在日常交流中,经常有不少朋友对LLM里几个基本概念感到混淆——向量、词向量、句向量,它们到底有什么区别?其实把这些底层逻辑理清楚,后面搭建RAG架构时,思路会清晰很多。今天先聊聊这几个核心术语。
一、什么是向量
向量在大语言模型里占据非常重要的位置。从数学定义上看,向量同时具备大小和方向,但在AI这个领域,你完全可以把它简化为:一个固定长度的数字列表。
举个容易理解的例子。假设你在玩一款RPG游戏,每个角色都有自己的属性面板:
战士:力量 99,智力 5,敏捷 30
法师:力量 5,智力 99,敏捷 20
把这些属性写成数组:
战士 = [99, 5, 30]
法师 = [5, 99, 20]
[99, 5, 30] 这串数字,就是战士这个角色的“向量”。在这个例子里,向量一共有3个维度(力量、智力、敏捷)。它不仅代表数值,还意味着这个角色在“属性空间”里占据着一个独特的位置。

如上图所示,游戏里的任何一个角色,都可以在这个三维坐标系中找到属于自己的点。
理解了这层关系,接下来就好办了。
二、什么是向量化
向量化,说白了就是把一个具体事物转换成计算机更能理解的向量形式的过程。
现在想往游戏里新增一个角色【骑士】,该怎么做?你需要分析它的特点,把这些特点转换成力量、智力、敏捷这三个属性的数值。这个“打分”的过程,就是向量化。
骑士_Vector = [85, 40, 20]
这样一来,数据库里就有了三个点:
战士 [99, 5, 30]
法师 [5, 99, 20]
骑士 [85, 40, 20]
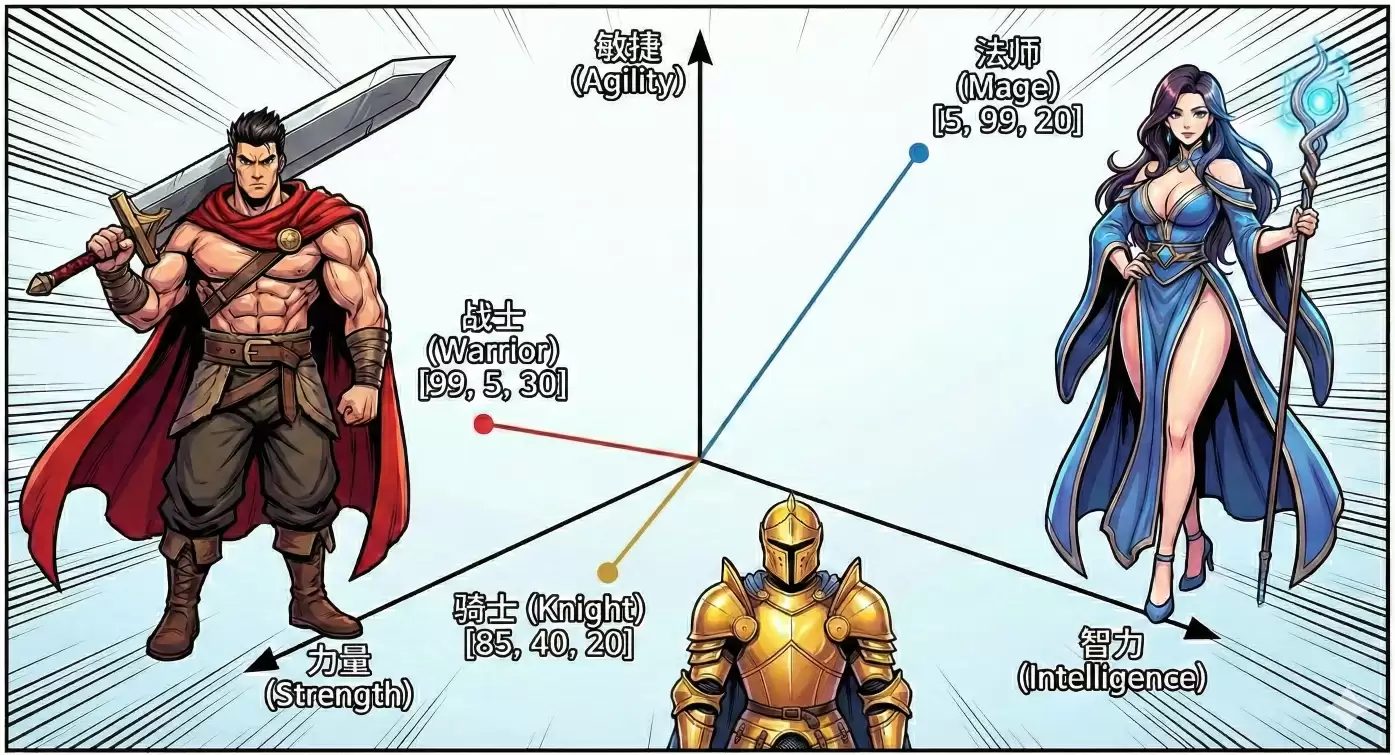
计算机很快就能发现:骑士和战士在“力量”维度上数值接近,它们在空间中的距离也更近。就这样,计算机拥有了最基础的判断“相似性”的能力。
作为人类,你可能凭知觉就知道骑士和战士更像,但计算机是通过坐标计算得出这个结论的。这就是向量化让计算机理解语义的核心奥秘。
那么,这和大语言模型有什么关系?
关系非常直接。LLM训练的过程,本质上就是把人类的各种文章、文档向量化的过程。
三、对人类语言的向量化评估
前面的例子把“向量化”解释得很直观,但我们需要把视野扩大一些。现在输入的不再是RPG游戏的角色名称,而是人类世界里无处不在的语言文本:
- 一句问候:“你好”
- 一首情诗,100字
- 一篇技术文档,500字
- 一段代码,1000字
