Kimi 团队最近发了一篇论文,悄无声息地改掉了 Transformer 里一个用了快十年的基础组件——残差连接。这东西几乎所有大模型都在用,但他们说有问题,而且已经修好了。
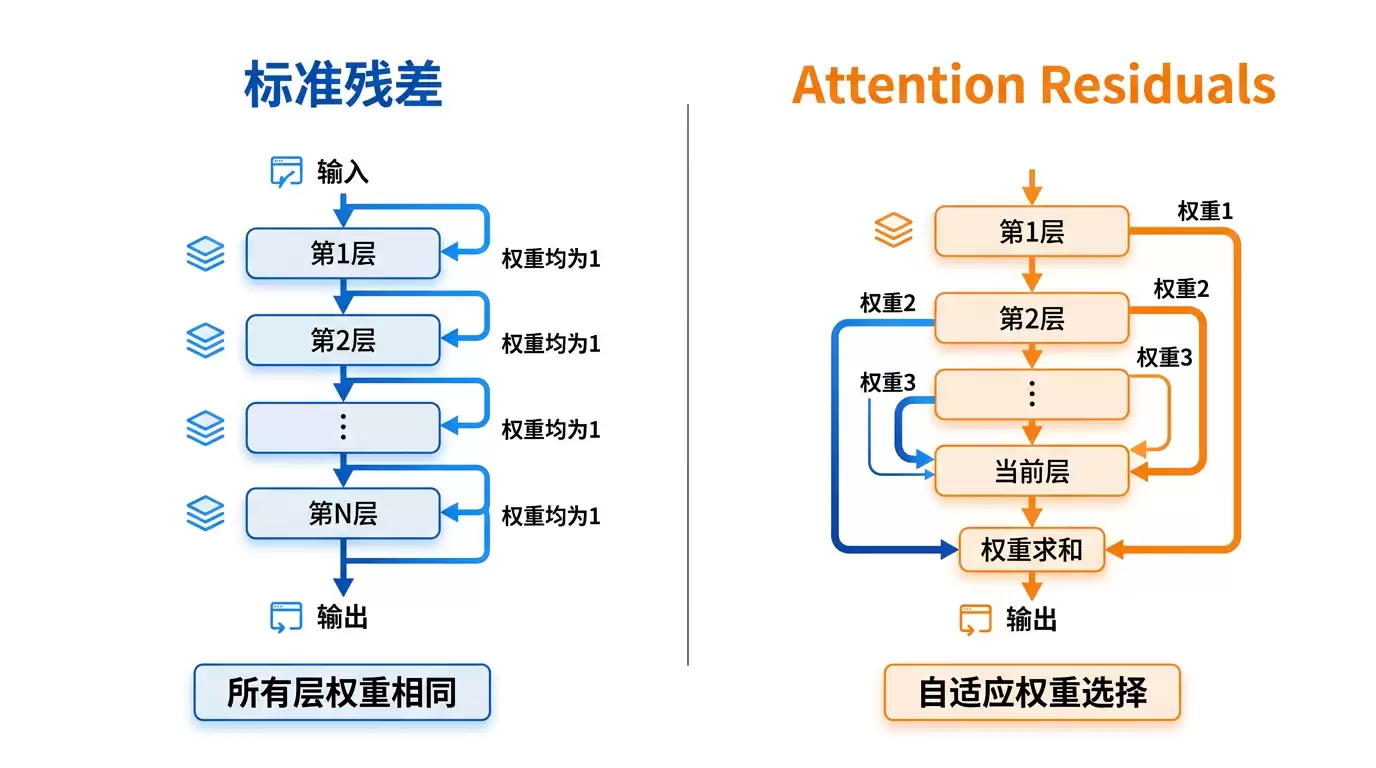
残差连接:一个「民主」但荒谬的设计
先解释一下残差连接到底是什么。
Transformer 每一层都在做计算,残差连接的作用就是把每一层的输出加回到下一层的输入里,保证梯度能顺畅向后流,防止深层网络训练崩溃。这个设计源自 2015 年的 ResNet,后来几乎被所有大模型原封不动地搬过来用。
问题出在哪?所有层的输出权重相同。第 1 层的结果和第 47 层的结果,对最终计算的贡献完全一样。
打个比方:这就像在一个委员会里开会,无论是十年前的老顾问还是刚进来的新成员,每人一票,永远平等。委员会越大,每个人的影响力越被稀释。一个 200 层的模型里,第 20 层的输出只有 1/200 的影响力。
这么一来,工程上就会出现两个头疼的问题:
- PreNorm 稀释:随着深度增加,每一层的贡献被越来越多的层稀释,早期层的信息传到最后几乎被淹没。
