上周跟一个在大厂做测试架构的朋友吃饭。他叹了口气说,现在组里二十多个测试工程师,每天有一半的时间在“接活”——产品改个字段,开发换个状态码,用例就炸一片。改完这套,另一套又红了。
他说,我缺的不是写代码的人,是能让用例自己活过来的人。
这不是个例。过去半年,我跟十几个测试团队聊过,发现一个共性问题:大家都在用AI生成测试用例,但生成完了,维护的问题原封不动回来了。生成得越快,烂得越快。
原因很简单。主流做法是“人驱动AI生成”,但变化发生后,没有机制让AI“知道”变化,更没有机制让用例“自己”跟上变化。
我去年开始摸索另一条路,先叫它Skills-first。核心不是让AI帮你写用例,而是让AI成为一个可编程的、能感知变化的、能直接操作测试工具的“测试执行体”。
半年跑下来,手底下三个项目的接口测试用例,增删改查全由Skills驱动。我的角色从“用例维护者”变成了“规则定义者”。
这篇文章会把整套设计模式拆开,包括架构、流程、代码级别的实现思路。万字,不注水。
测试设计模式的代际更替
软件测试发展这些年,接口自动化设计模式大致走了三代。
第一代:脚本模式。每个人写自己的脚本,用例是孤岛。优点是灵活,缺点是维护全靠人脑记住哪里用了哪个字段。
第二代:数据驱动+关键字驱动。把测试数据和逻辑分离,用Excel或YAML管理。优点是部分复用,缺点是接口变了,你改数据文件,改关键字定义,改调用链,还是手工。
第三代:BDD/DSL模式。用自然语言描述场景,底层映射到代码。优点是可读性强,缺点是自然语言和真实接口之间有一层“翻译层”,这层还是手工维护的。
这三代的共同缺陷是什么?
本质是:变化发生后,更新链路上必须有人。
需求变更 → 开发改代码 → 接口定义变 → 测试人员知道 → 测试人员用IDE/Postman/Excel改 → 运行验证。每一步都依赖人的注意力和执行力。
Skills-first想解决的就是这件事:把“知道变化”和“执行更新”这两步从人身上剥离出来。
测试设计模式的代际跃迁,不是从手工到半自动,而是从人驱动到事件驱动。
Skills-first不是什么炫技,是不得不
有人会问:用CI/CD触发脚本跑用例更新不就行了?写个Python脚本,监听Swagger变化,自动改断言。为什么非要Skills?
因为脚本只能处理“确定性”变化。
举个例子。接口响应里有一个list字段,之前永远返回数组,现在在某些边界条件下返回null。一个普通脚本看到类型从Array变成Array|null,可以修改断言从assert.isArray改成assert.isArray or assert.isNull。这能搞定。
但如果变化是:status字段的枚举值从[0,1,2]变成[PENDING, SUCCESS, FAILED],并且业务规则变了——之前status=2表示失败,现在FAILED还要区分是系统失败还是业务失败,需要关联另一个字段fail_reason。
脚本做不到这种程度的“理解”。它不知道2和FAILED是同一件事,不知道新加一个断言去检查fail_reason的存在性。
这就是Skills入场的地方。
大模型具备语义理解能力。它读变更日志或OpenAPI差异,能判断出“枚举值改了但含义没变”还是“枚举值改了且业务逻辑变了”。它甚至能根据字段命名推断出fail_reason应该和FAILED状态一起出现。
但大模型也有缺陷:不确定性强,同一个输入可能给不同输出,而且不擅长精确操作工具。
Skills-first的设计哲学是:用大模型的语义能力做模糊判断,用代码做精确执行。两者通过一个“结构化指令集”桥接。
具体来说,Skill负责输出一个中间表示,比如JSON Patch或者一套自定义的测试操作原语。这些原语是确定性的,由脚本或Postman API执行。大模型不做精确的字符串替换,只做“判断应该做什么操作”。
核心在于:
- 变化感知:Skill定期拉取OpenAPI或解析代码diff
- 智能决策:Skill输出[{op: "update_assert", path: "response.status", from: 2, to: "FAILED"}, {op: "add_assert", condition: "status==FAILED then fail_reason exists"}]