如果能把各种语言文本作为输入,稳定地输出一段描述该文本的向量坐标,计算机是不是就能理解人类语言的本质了?
理论上当然可以,但三个维度远远不够。人类的语言太过复杂,于是维度开始爆发——计算机开始使用1024个维度、1536个维度甚至更多来描述一段话的特征。
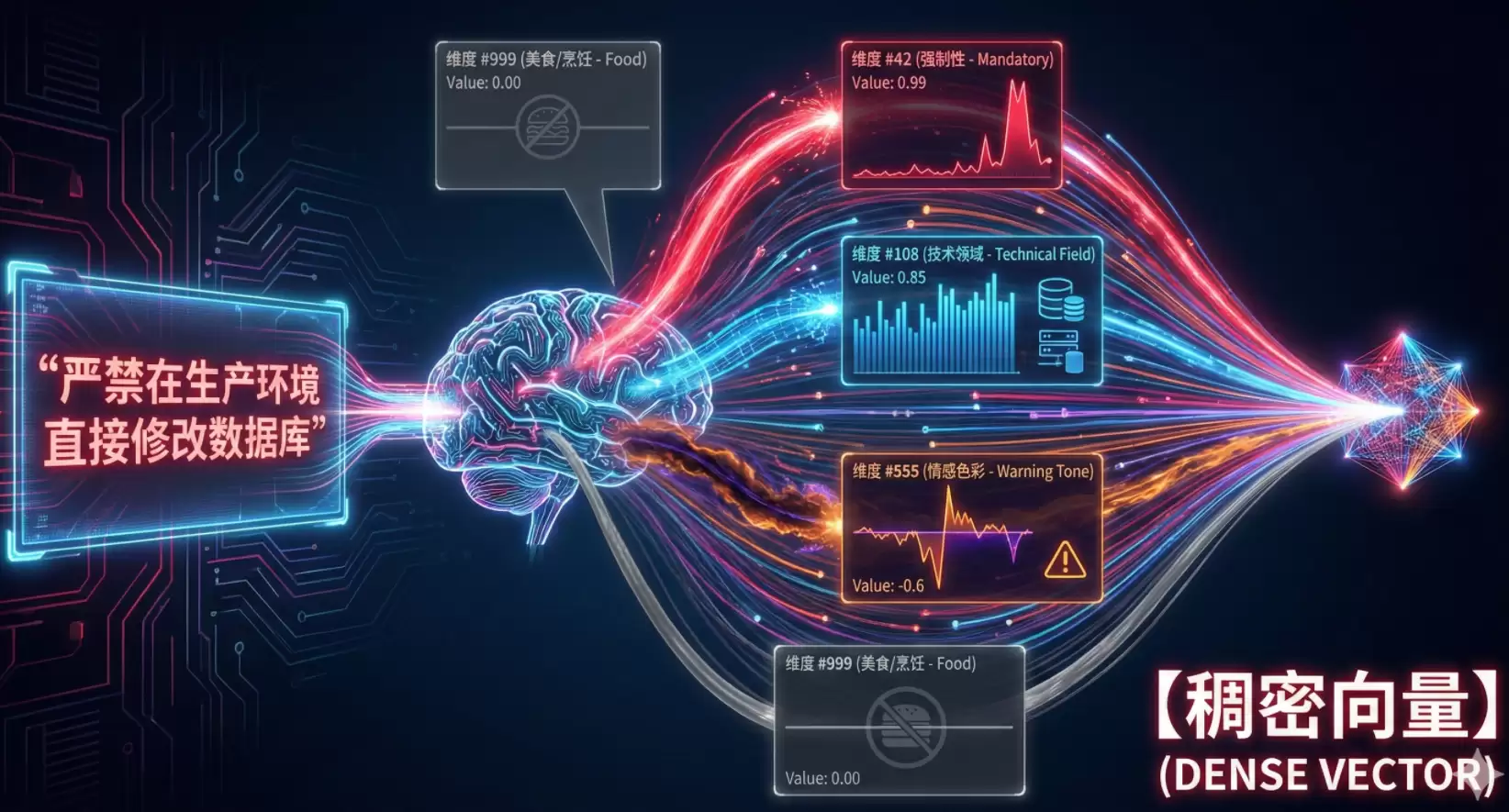
3.1 稠密向量
想象一下,你把公司那条《严禁在生产环境直接修改数据库》的规定扔给模型。模型读到这句话时,它的1536个维度探测针会疯狂跳动。虽然我们无法知道每根针具体代表什么,但通过数学分析可以发现,模型实际上在评估以下这类“抽象特征”:
特征维度 #42(可能与“强制性”有关):语气非常强硬(“严禁”),这个维度的数值飙升到0.99。
特征维度 #108(可能与“技术领域”有关):包含“数据库”“生产环境”,数值为0.85。
特征维度 #555(可能与“情感色彩”有关):警告性质,带有负面后果暗示,数值可能是-0.6。
特征维度 #999(可能与“美食/烹饪”有关):与文本没有关系,数值为0.00。
就这样,模型把这句话压缩成了一个“高强制性+纯技术领域+警告语气”的数学坐标点。这类富含信息量和特征评估的向量,有一个专业名称:稠密向量。