- 隐藏状态无限制增长:所有层输出的累积和随着深度增长,幅度越来越大,导致训练不稳定。
这两个问题不是没人注意到,而是过去大家默默接受了——毕竟效果还凑合,改动风险太大。
Kimi 团队说,这是个可以解决的问题,而且解法很优雅。
AttnRes:用注意力机制处理「自身历史」
他们的方案叫 Attention Residuals(AttnRes)。思路其实不复杂,一句话就能说清楚:
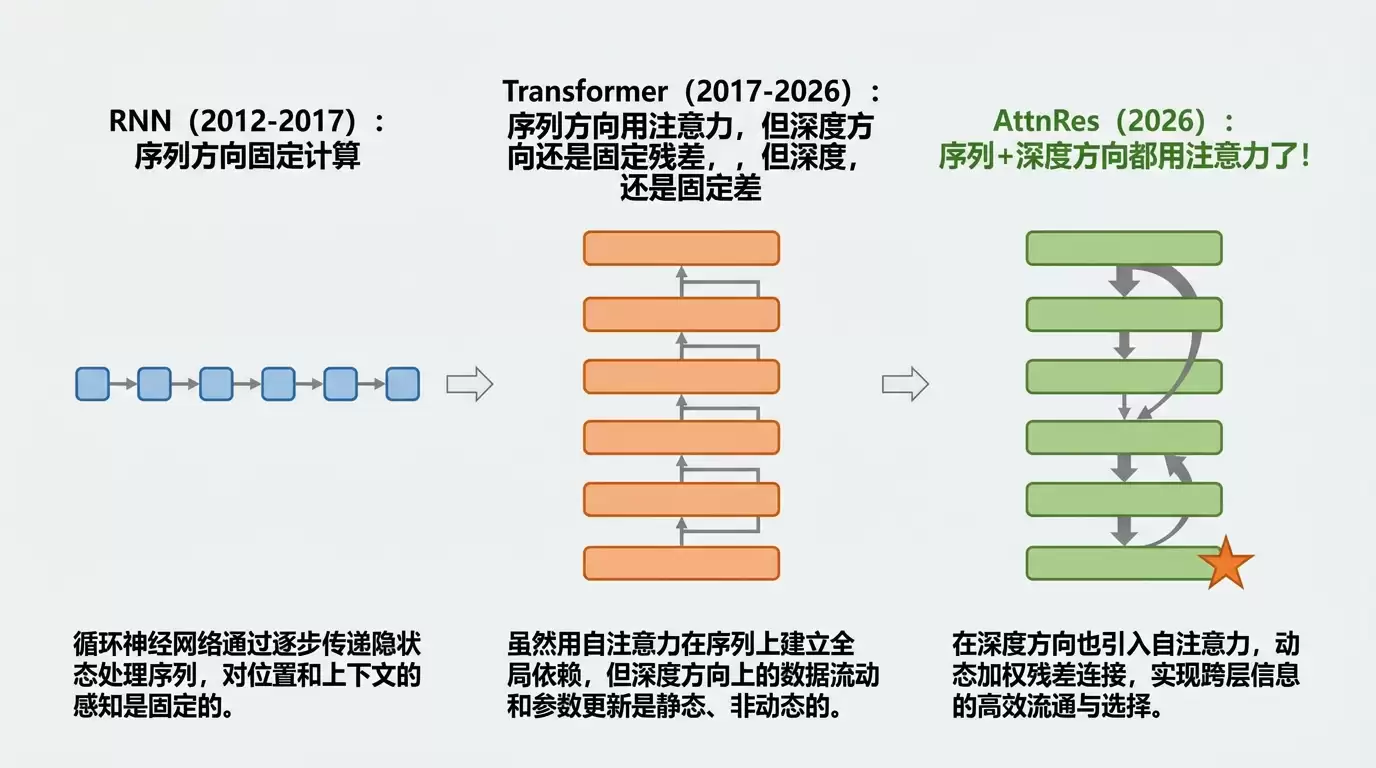
在序列方向,Transformer 用注意力机制让每个 token 选择性地关注其他 token。AttnRes 在深度方向做了完全同样的事——让每一层选择性地关注自己的处理历史。
具体到数学上,标准残差是把所有层输出相加(权重都是 1):
AttnRes 把权重变成了动态的 softmax 注意力:
每一层用一个学习得到的「伪查询向量」来决定 α 的大小——即当前层应该从哪些历史层汲取多少信息。这是输入相关的,不同的输入会产生不同的聚合权重。
效果很直接:输出幅度被限制住了,梯度分布更均匀,早期层的信息不再被淹没。

工程难题:内存怎么办?