- 自动化执行:一个轻量执行器解析这些操作,调用Postman API/JMeter API完成更新
这个模式跑起来后,人的工作退到两件事:审核Skill输出的操作序列,以及处理那些Skill标记为“不确定”的变化。
三层架构:感知、决策、执行
下图是Skills-first模式的核心架构。每个层解决一类问题。
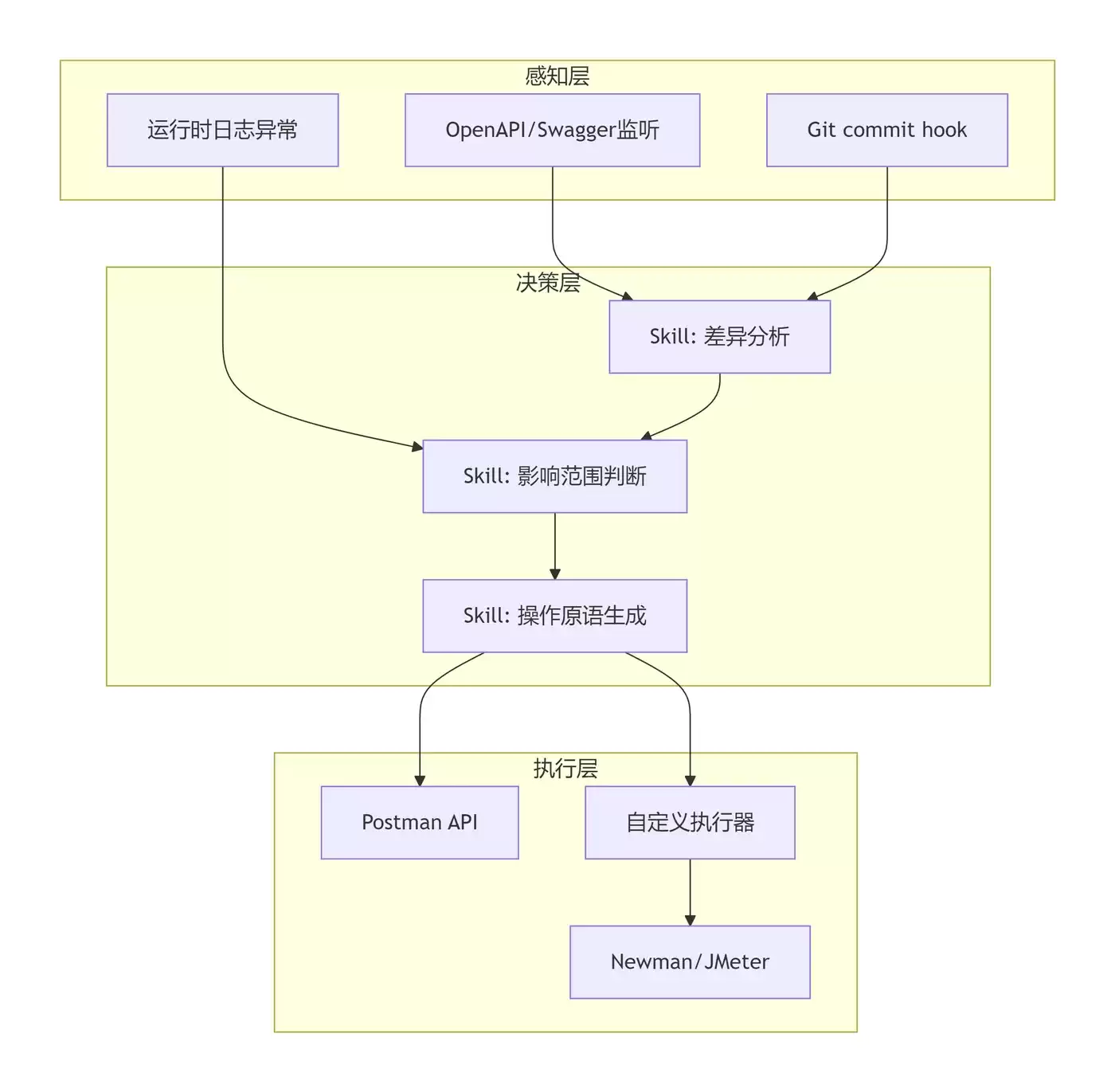
感知层:不止是接口定义
很多团队只监听接口定义变化,但实际引发用例失效的还有两类来源:
- 代码注释里的隐式约定。比如开发在PR里写“user_id现在支持字符串了”,但OpenAPI没改。Skill需要同时拉取PR描述和Commit message,用模型判断是否需要更新用例。
- 运行时行为。线上日志显示某个接口在某些条件下返回了文档没声明的字段。Skill定期扫描日志,发现未定义字段,主动建议新增断言。
感知层做得越宽,决策层就越少遇到意外。
决策层:Skill的核心是“原语化”
Skill不直接改用例。它输出一个操作原语列表。我们定义的七种原语:
- update_request_body:修改请求体中的某个字段
- update_assert_path:修改断言的JSON Path
- update_assert_value:修改断言期望值
- add_assert:新增断言
- remove_assert:删除断言
- add_pre_request_script:新增前置脚本
- update_variable:修改Collection变量
每个原语包含充分的信息,让执行层不需要再做业务判断。例如update_assert_value会带上old_value和new_value,以及一个置信度分数。置信度低于0.8的原语会进入人工审核队列。
执行层:工具无关
执行层不关心操作是从Skill来的还是从人来的。它只认原语。这层可以适配Postman、JMeter、Karate,甚至可以接自己的测试框架。
我们选择Postman API因为它有完整的Collection操作接口。一个Python脚本几十行就能实现所有原语。
优势在于:Skill换掉、工具换掉,执行层只需要重新实现一套原语映射,上层逻辑完全复用。
Skills-first不是把大模型塞进测试流程,而是用原语隔离语义和精确,让AI做AI擅长的事,代码做代码擅长的事。
一次真实迭代的全流程回放
拿一个真实案例。用户服务的一个接口/api/user/info,原来返回:
{"uid": 12345, "nick": "张三", "level": 5}
用例里断言:
- uid是数字
- nick不为空
- level在1到10之间
某次迭代,开发做了三处改动:
- uid从数字变成字符串(业务原因:兼容第三方ID)
- 增加vip_level字段,与原来的level并存
- nick改为可选字段,未设置时返回null
传统做法:测试人员在群里收到通知,打开Postman,找到七八个引用这个接口的用例,挨个改断言,加新断言,改前置数据生成。耗时两小时。
Skills-first的做法:
感知层:CI流水线里,OpenAPI变更推送到一个Webhook。Skill被唤醒,拿到新旧两份JSON Schema。
决策层:Skill分析差异,输出操作原语:
[ {
"op": "update_assert", "target": "response.uid", "from_type": "integer", "to_type": "string", "action": "modify_assertion_typeof", "confidence": 0.95 },
{
"op": "add_assert", "target": "response.vip_level", "assert_type": "range", "range": [0, 10], "confidence": 0.9 },