3.2 词与句,流派之分
也就是在这个阶段,文本的计算方法衍生出两个思路:
思路A:先拆词,然后对每个词进行向量化。
[我]训练一个向量,[喜欢]训练一个向量,[你]训练一个向量,然后把三个向量形成一个矩阵进行存储训练。这种思路被称为词向量(Word/Token Embedding)。思路B:不拆词,对一整句话进行向量化。
[我喜欢你]四个字只训练出一个向量。这种思路被称为句向量(Sentence Embedding)。
哪种流派更厉害?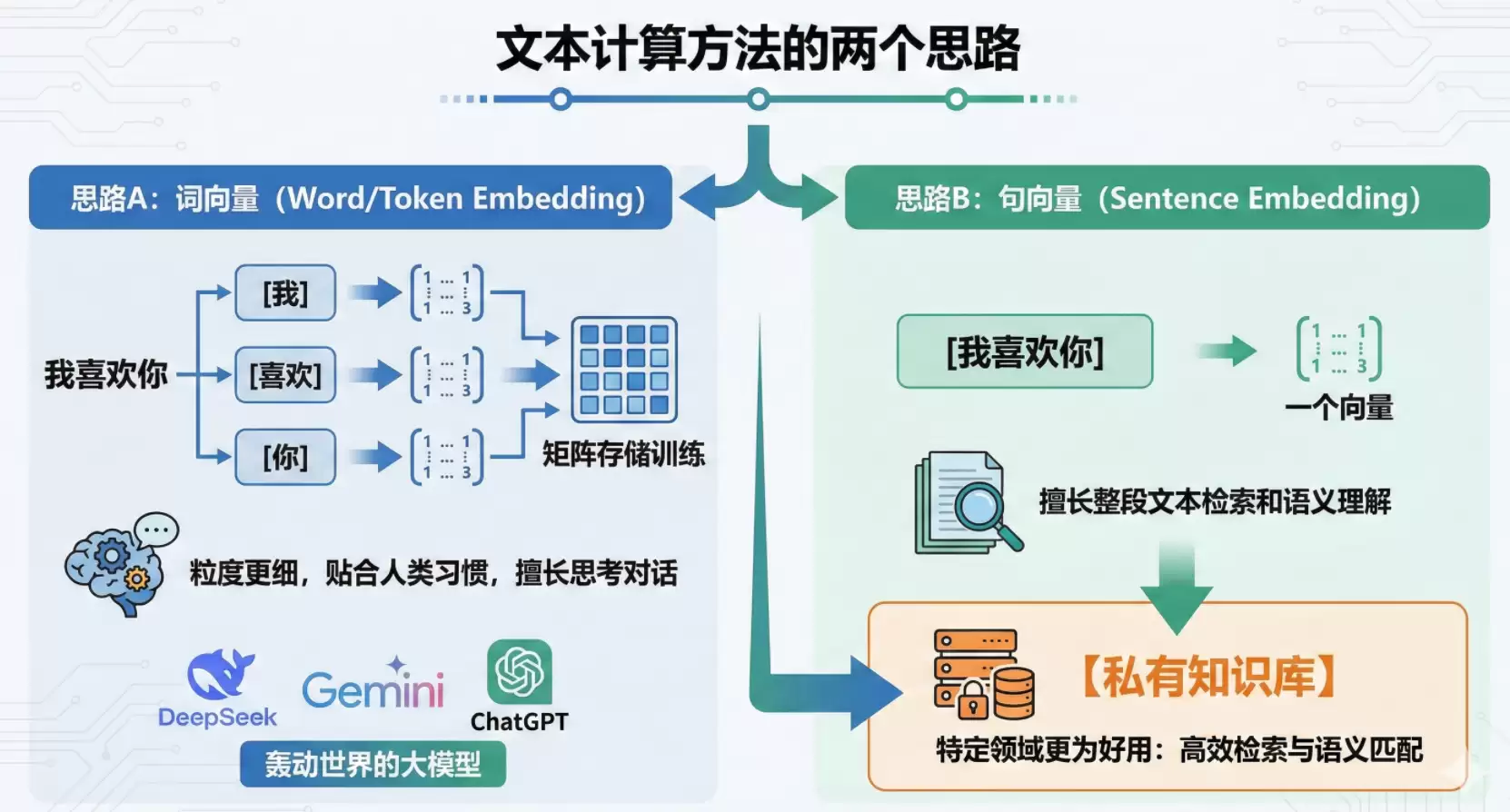 很显然,【词向量】粒度更细、更复杂,更贴合人类说话的习惯——一个词一个词地学习、理解、组装输出。像DeepSeek、Gemini、ChatGPT这些轰动世界的大模型,都基于这一思路,擅长思考以及与人类对话。
很显然,【词向量】粒度更细、更复杂,更贴合人类说话的习惯——一个词一个词地学习、理解、组装输出。像DeepSeek、Gemini、ChatGPT这些轰动世界的大模型,都基于这一思路,擅长思考以及与人类对话。
