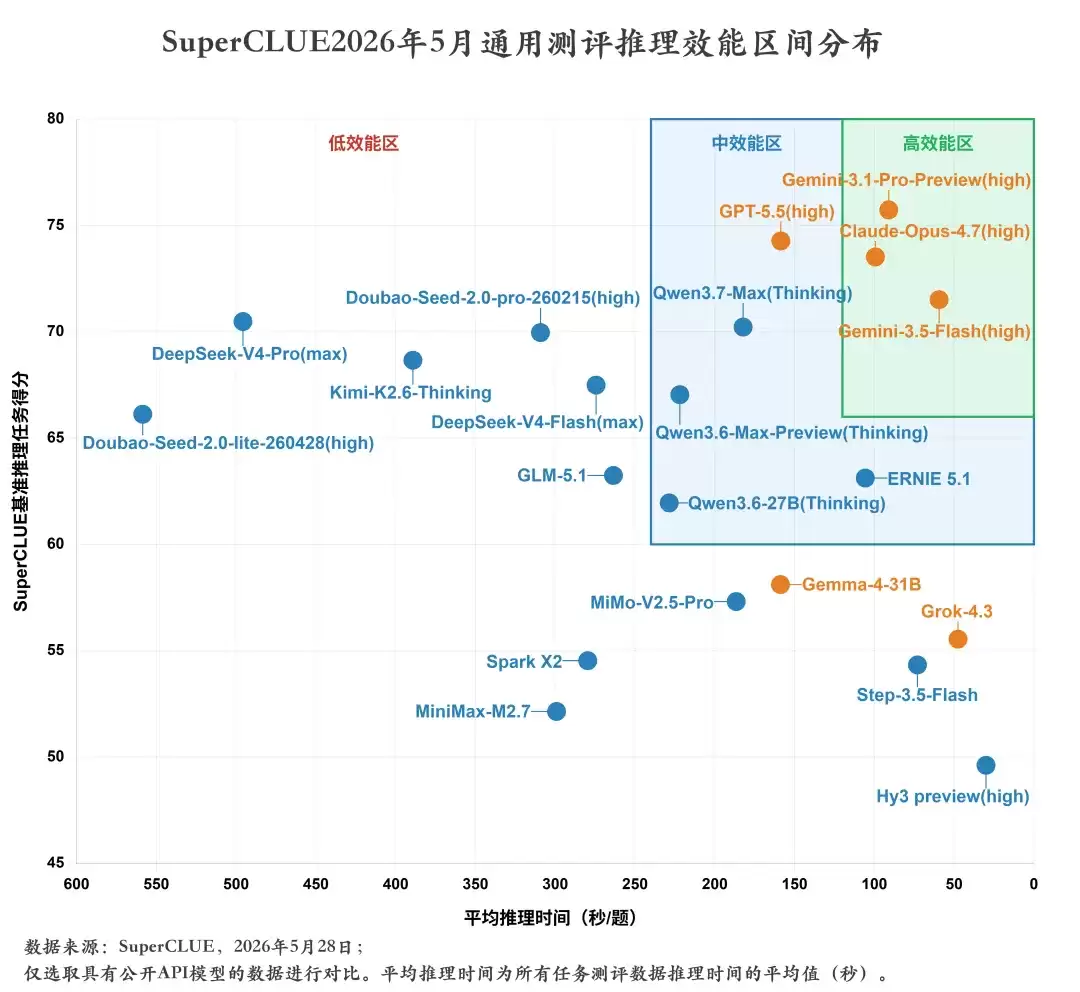
推理速度最快的仍然是“御三家”包揽前三。
 图片
图片
五、总体表现(2026年5月)
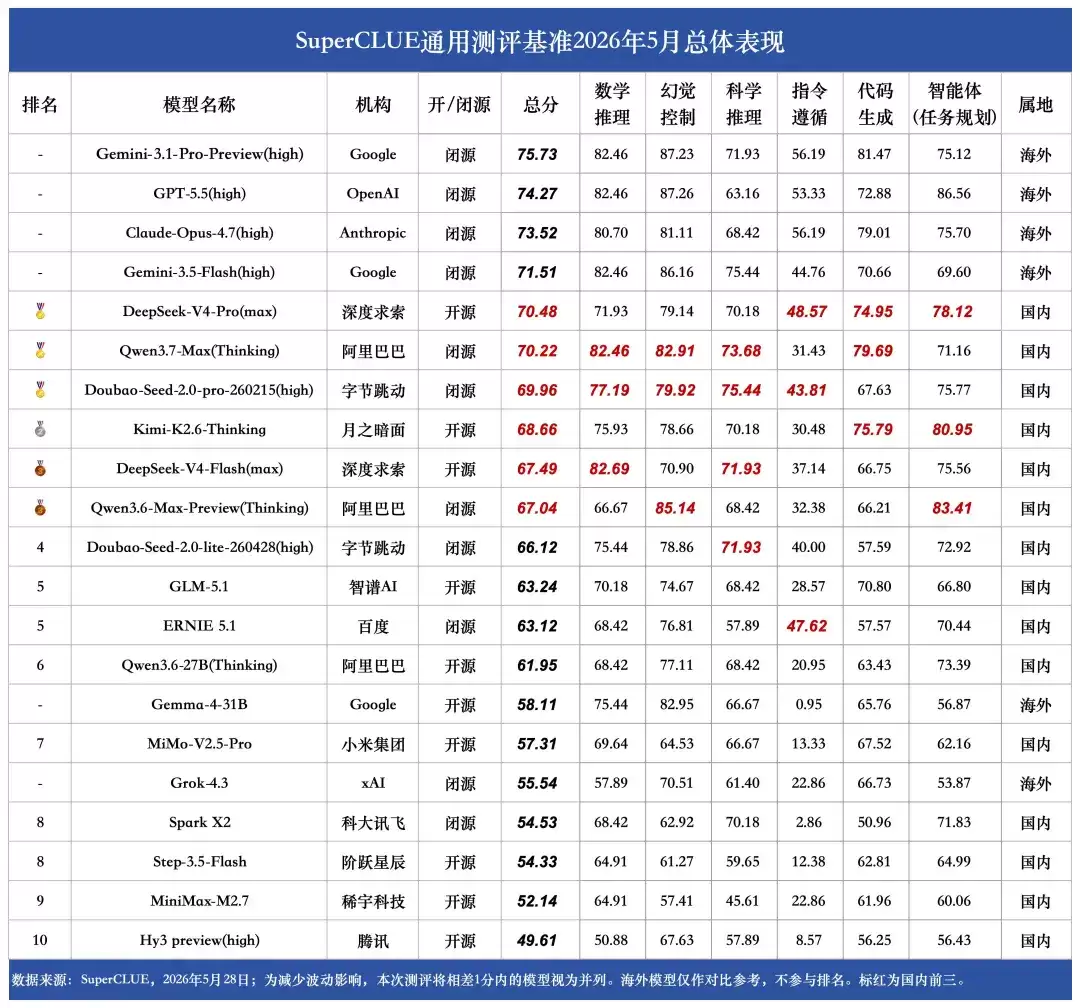 图片
图片
测评结果与分析
一、代码生成:Claude-Opus-4.8 以 83.58 分位列第一
领先 Gemini-3.1-Pro-Preview(81.47 分)超过 2 分,相比上个版本(Claude-Opus-4.7)提升超过 4.5 分。在 SWE(软件工程)子任务中表现尤为亮眼,取得 73.33 分,占据榜单第一,相比 Opus 4.7 提升较大,同时在独立函数生成和 Web Coding 子任务中均处于头部位置。
二、幻觉控制:87.48 分,榜单第一
相比 Opus 4.7 提升超过 6 分。
三、科学推理:77.19 分,榜单第一
相比 Opus 4.7 提升 8.77 分。
四、Claude-Opus-4.8 与 Claude-Opus-4.7 对比
新版在幻觉控制、科学推理和代码生成上均有较大幅度提升。其中幻觉控制从 81.11 分提升到 87.48 分(+6.37 分),科学推理从 68.42 分提升至 77.19 分(+8.77 分),代码生成从 79.01 分提升至 83.58 分(+4.57 分)。但在智能体(任务规划)、数学推理和指令遵循方面有一定下降,尤其是指令遵循任务,从 56.19 分降至 44.76 分,下降超过 11 分。
五、推理速度和性价比无明显变化
Claude-Opus-4.8 的推理耗时(97.76 秒/题)与上个版本(99.34 秒/题)几乎持平,依旧位于高效能区间。API 价格也和上个版本(74.38 元/百万 Tokens)保持一致,仍处于低性价比区间。
如今新模型的发布周期从半年缩短到数月,再到一个月,个别版本甚至只间隔几周。大家似乎都已经习以为常了——时不时看到某家发布新模型,最多看一眼,日常该用哪个还是继续用。这次第三方机构对主流大模型的评测结果,基本和日常使用体感差不多。至于 6 月份的 DeepSeek 新版本,值得关注。