{
"op": "modify_assert", "target": "response.nick", "from_assert": "not_null", "to_assert": "or(null, not_empty)", "confidence": 0.85 }]
注意第三个原语置信度稍低,因为“可选字段”可能有两种理解:可以没有这个key,或者key存在但值为null。Skill不确定是哪种,所以标记需要人工确认。
执行层:执行器遍历原语。置信度高于0.9的直接调用Postman API更新所有相关用例。置信度在0.8到0.9之间的,生成一个待确认列表,通过企业微信机器人推给我。
我的界面显示:“用户服务接口变更:影响12个用例,3个操作自动执行,1个操作需确认:nick字段应断言为null还是optional?” 我点确认,执行器完成剩余操作。
总耗时:我投入约90秒。从接口变更到用例全部更新完成,不超过4分钟。
关键是,我没有打开Postman,没有写一行断言代码。Skill甚至帮我识别出原来level和新的vip_level可能逻辑重复,建议我回归时重点关注。这是脚本做不到的。
人应该做决策,而不是做翻译。Skills-first让人从翻译变化回到判断逻辑。
落地时的三条铁律
这套模式不是拿来就能跑。我在落地过程中踩了不少坑,总结三条必须遵守的铁律。
铁律一:Skill的输出必须可审计、可回滚
Skill生成的每个操作原语都带上唯一ID,记录触发原因(哪个字段变更导致的)。执行器在修改Postman Collection之前,先把当前版本备份到Git。一旦发现误改,一键回滚。
不要相信任何AI的输出,哪怕置信度100%。有一次Skill把response.total从数字改为字符串,但实际上开发只是改了文档示例。我们增加了“交叉验证”步骤:Skill输出类型变更时,会去检查实际代码的返回类型(通过分析接口的实现代码或运行时采样)。这能挡住大部分误判。
铁律二:感知层要做“变化收敛”
接口变更可能很琐碎。一次PR可能改动十个字段,但其中八个是内部字段,对外不可见。如果Skill每次都全量更新,会产生大量无意义的操作原语,甚至制造噪音。
我们在感知层加了一个过滤器:只关注标记为@public或出现在已有用例中的字段。内部字段变更直接忽略。这个过滤器不需要AI,用简单的JSON Path匹配就能实现。
铁律三:保留一条纯手工的“逃生通道”
总有些变化是Skill处理不了的。比如业务规则完全重写,接口语义发生了根本变化。这种时候,强行让Skill去改用例是危险的。
我们的机制是:如果Skill分析出的变更涉及超过30%的字段,或者置信度普遍低于0.7,它会放弃自动生成,改为输出一份“变更影响分析报告”,建议人工重新设计该接口的用例集合。
不要神话AI。知道什么时候不该用AI,比会用AI更重要。
你现在的模式在第几代?
回到开头那个朋友的例子。他后来做了一件事:统计团队每周在接口用例维护上花的小时数。平均每人每周6.5小时。按二十个人算,每周130小时,相当于三个全职人力。
而这些时间里,真正在“思考”的不到20%。大部分是在机械地改字段名、改类型断言、改路径引用。
Skills-first不是要替代测试工程师。它想替代的是那80%的机械劳动。
读完这篇文章,你可以做一个简单的自我诊断:
打开你当前项目里使用最频繁的一个接口测试用例文件或Postman Collection。看最后十次提交记录。
- 有多少次提交是因为接口变更而修改断言?
- 有多少次修改是模式化的(改字段名、改类型、加字段)?
- 有多少次修改需要你真正理解复杂的业务逻辑才能完成?
如果前两类占比超过70%,你的项目已经具备了落地Skills-first的条件。
最后留一个具体到能动手的问题:
你现在使用的测试工具(Postman/JMeter/Karate等),它的API能支持完全编程式的用例增删改查吗?如果不能,哪一层会成为你落地Skills-first的瓶颈?
欢迎在评论区写下你的答案。我会挑几个典型的场景,在下一篇文章里给出具体的Skill实现代码。