那【句向量】就一无是处吗?当然不是。
【句向量】在特定领域同样大放异彩。它擅长整段整段地进行文本检索和语义理解,在后续要介绍的场景——私有知识库——当中,它反而更加好用。
四、【句向量】:天生我材必有用
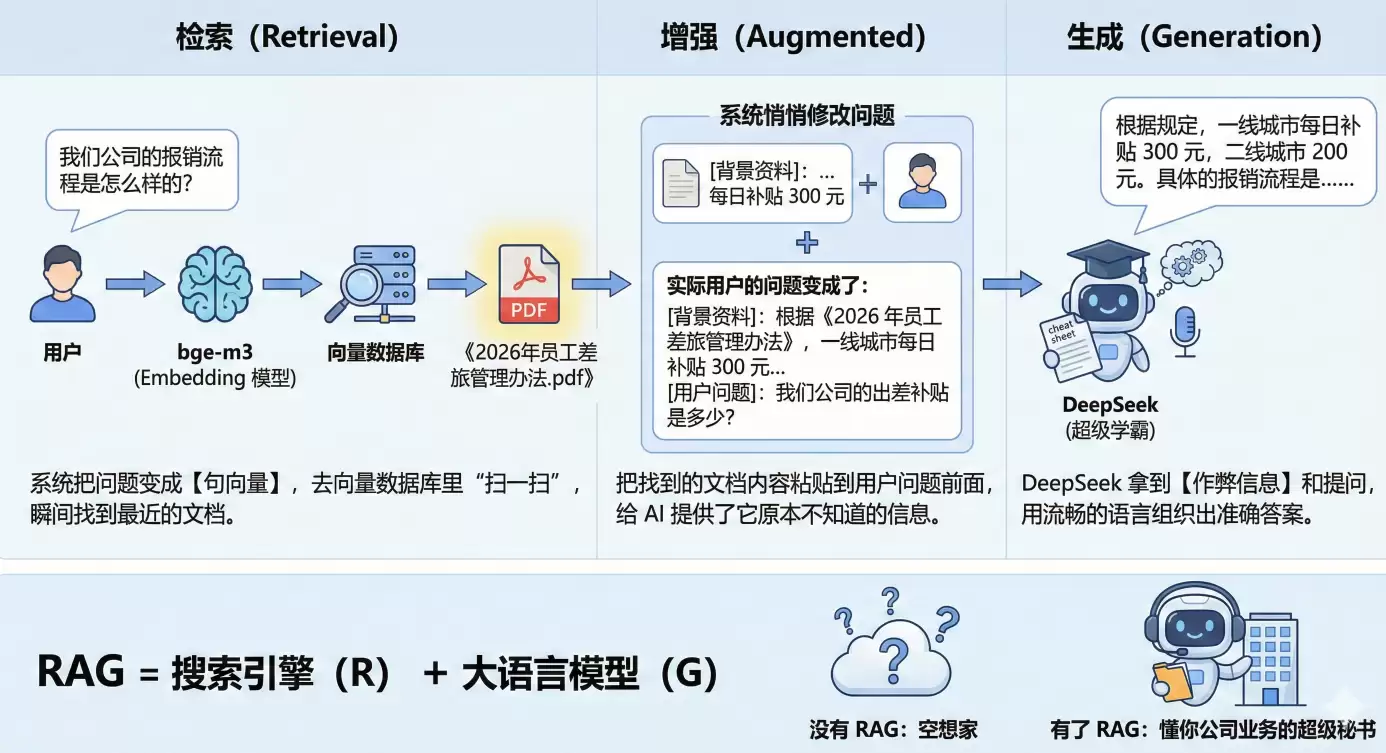
假设你有很多企业内部文档、私人文档需要形成一个知识库。你并不需要和这些文档对话,而是要快速找到文档中相关度最高的位置。在这个场景下,基于一句话进行向量化的【句向量】反而具备了优势——它的向量本身就是基于一段一段的话进行特征标注的。
在快速检索知识区域方面,【句向量】相比【词向量】具备以下优点:
数学上可行:把长短不一的文本变成固定长度的“条形码”,才能计算距离。
语义上精准:提取的是中心思想,而不是碎片化的词。
工程上极速:让百万级检索能在毫秒级完成。
正因为这些特点,【句向量】成为了构建私有材料库和知识库检索的核心技术。
只是本地检索会不会太没想象力?检索出来后,再把准确的文本塞到大模型(比如DeepSeek)的对话里,效果会更加惊艳。
下一步预告
基于本章的理论,下次将梳理RAG架构所需要的模型、组件以及关键步骤。敬请期待。