如果每一层都要关注所有前层的输出,内存需求是 O(Ld)——L 是层数,d 是隐藏维度。对于一个 48B 的模型,这会直接炸掉任何正常的显存预算。
这也是为什么「让层关注历史层」这个想法之前有人提过,但没人真正大规模落地的原因。
Kimi 的解法是 Block AttnRes:
把模型的所有层分成 N 个块(约 8 个)。每个块内部还是用标准残差累积,跨块时才用注意力机制——但注意力只作用于块级别的「摘要表示」,而不是每一层的输出。
内存从 O(Ld) 降到了 O(Nd)。8 个块对应的内存开销和全层注意力相比几乎可以忽略,但实验显示它能恢复大部分全 AttnRes 的性能增益。
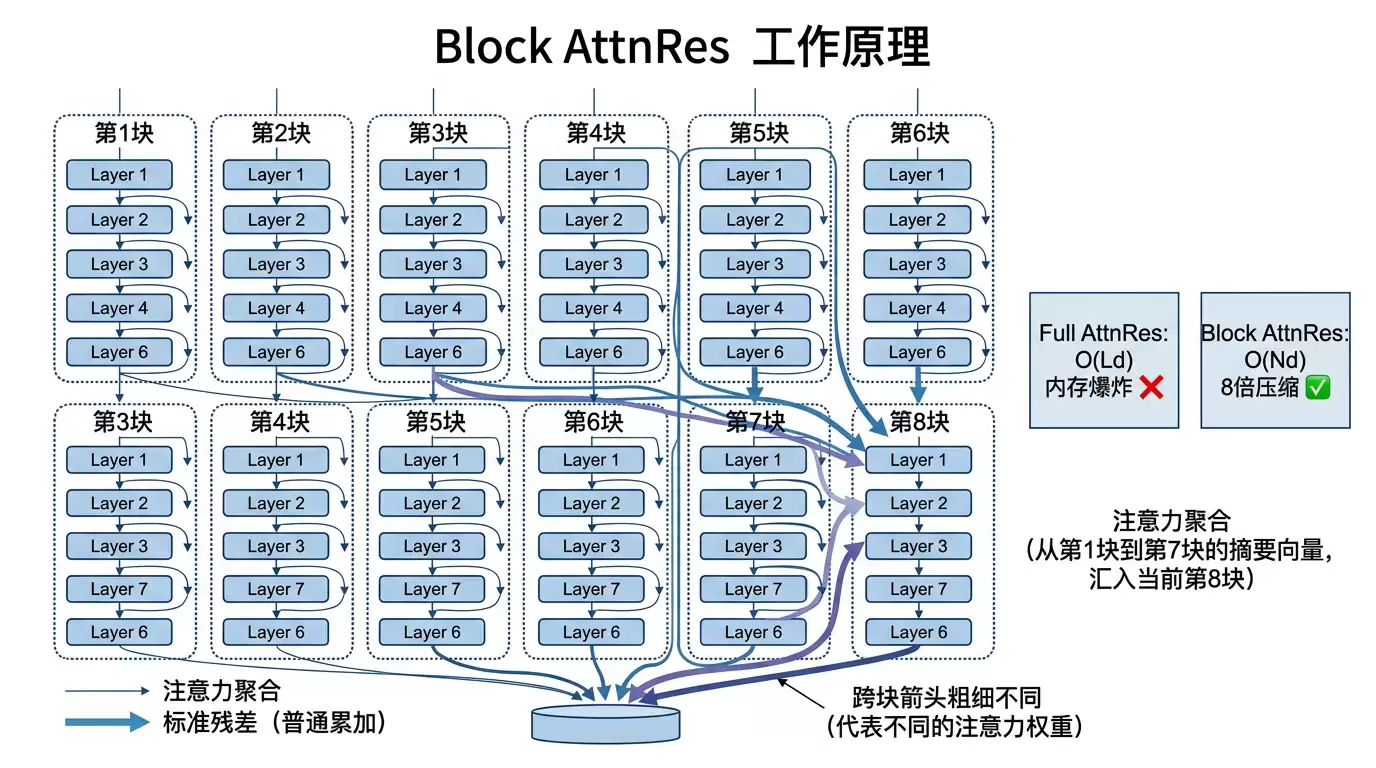
这是典型的「想法很美,工程让它落地」的故事。Full AttnRes 是理论最优,Block AttnRes 是实际可用——后者才是真正的贡献。
代码层面,Block AttnRes 的实现非常干净:
def block_attn_res(blocks, partial_block, proj, norm):
V = torch.stack(blocks + [partial_block]) # [N+1, B, T, D]
K = norm(V)
logits = torch.einsum('d, n b t d -> n b t', proj.weight.squeeze(), K)
h = torch.einsum('n b t, n b t d -> b t d', logits.softmax(0), V)
return h
整体结构不变,两个 einsum 解决问题,推理延迟增加不到 2%。
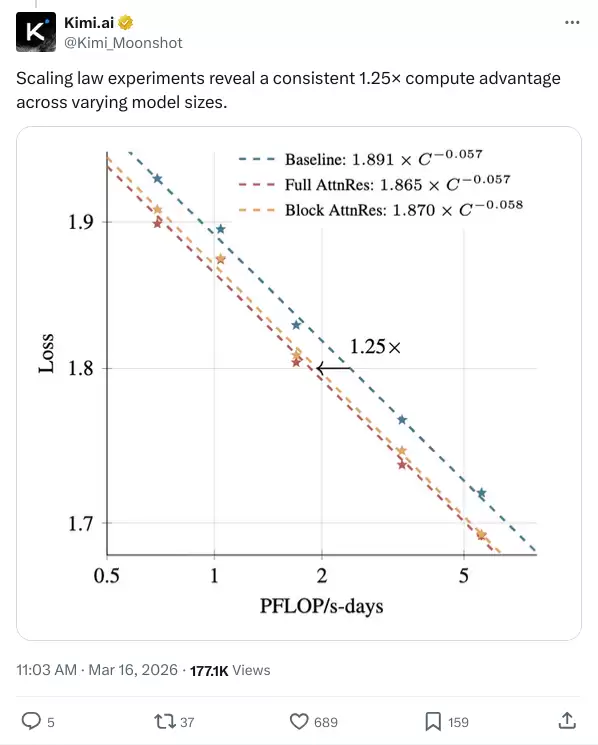
实验数据:1.25x 是什么概念?
他们在 Kimi Linear(48B 参数总量,激活 3B 的 MoE 架构)上用 1.4 万亿 token 预训练,对比标准残差和 Block AttnRes:
- 计算效率提升 1.25x:意思是加了 AttnRes 的模型,达到相同的下游任务性能,只需要对照组 80% 的计算量。换句话说,你用同等算力,效果相当于多训了 25% 的 compute。
这不是小数字——对于训练成本动辄几千万美元的大模型来说,25% 是实实在在的钱。
Scaling law 实验也支持这个结论——在不同规模的模型上都能观察到一致的改善,说明这不是某个特定规模点的偶然现象。
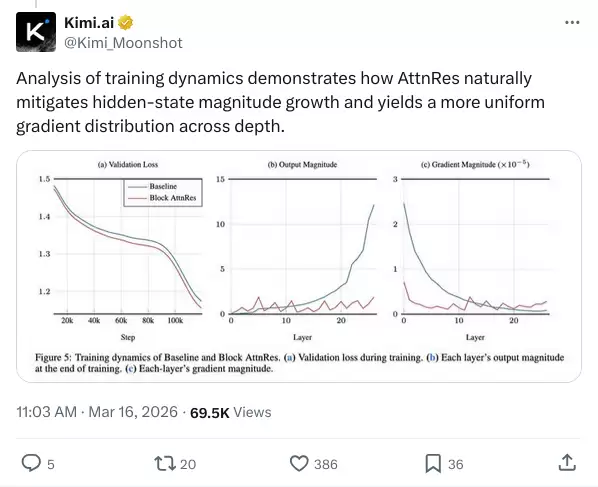
训练动态方面,AttnRes 模型的隐藏状态幅度增长被有效控制,各层的梯度分布更均匀。这意味着更稳定的训练,减少了调参难度。
这个工作放在大背景下意味着什么?
有个有趣的历史视角。
神经网络架构史上有几次重要的「用注意力替代固定规则」:
- Transformer 用自注意力替代 RNN 的顺序处理(序列方向)
- Mixture of Experts 用门控网络替代固定的层路由(宽度方向)
- AttnRes 用注意力替代固定的残差累积(深度方向)
有人评论说,这是 Transformer 终于把注意力机制真正用到了所有维度。这个说法有点浪漫化,但也确实点出了问题——过去残差这块是被「特赦」的,AttnRes 把它也纳入了学习范畴。
当然也有泼冷水的声音:改善是真实的,但 1.25x 到底算多大的突破?Scaling law 实验是在相对小的模型上做的,48B MoE 只激活 3B,和真正的大规模训练还有距离。实际部署中 Block 的数量、块大小的选取,也有调参空间尚未完全探索。
一句话总结
AttnRes 把「哪些历史层信息应该被当前层使用」这个判断,从写死的「一律平等」改成了「模型自己学」。在 1.4T token 的训练规模上,这换来了 25% 的计算效率提升,推理延迟几乎不变。
如果后续在更大规模的训练上复现,这个工作大概率会进入各家大模型的标配改造清单。